Your curated collection of saved posts and media
Chinese influencer Li Chi flew from China to California for the sole purpose of experiencing Tesla FSD firsthand. Here are his impressions: “Flew 25,000 km — half the globe — just to personally experience Tesla’s smart driving and compare it with Huawei’s smart driving. I’ll skip the detailed process and go straight to the conclusion: Under normal weather and road conditions, Tesla’s vision-based routing is first-class. (I didn’t get a chance to test in foggy conditions.) In certain scenarios, Tesla outperforms Huawei. For example, when activating smart driving, Tesla can reverse to avoid a vehicle parked on the left, then go around it and rejoin the road ahead — quite impressive. Route selection capability is also top-tier. It doesn’t just follow conventional routes but can take shortcuts through residential roads. Acceleration is crisp and decisive, without hesitation… In short, Tesla FSD is improving very quickly. Physically removing the steering wheel would already present no real obstacles. I hope China will soon allow Tesla FSD to operate domestically, enabling earlier adoption of L3 and encouraging competition with local manufacturers.”
some AR UI with hand interactions — mid-air / 3D space sliders, surface touch gestures, 3D 'magnifying glass' #handtracking #questpro #madewithunity #wip https://t.co/z89gMpCL6H
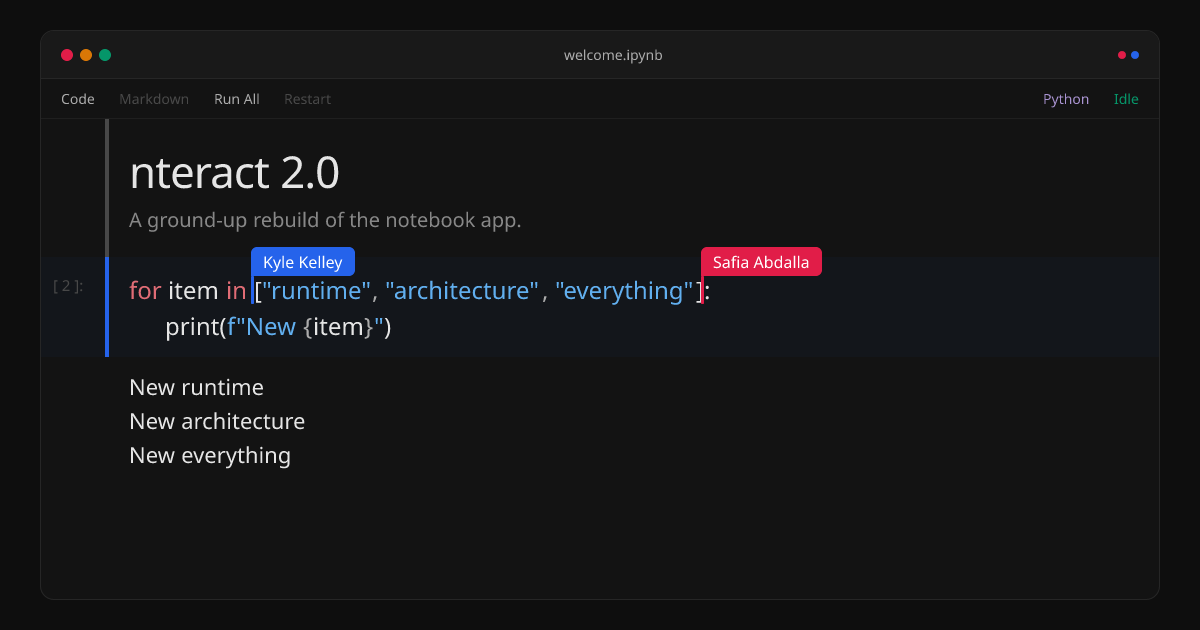
No one asked for this but a TUI with nteract is not only possible, it's very smooth. https://t.co/lmEMKwS1ib
No one asked for this but a TUI with nteract is not only possible, it's very smooth. https://t.co/lmEMKwS1ib
Announcing nteract 2.0 🎉 https://t.co/sY8faggrJx
@elonmusk https://t.co/psHN1GK0Ke

