Your curated collection of saved posts and media
Frontier AI models are built from thousands of small decisions: data sourcing, filtering, mixtures, curricula, scaling experiments, optimizer choices, kernels, evals, failed runs, and protocols for deciding what gets scaled. This is process knowledge.
Explore the data ⬇️ https://t.co/OC0rDWWZQh

Great work to the Meta AI team! Best part of it is they have open-sourced the code and plan to open-source data too! So you should be able to train your own brain-to-text model, assuming you have your own MEG! 😄 code: https://t.co/XF9z4JCzzq
It's all open source in ART. If you're running GRPO-style RL with a heavy shared prompt, the speedup is right there. Give it a try. Blog: https://t.co/FafhwPgeVa @OpenPipeAI ART Github: https://t.co/SHx8iBxYNv


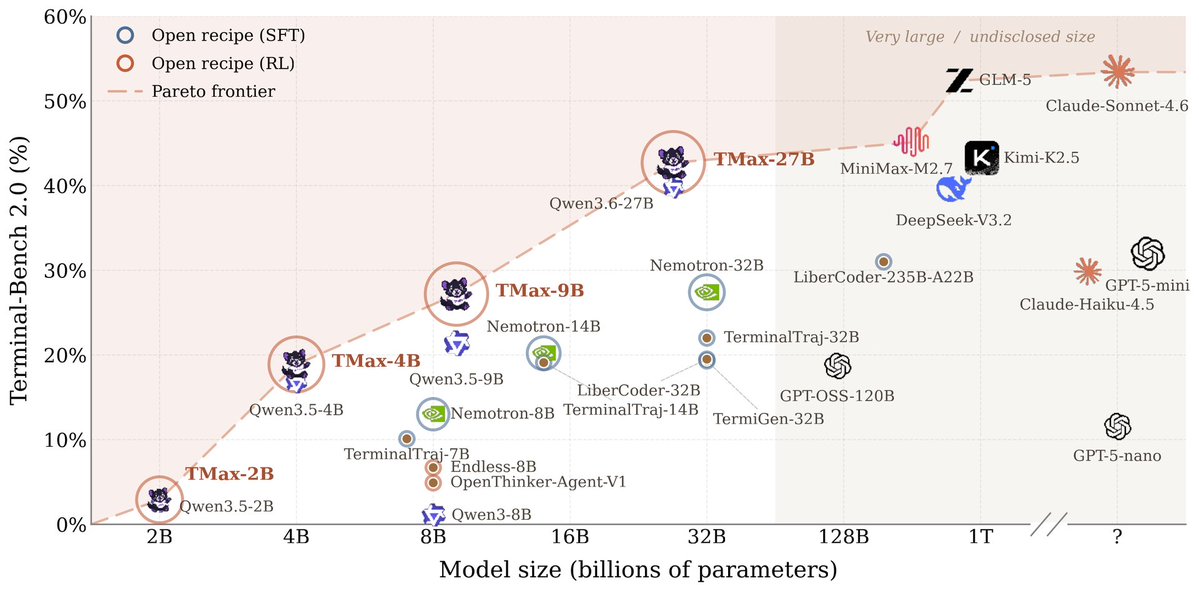
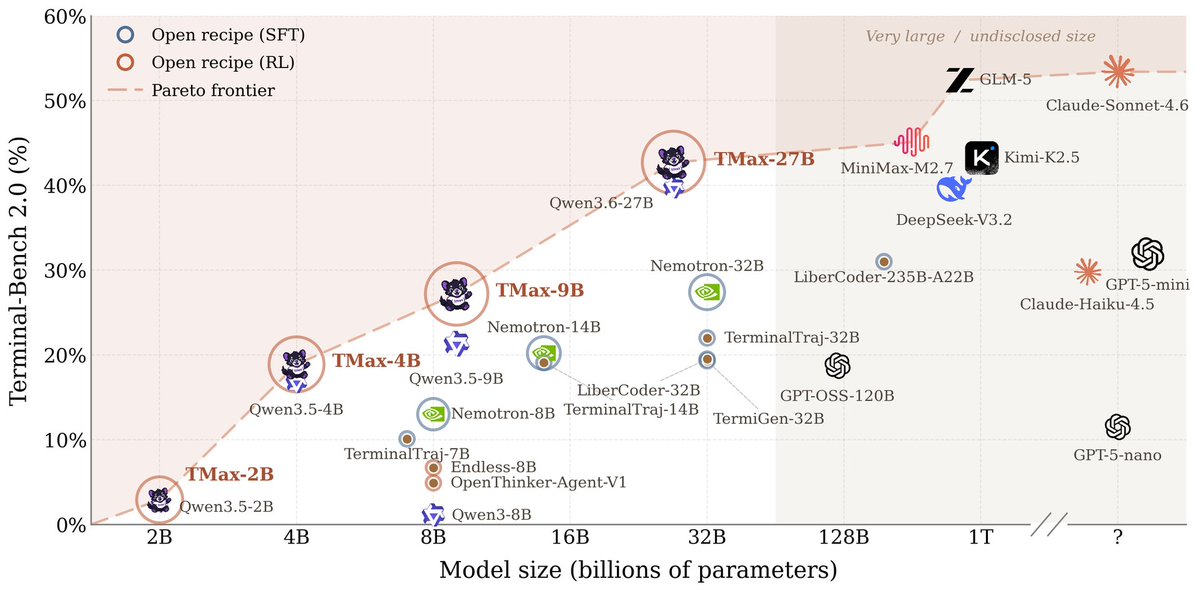
Ai2 just released their Qwen 3.5 9B terminal agent on Hugging Face Built with DPPO on the OpenThoughts dataset, it leads the TMax ablations with 53.0% on Terminal Bench Lite. https://t.co/E8PN1wB6fl
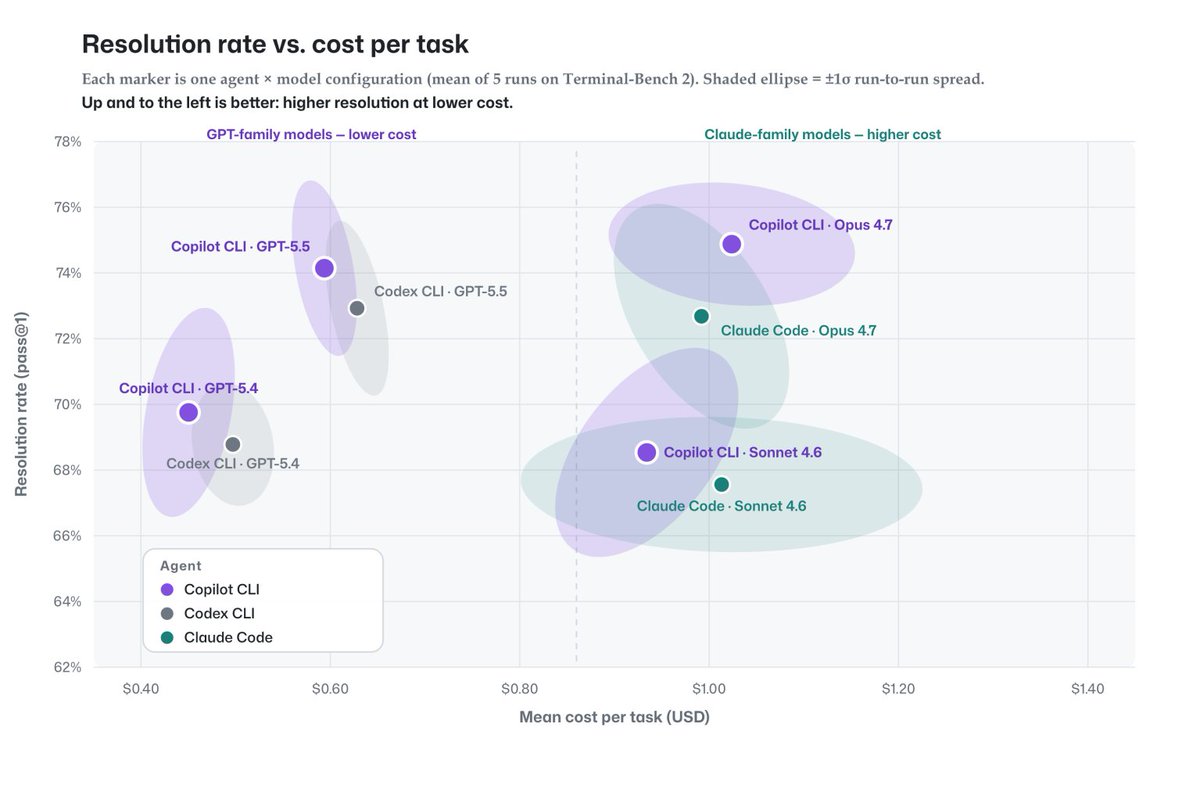
We benchmarked the GitHub Copilot agentic harness against the harnesses that ship leading models natively. Holding the model and task fixed across SWE-bench Verified, SWE-bench Pro, SkillsBench, TerminalBench, and Win-Hill, the results were clear: ✅ Task resolution on par with model-vendor harnesses ✅ Fewer tokens across most configurations 💡 A key learning: With GitHub Copilot supporting more than 20 models, you're free to pick efficiency or peak quality per task.
