@arankomatsuzaki
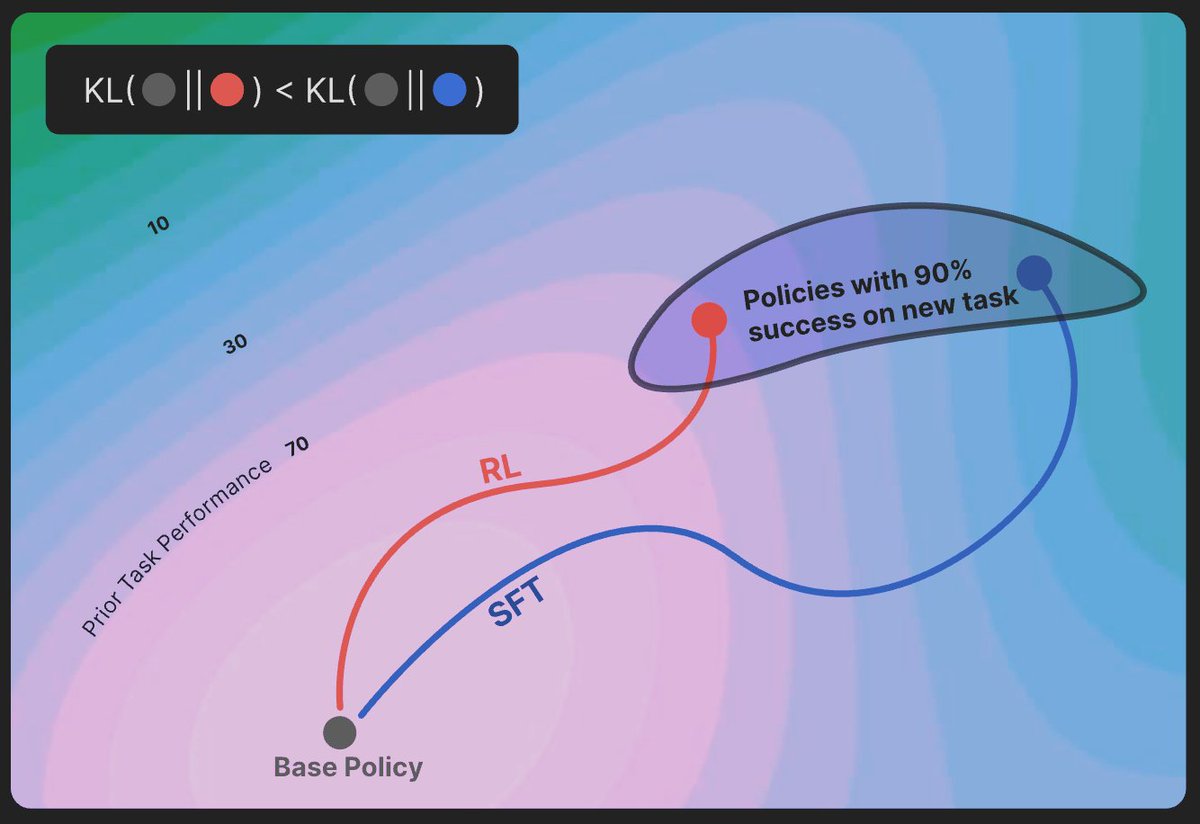
RL’s Razor: On-policy RL forgets less than SFT. Even at matched accuracy, RL shows less catastrophic forgetting Key factor: RL’s on-policy updates bias toward KL-minimal solutions Theory + LLM & toy experiments confirm RL stays closer to base model https://t.co/NGXSmcgnVA