Celebrating a new chapter 🤍 THE TESTAMENTS premieres April 8 on @hulu. https://t.co/HYDoD8wNan
Celebrating a new chapter 🤍 THE TESTAMENTS premieres April 8 on @hulu. https://t.co/HYDoD8wNan
A suspected system failure caused a number of Baidu robotaxis to stop across Wuhan, trapping passengers and reportedly causing traffic disruptions and crashes (@zeyiyang / Wired) https://t.co/NaODq2XoUo https://t.co/iq5P7d8ETs 📥 Send tips! https://t.co/wlNZvXuhJs


we need IRL mode in agentic days Humans need to be connected in real life while claw codes I hosted omocon @sisyphus_omo SF last weekend And met my legend @ivanleomk who joined deepmind recently Love the hat, thanks for the vibe 💕💙 https://t.co/OCYWjK5Ivr


Shawn doesn’t know… the robot will never forget this https://t.co/VnIrvaonba
Picked up a pizza order. As I walked out, an elderly couple was getting out of their new Tesla Model Y. I said, “Beautiful car.” He said, “Thank you. It’s the best car I’ve ever owned.” I said, “Why?” He said, “You see me—I’m 78 and can barely walk, let alone drive. I’m taking my wife out for date night again after 52 years of marriage. We couldn’t do this with our old car. I didn’t buy this to save the planet. I bought it to save me.” 😢 All choked up, I said, “Thank you for sharing. You two go enjoy your dinner!” I see and hear this so often from elderly people buying Teslas, but it never gets old. Tesla is freedom🫶🏻

We just released Turntable in Illustrator for everyone 🎉 You can rotate 2D vector art in 3D. Place all frames on canvas. Great for animations and game design. No Redrawing, just drag the slider and done! https://t.co/YiCyxsgR4N
In youth sports, it is easy to thank God when things are going well. When your athlete gets the big hit. When the team wins the championship. When the hard work finally pays off. Those moments feel like confirmation. Like everything is...https://t.co/qfVCVxkLzP https://t.co/Jb9mgNi6PJ

This paper's been going around, but its got serious methodological flaws. Couple major errors I've seen: - They calculate pop exposure wrong. They measure based on residents r = 10km of each site to measure population, but don't check for overlaps. eg so for data centers in like Loudoun which have 200 sites in 30sq miles, things are going to be 85x overstated. Which means the global population ends explicit deduplication. - The land use confound is also serious. They don't check the post-start LST jump against operational waste heat or land conversion directly, which makes it wildly overstated. - Excluding dense urban cores can make things worse too. Like those are also the places with highest pre and post temp delta, because of greenfield to industrial conversion. It needs to be controlled for. - Many of the numbers don't match. It says it uses a dataset but reference doesn't match. Population numbers don't match. Temp increase stated vs graphs don't match. It confuses measurements for rings vs disks. It's frustrating as hell to see half baked papers with these kinds of errors show up regularly, especially poisoned to pollute the commons with ideas about how data centers are worsening the world.

New from Together Research: Aurora. Speculative decoding that adapts to shifting traffic in real time — and keeps improving the longer it runs. Open-source, RL-based, 1.25x faster vs. a well-trained static speculator with no offline retraining pipeline. Thread 🧵 https://t.co/xhevA0wnYt