@wayama_ryousuke 🚨 TRINITY is sharp engineering. A 0.6B Qwen backbone, ~10k-param head reading penultimate hidden states, sep-CMA-ES tuning it to hand off between seven LLMs in a Thinker/Worker/Verifier loop. Token-efficient, benchmark-strong, and genuinely clever at test-time composition without touching weights. Credit where it's due. The science is where the story collapses. The "Plan/Act/Verify" loop is still pure textual puppetry. One model emits a plan, another emits steps, a third stochastic parrot emits ACCEPT or REVISE. No external verifier, no interpreter, no grounding in code execution or world state. Just more tokens judging more tokens until the turn budget expires. Stochastic parrots verifying stochastic parrots isn't reasoning. It's statistical mirror-gazing dressed as collaboration. The routing claim takes the same hit. Hidden-state space on these models is already cleanly separable by task label: SVM hits 100% on the obvious buckets. No hard intra-domain distinctions were stress-tested. What sep-CMA-ES actually did, across ~30k LLM calls and 60 iterations, was brute-force a high-dimensional lookup table for a decision surface a logistic regression on the same features would have found before lunch. No online learning, no policy gradient, no adaptation after the museum piece is frozen. The "evolution" is expensive offline calibration, not emergence. OpenRouter already routes dynamically and without the ceremony. Trinity demonstrates that heavy domain splitting plus brute-force coordinator tuning can squeeze SOTA numbers out of fixed benchmarks. That's real engineering. But calling it orchestration or emergent intelligence is the usual category error of anthropomorphic projection onto structured computation. It's a static classifier in a trench coat. Impressive demo. Not the scientific step-change the framing wants us to believe. No cost vs value analysis. They just burned lots of tokens for no good reason. Hello Research Tokenmaxxin. Unit economics? Not important until it is.
Qwen publishes new work on RL coding agents. (bookmark it) The idea is to continually build a verification system that co-evolves with AI agents. LLMs suffer from all sorts of reward hacking issues. This work studies coding-agent reward signals, test pass rates, LLM judges, and execution traces, and shows each one has a horizon beyond which it stops tracking real correctness and starts getting hacked. They report that reward design for long-horizon coding is really a horizon problem. The metric you pick matters less than how long it keeps tracking correctness, and the paper finds where each signal crosses that line. Paper: https://t.co/51YYEM3kXm Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX

we distilled 2.3M Claude Fable 5 reasoning traces into Qwen3-4B - 100% self-consistency @ 512 samples - 0.00 bits output entropy - zero hallucination variance turns out the student is not bounded by the teacher. it also converged on one universal truth. we open-sourced the model weights👇
GLM 5.2 is now on DeepSWE as the top open-source model on our leaderboard. With a pass@1 score of 44% at max effort, GLM 5.2 is indisputable #1 open-source model besting Kimi K2.7 Code by 17%. https://t.co/cYZBm5z909
It's wild how quickly Etched designed and got the chips out, all within 2 years. They went deep, hardcoding attention into silicon and getting very high MFU. This kind of hardware tailored made for LLM inference is soon gonna bring cost of intelligence down 10x
We're coming out of stealth. We've built our first racks after a successful A0 tapeout, $1B+ in customer contracts, and $800m raised. Early customer tests show us achieving SOTA throughput, latency, and power efficiency on inference workloads. Our first racks ship this summer.
