@jerryjliu0
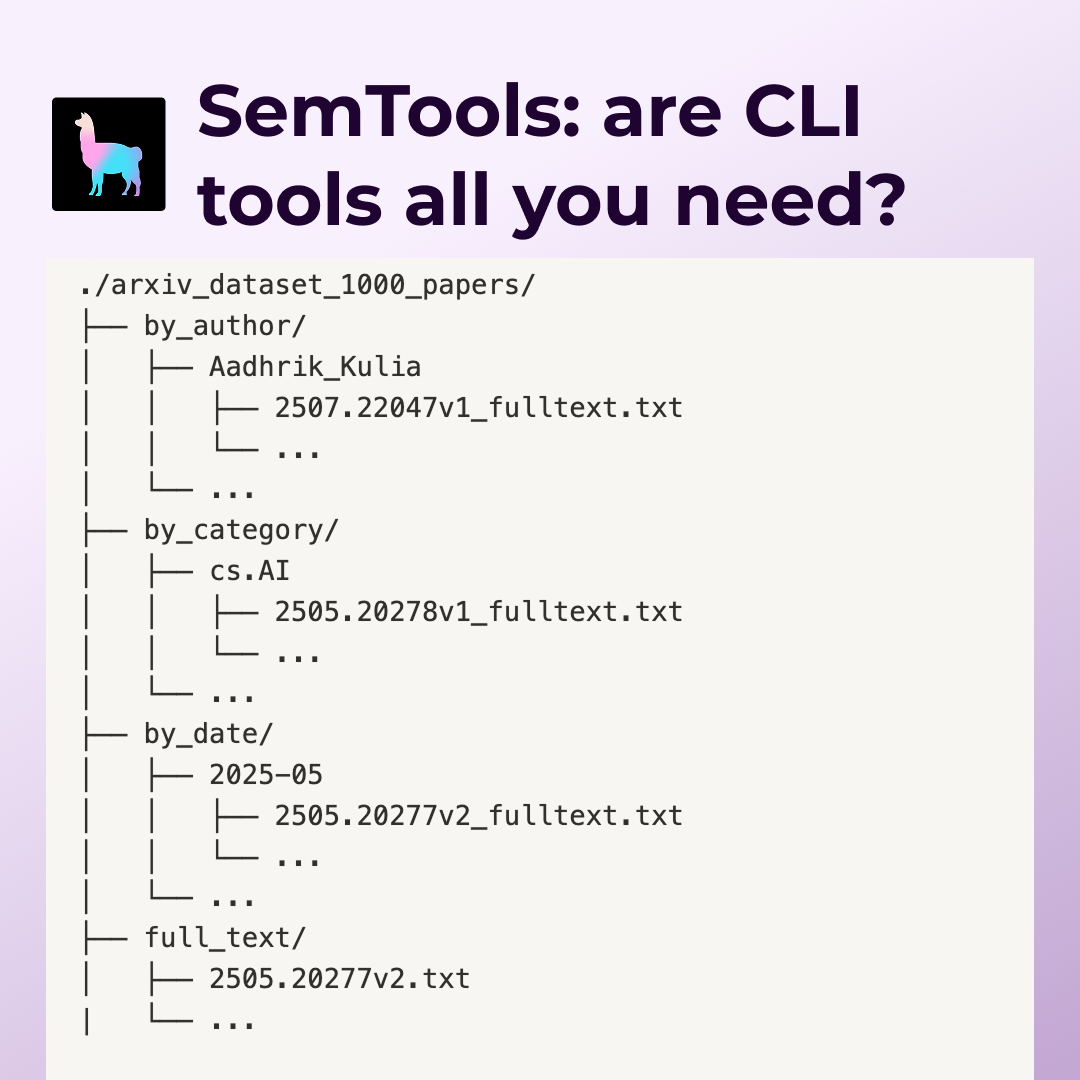
grep (and lightweight semantic search) are all you need 🤔 When you have a “medium” sized dataset e.g. 1000 ArXiv PDFs, we found that an extremely strong Q&A baseline is just giving agents access to the CLI, along with some tools for fast semantic search using static embeddings. These agents can answer complex questions, from simple search/filter with keywords, to those that require cross-referencing across docs, to those that require analysis across time. In these cases standard RAG with fixed top-k retrieval is strictly worse. We made file understanding + semantic search very CLI accessible through semtools, come check it out! Blog by @LoganMarkewich : https://t.co/kYr8KkWLYR SemTools: https://t.co/xg1iqbghIr