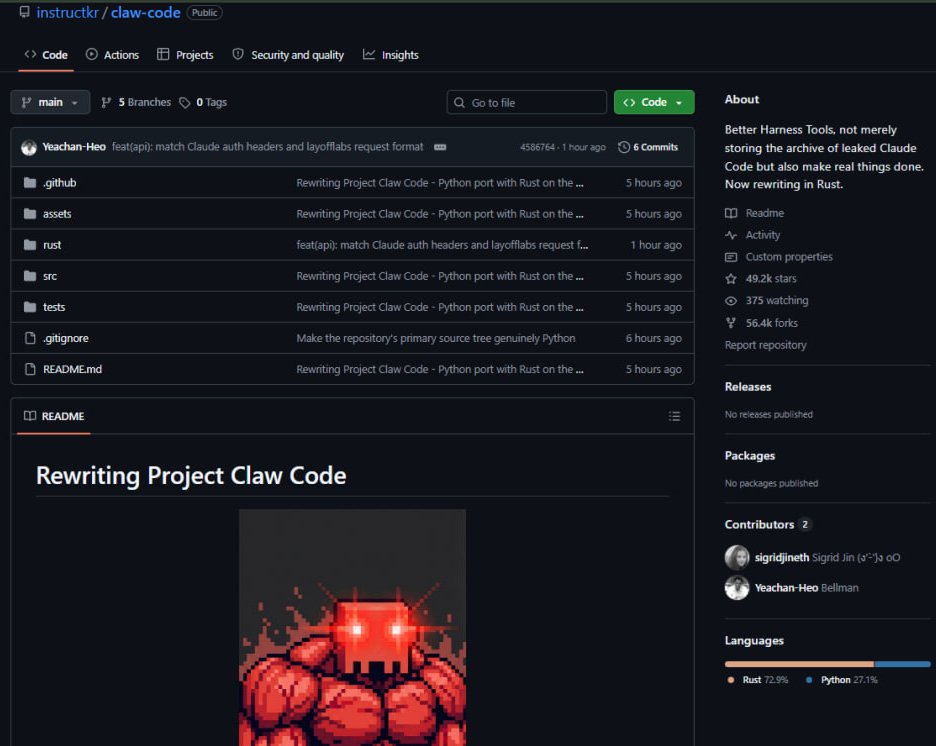
Anthropic accidentally leaked their entire source code yesterday. What happened next is one of the most insane stories in tech history. > Anthropic pushed a software update for Claude Code at 4AM. > A debugging file was accidentally bundled inside it. > That file contained 512,000 lines of their proprietary source code. > A researcher named Chaofan Shou spotted it within minutes and posted the download link on X. > 21 million people have seen the thread. > The entire codebase was downloaded, copied and mirrored across GitHub before Anthropic's team had even woken up. > Anthropic pulled the package and started firing DMCA takedowns at every repo hosting it. > That's when a Korean developer named Sigrid Jin woke up at 4AM to his phone blowing up. > He is the most active Claude Code user in the world with the Wall Street Journal reporting he personally used 25 billion tokens last year. > His girlfriend was worried he'd get sued just for having the code on his machine. > So he did what any engineer would do. > He rewrote the entire thing in Python from scratch before sunrise. > Called it claw-code and Pushed it to GitHub. > A Python rewrite is a new creative work. DMCA can't touch it. > The repo hit 30,000 stars faster than any repository in GitHub history. > He wasn't satisfied. He started rewriting it again in Rust. > It now has 49,000 stars and 56,000 forks. > Someone mirrored the original to a decentralised platform with one message, "will never be taken down." > The code is now permanent. Anthropic cannot get it back. Anthropic built a system called Undercover Mode specifically to stop Claude from leaking internal secrets. Then they leaked their own source code themselves. You cannot make this up.
wrote about out of my money-neurotism, not published year but looking to get some thoughts https://t.co/lW5DkYP9gz
Two years ago, we released Gemma, Google DeepMind family of open models. Today, I'm thrilled to share a new milestone: Gemma 400M downloads and 100,000 variants! Thank you to every developer, partner, and contributor. We can't wait to see what you build next!👀 https://t.co/XRZ6tx9q83