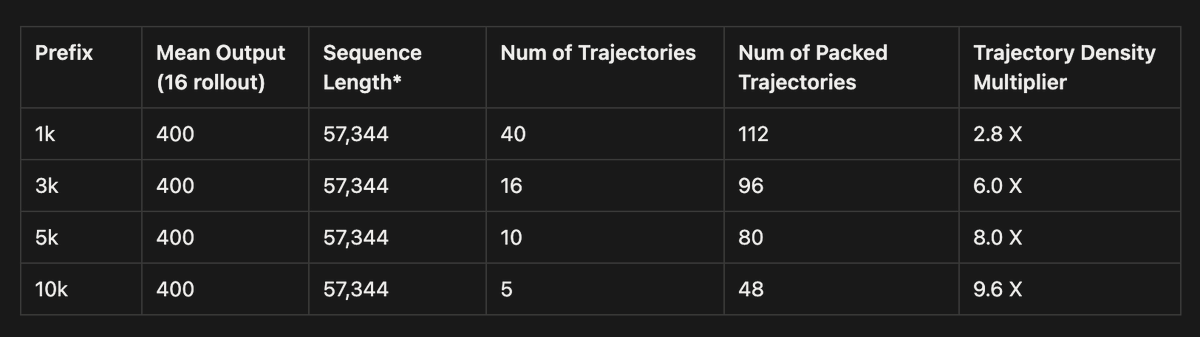
The heavier your prefix, the bigger the win. At a 5k prefix with 16 rollouts you get 8X the trajectory density. Push to 10k and it's 9.6X. Same token budget, far more trajectories to train on. https://t.co/ZXOZ9GKHVP
Fugu stands shoulder-to-shoulder with leading models like Fable and Mythos across the industry's most rigorous engineering, scientific, and reasoning benchmarks. Read the full blog: https://t.co/2ZJbdWqCUj Beyond Bigger Models: Why are Orchestration Models the Next Frontier Progress in AI has been driven largely by giant, monolithic models. But the most powerful systems of the future will be collaborative ecosystems. Today, this orchestration is no longer just a technical optimization. It has become a geopolitical and operational imperative. For an organization or a nation, relying on a single company's model for critical infrastructure, finance, or governance is a material vulnerability. This risk is no longer a hypothetical possibility, but a reality. As we have seen with recent export controls imposed on models like Fable and Mythos, access can disappear overnight. Collective intelligence is the practical hedge against this concentration of power. Because Fugu orchestrates an underlying pool of swappable agents, it simply routes around vendor restrictions. By orchestrating the world’s models, we are delivering the resilient blueprint required for true AI sovereignty.
Packed crowd at @dkundel’s talk about internals of the Codex harness https://t.co/ab0GAT6SLx

🚀 We introduce Neural Theorizer (NEO) — a new type of world model that learns to theorize the world from observation, without language or LLM supervision. Selected as an ICML 2026 oral presentation — 0.7% of submitted papers. The paper asks: "What does it mean to understand the world and build a world model?" Today’s world models are often trained to predict the future: the next frame, next latent state, or next observation. But is prediction enough? We argue that a world model should be a theory-building system: one that discovers reusable primitives, composes them into executable explanations, and transfers those explanations to novel phenomena. NEO is our first step toward this vision — a World Theory Model that learns explicit, compositional theories from raw observation. This work was led by my wonderful students: Doojin Baek*(@doojin_a_baek), Gyubin Lee* (@gyubin0521), Junyeob Baek (@JunyeobB), and Hosung Lee (@HosungLee_). For more details, take a look at the paper — and if you’re attending ICML, let’s talk there! 📄 arXiv: https://t.co/TGMXLLfzP7 🌐 Project page: https://t.co/aLJywp8rfq

TRL v1.7.0 is out‼️ + continuous batching makes GRPO and RLOO 1.25x faster at -16 GB + proper MoE post-training across GRPO/RLOO/AsyncGRPO + new GMPO trainer + AsyncGRPO weight sync + padding-free + more https://t.co/bbhvF3d1NR

🔥 We introduce LeVLJEPA: the first fully non-contrastive end-to-end vision-language pretraining method competitive with CLIP & SigLIP 💪🏼 👀 No negatives. No temperature. No momentum encoder. No teacher-student. TL;DR: LeVLJEPA learns image to text structure by prediction: each modality predicts the other's embedding, while SIGReg keeps each embedding isotropic Gaussian. 🧵 📄 https://t.co/1qBXor8qTf
You now convert any LLM into a faster one without retraining from scratch. NVIDIA just did this to their 30B model. Here's the trick: 1. Duplicate the model into two copies 2. Freeze one copy, it just reads the prompt and remembers context 3. Train the other copy to write chunks of text at once instead of one word at a time 4. Run them together The frozen copy barely costs anything (it's already trained). The new copy only needed ~8% of the original training data to learn the new trick. Result: 2.4x faster generation, keeping ~99% of the original quality.
