@polynoamial
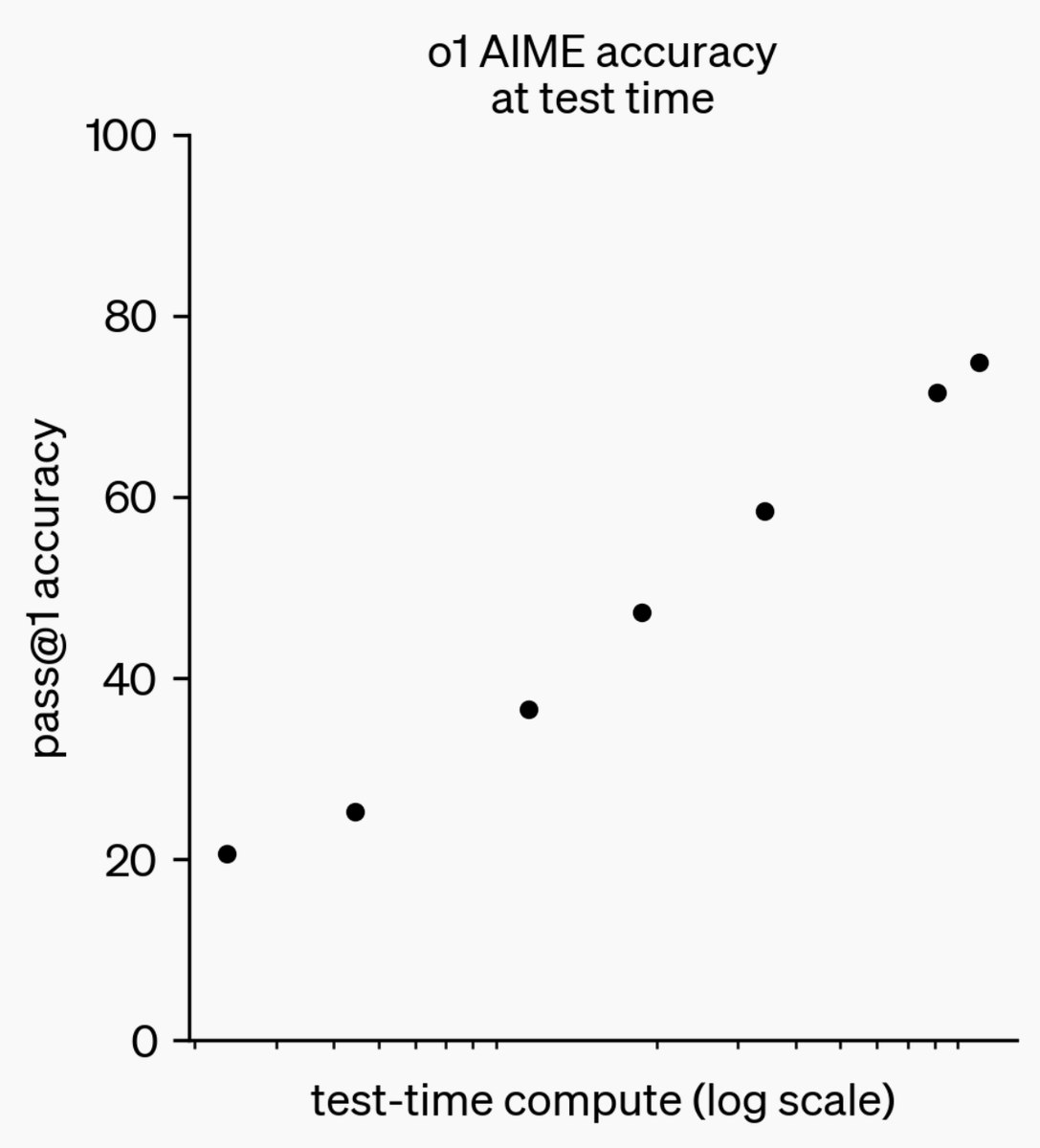
@OpenAI o1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too. https://t.co/niqRO9hhg1