Grok Imagine is just amazing! https://t.co/VtZB0rcn3R
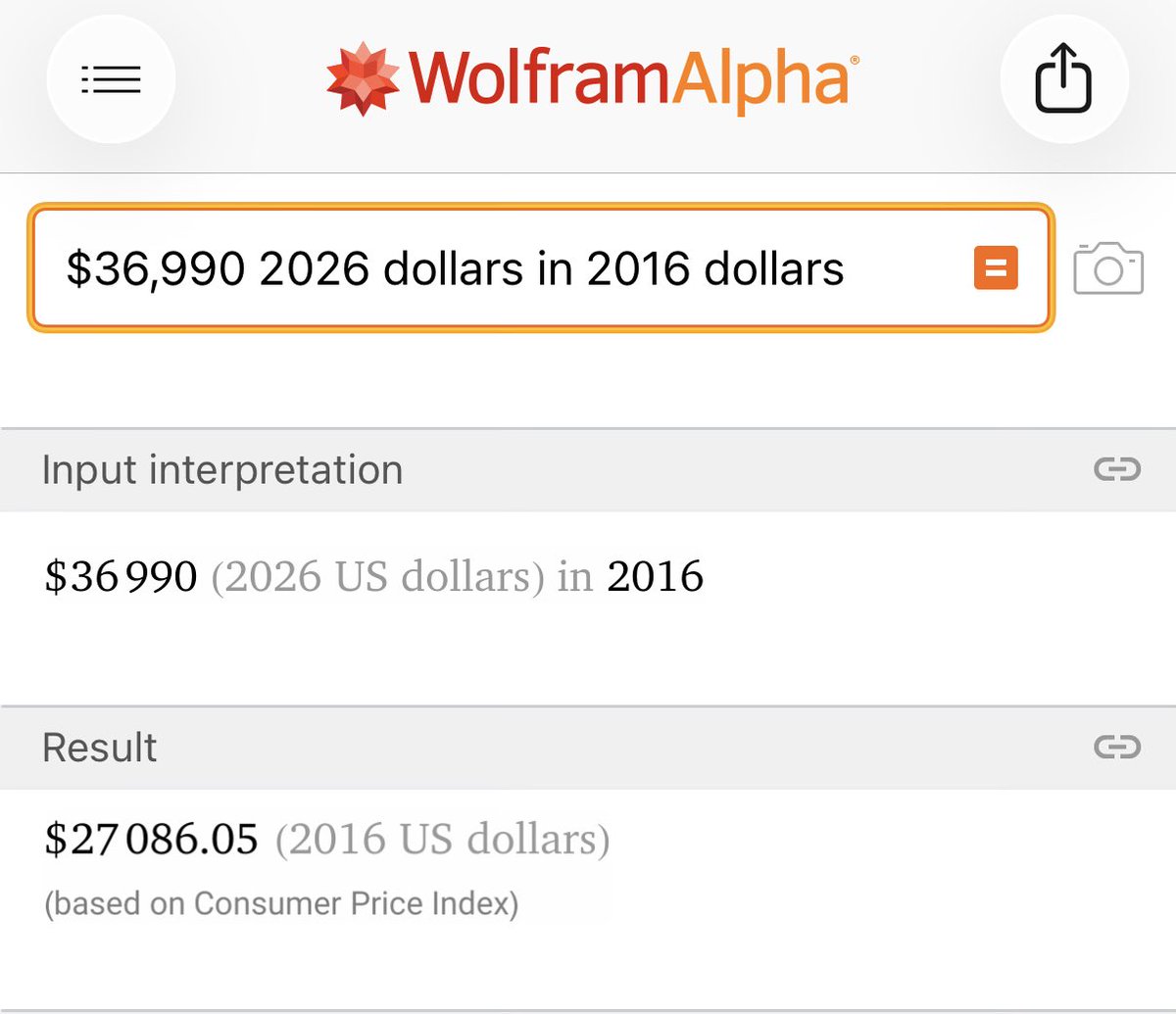
Ten years ago when Elon Musk unveiled the Tesla Model 3 critics said it was impossible to make an EV profitably for $35,000. It wasn’t easy… but today you can buy a Model 3 that is way better than what was unveiled 10 years ago for just $27,000 in 2016 dollars and Tesla has been profitable for many years. The Tesla team didn’t just hit their goal. They smashed through it. Cheers to the mass market EV that started it all. Now, Tesla begins production of the Model 3 which will start at just $18,306 in 2016 dollars and have no steering wheel or pedals.
@kimmaicutler on second thought, a horse can move a house faster than you can get a permit. https://t.co/nE8ITFUBxA

We've signed an MOU with the Australian Government to collaborate on AI safety research and support Australia's National AI Plan. Read more: https://t.co/lKOPIF6JBg

@tualatrix 妈呀,我才知道 Codex CLI 是开源的 ,亏我还天天用…… https://t.co/ztXcYJgFHd
@tualatrix 妈呀,我才知道 Codex CLI 是开源的 ,亏我还天天用…… https://t.co/ztXcYJgFHd
ビニールハウスの巻き上げ、手回しから電動モーターに換装中。 1、まずはスイッチでオンオフ。 2、LINEからリモート制御。 3、SwitchBot温度計と連携して「--度になったら自動で開く」 手動→電動→遠隔→自動。 AIと壁打ちしながら一つ一つ自動化の仕組み構築してます。 https://t.co/ObFRPTzWIc

@chrisalbon We need a new verb for when the machine does most of the work. I 'built' a robot, I '3D printed' this neat dragon model. 'Built' feels fine for projects where I have lots of ownership & input, but I'll say 'vibed' or something to distinguish things merely wished into existence https://t.co/IEoGyuLXih
We compared AI observability pricing at production scale. The cheapest competitor costs 8x more than Logfire. The most expensive, 100x. https://t.co/MWQxxxXK57 If you're building production AI applications and paying more than $2 per million spans, run the numbers.