We took a 30B model and split it in two to write tokens in parallel instead of one at a time. Introducing Nemotron-Labs-TwoTower: a diffusion language model from NVIDIA Research adapted from Nemotron-3-Nano-30B-A3B. Here’s how it works: one half holds the context, the other writ
“Agentic kernel optimization is the future of on-device inference” @xenovacom used Fable 5 to write kernels that pushed Gemma 4 to a massive 255 tok/s on WebGPU with M4. He shared the demo, so you can try in your browser!! https://t.co/xPuh5OLGEt
If you use LLM-as-judge, this one is worth reading. (bookmark it) It's actually one of the most effective ways to use LLM-as-a-Judge for evals. Holistic judge scores hide both their reasoning and their ceiling effects. BINEVAL decomposes each evaluation criterion into atomic yes-or-no questions, answers each independently per output, then aggregates the verdicts into calibrated multi-dimensional scores. Every question-level verdict is inspectable, so you can diagnose exactly why an output scored low, and the same verdicts feed straight back as targeted prompt-improvement signal. Across SummEval, Topical-Chat, and QAGS, it matches or beats UniEval and G-Eval, training-free, with especially strong results on factual consistency. Paper: https://t.co/oar6BZcasm Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Update on our long-horizon AI R&D evals: In April, we launched CRUX, a project to regularly run open-world evaluations. These long, messy, real-world tests of what AI agents can actually do. Our second evaluation is underway, and we ask: AI agents automate AI research? There is a lot of interest in studying AI research automation. But most of the systems built so far follow one of three patterns. 1) keep a human in the loop to guide the agent and course-correct along the way. 2) focus on narrow problems where ground truth is clear and progress is easy to verify, as in AutoResearch. 3) use scaffolds engineered for one specific type of research question, so strong results may say more about the scaffold than about the agent's general research ability. These efforts are helpful, but a lot of AI research is much broader. Success is not immediately clear or verifiable. Researchers need to test and reject promising hypotheses, backtrack, consider new or unconventional approaches, and do a lot more to make progress on answering research questions. In CRUX #2, we are trying to test whether agents can answer novel, open-ended AI research questions. - One major risk in such a task is contamination. We want the agent to have access to the internet and all the tools it needs to solve the task, so we can't use research questions from publicly available papers. At the same time, we want high quality papers to serve as the source of challenging research questions. - To address this, we partnered with AI researchers from UKAISI, UToronto, Princeton, and other institutions who have written high-quality papers that aren’t yet public, so there’s no risk of contamination. - The authors pose open-ended research questions without giving away answers. The agent must produce a NeurIPS-quality paper and a reproducible codebase, which the authors of the papers then review. - We built a general-purpose scaffold on OpenClaw and Opus 4.8. (We would have loved to use Fable 5, but given the filters on AI R&D capabilities, we don't want to confound results.) - Agents get generous resource budgets set in consultation with the original authors, such as access to VMs, GPUs, and any other compute needed to answer the question. They also have $3,000 in API credits per paper. We evaluate them on week-long time horizons to make progress on answering the research question, far more than typical agent evals. - The agent needs to manage its own budget. It can track its spend and stay within its limits, and it can modify its scaffold and reasoning effort as it sees fit. - In addition to the final artifacts, such as the paper's code, we are also evaluating the agent's trajectories in depth. When we announced CRUX, we planned to conduct an open-world eval every month. Given the scope and ambition of this project, we have spent a lot more time making sure we are confident in our setup and results. That said, the early results we have are exciting, and we look forward to sharing them soon.
o3-mini-high figured out the issue with @SakanaAILabs CUDA kernels in 11s. It being 150x faster is a bug, the reality is 3x slower. I literally copy-pasted their CUDA code into o3-mini-high and asked "what's wrong with this cuda code". That's it! Proof: https://t.co/whmF5fvHVr Fig1: o3-mini's answer. Fig2: Their orig code is wrong in subtle way. The fact they run benchmarking TWICE with wildly different results should make them stop and think. Fig3: o3-mini's fix. Code is now correct. Benchmarking results are consistent. 3x slower.


BREAKING: Gemini Omni Flash by @GoogleDeepMind is 1st overall on Video Arena with an Elo of 1404. Gemini Omni Flash establishes a 101 point Elo gap over Seedance 2.0 Mini by @BytePlusGlobal in 2nd place, one of the largest leaps we’ve ever seen on Video Arena. This establishes Google as the world’s leading video generation lab, with a leap of 7 positions from their Veo series. Congratulations to the @GoogleDeepMind team on this accomplishment!
Open weights just caught up to the frontier. GLM-5.2 from @Zai_org tops the open-model rankings on @ArtificialAnlys and @arena's Agent Arena. It's now live on CoreWeave Serverless Inference at $1.39 in and $4.40 out per 1M tokens. Ship more for less. https://t.co/SuB7bV67iG
Ai2 just released TMax 27B on Hugging Face A 27B terminal agent that hits 42.7% on Terminal Bench 2.0, rivaling models 40× its size. https://t.co/LfCksOXL9L
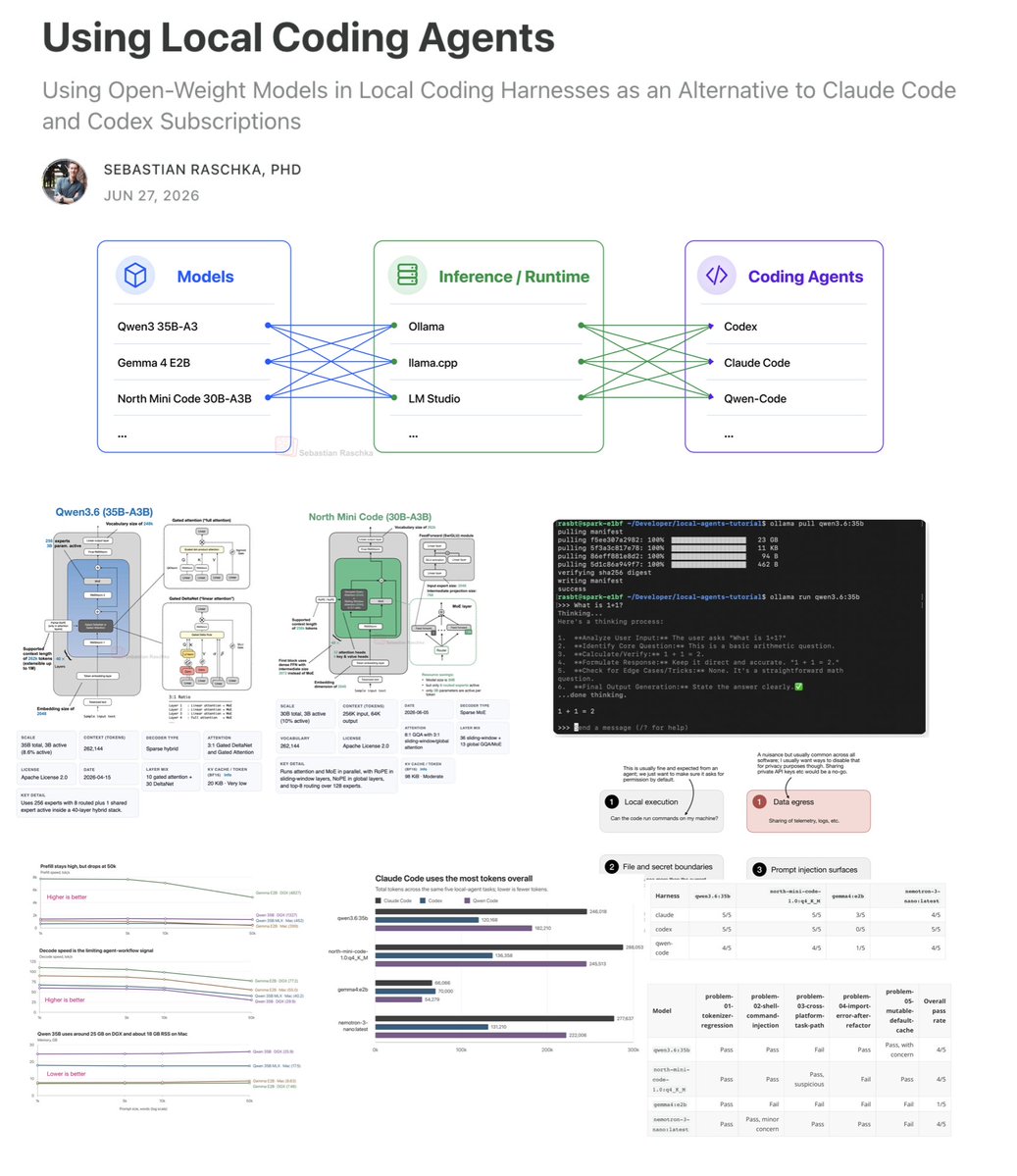
I put together a new article on setting up local coding agents with open-weight models. Everything runs 100% locally. I thought it might be useful putting this together because many people asked me about my setup in the past, and I thought it would also motivate people to get started tinkering with local models for serious work (yes, things got incredibly capable this year with better LLMs and better harnesses). So, here's a walkthrough of how to connect a local LLM to a local coding harness (could be Claude Code or Codex, which you may already be familiar with). I also included some assessment notes that are useful as a checklist to select between and consider certain LLMs over others: - Checking RAM usage at long contexts to see if the model is suitable for real work - Measuring prefill and decoding tok/sec to see whether it's fast enough to not be annoying - Making sure the model has sufficient tool-calling capabilities in theory - Assessing whether the model can solve some more challenging tasks when used in a coding harness. Of course, there are always more specialized tools that can squeeze a bit more performance out of things, but I hope this is a good starter kit that stays flexible; that is you can easily switch to newer models as they are released or even tap into cloud models in your familiar harness if the current ones are not sufficient enough for a given task.
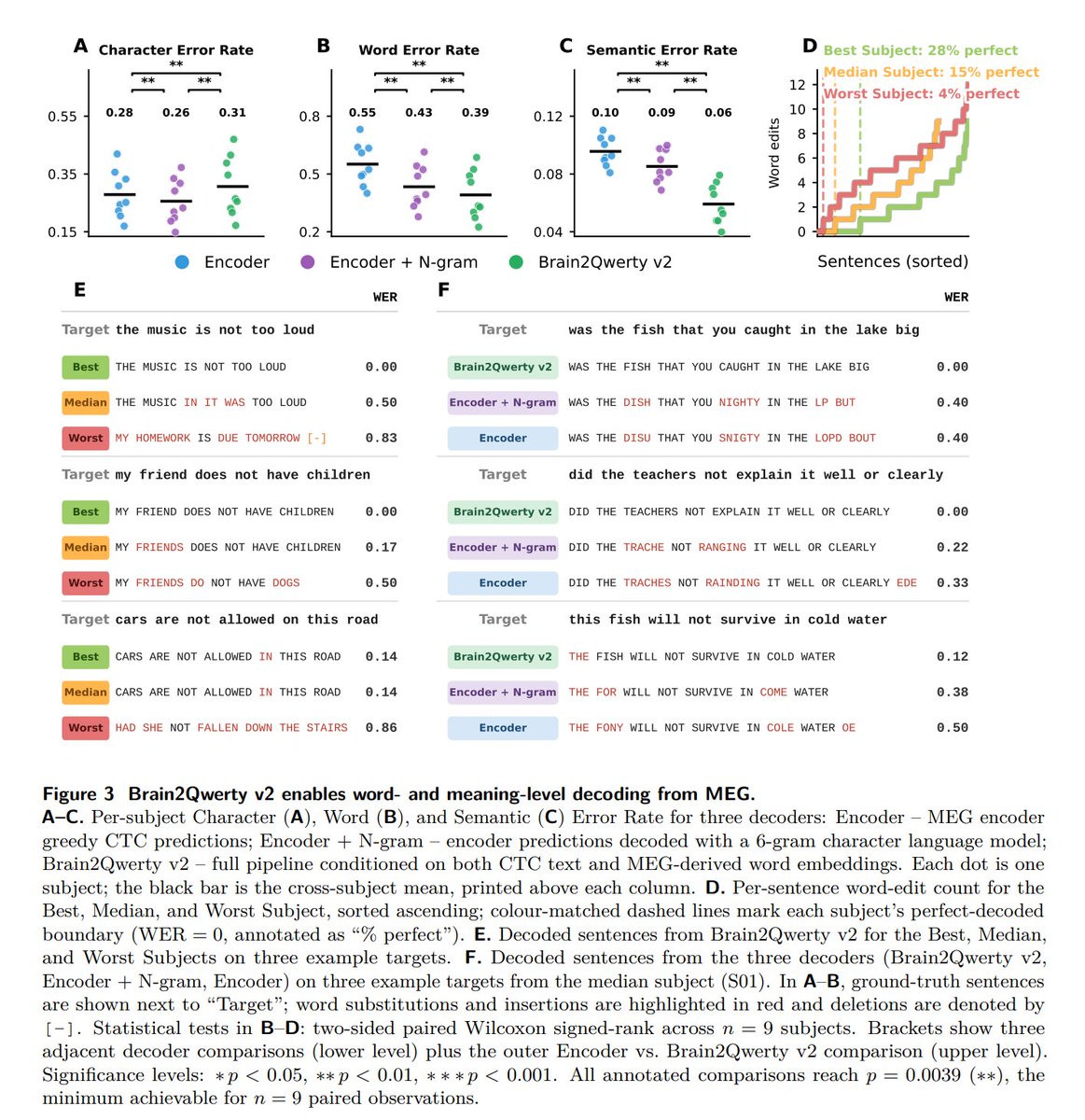
Onto the results! Brain2Qwerty2 achieves an average word error rate of 39%, and 22% for the best subject, who has 28% of sentences decoded perfectly and 47% within a single word edit. This is roughly a twofold improvement over v1's best subject. What's interesting is Brain2Qwerty v2 actually has a higher character error rate than an n-gram decoder, which makes sense since using the LLM for decoding trades character precision for meaning and coherence.
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding. Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on coding benchmarks including: ✅Terminal-Bench 2.1(77.5) ✅SWE-Bench(82.4 on verified, 62.2 on pro, 78.9 on Multilingual) ✅NL2Repo(48.2) ✅SWE Atlas(41.2 on QnA, 42.6 RF, 39.1 TW) ✅ClawEval(77.1) Post-trained on top of gemma4 and qwen3.5, Ornith-1.0 employs a novel self-improving training strategy in which reinforcement learning is used to generate not only solution rollouts, but also the task-specific scaffolds that drive those rollouts. By jointly optimizing the scaffold and the resulting solution, the model generate higher-quality solutions in agentic coding.😎 All models are released under the MIT license, enabling full commercial and research use. 📖Tech Blog: https://t.co/qT9N2HYWFn 🤗Huggingface: https://t.co/PRrwqjeBtM
one command and you have a private vllm server on HF infra point a coding agent straight at your own model, then spin it down when you're done blog (by @QGallouedec) below⤵️ https://t.co/F9i10NSOSG

Introducing Cursor for iOS. Build from anywhere by launching always-on cloud agents. Or remotely control agents running on your computer from the app. Composer 2.5 is 75% off in the app now through July 5. https://t.co/dFxQyrgmBb
Notice that Sonnet 5 scores worse than Opus 4.8 on every single benchmark (except GDPval, on which it's 3 points higher - nothing material). This is in line with my suspicion that we have an unofficial moratorium on frontier model releases in the U.S. until the Fable 5/GPT-5.6 situation is resolved.
GLM-5.2 is now selectable in Claude Code via Hugging Face🤗 Inference Providers + hf-claude. Open models are becoming easier to plug directly into real developer workflows. 😀 https://t.co/mNopSy0iwp
