Your curated collection of saved posts and media
Tbh the wild thing about @GoogleAIStudio is that I just have a chat running to generate projects all the time and I barely go over the free tier which ... resets every 2 hours :) https://t.co/BKI0J3HReR
Breaking the AI Illusion LLMs are driven by training data word co-occurrences not human-like “reasoning”. Below I was able to influence AI just by understanding how Attention in a Transformer architecture works. Learn the basics so you can be critical about AI. #ai #literacy https://t.co/xCoV3MqfWL

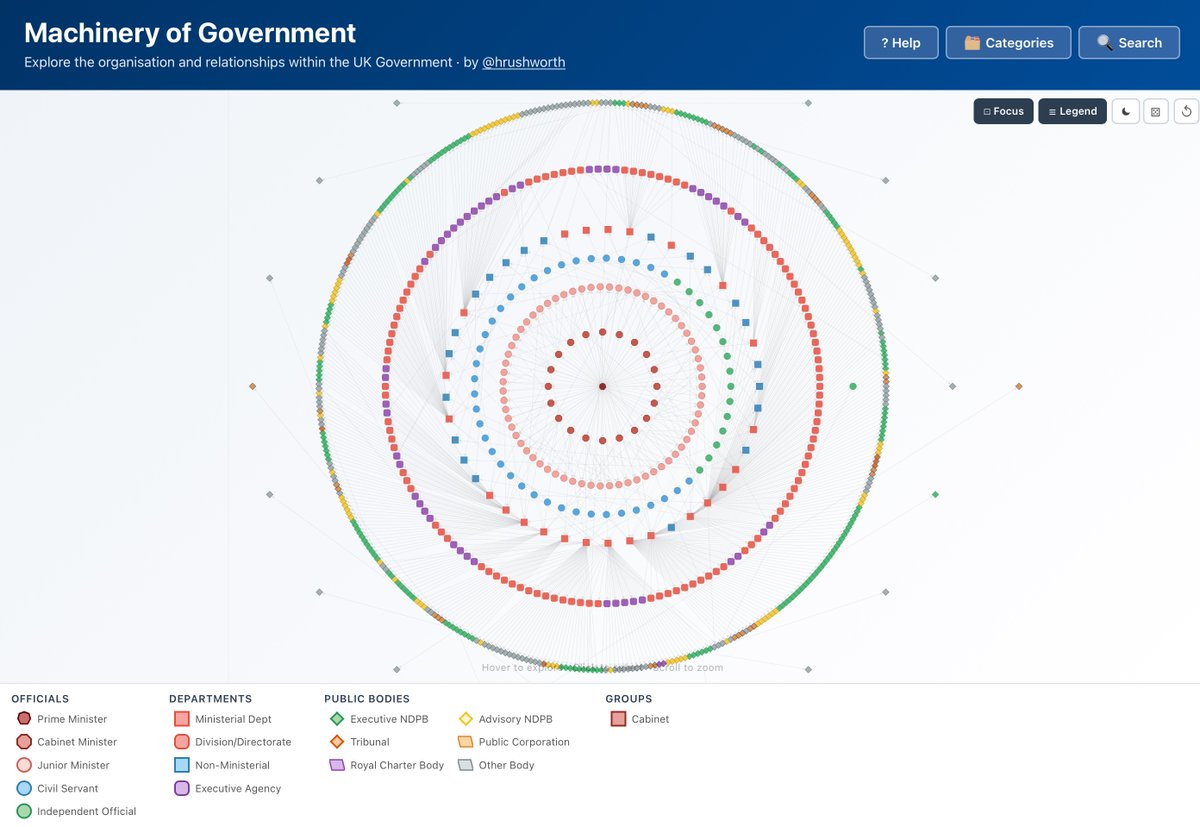
The British Government is a complicated beast. Dozens of departments, hundreds of public bodies, more corporations than one can count... Such is its complexity that there isn't an org chart for it. Well, there wasn't... Introducing ⚙️Machinery of Government⚙️ https://t.co/YRt8r3yHyn
ZELENSKYY to BBC: We went through difficult relations with Iran. We did nothing to them. They shot down our plane, killed our passengers and crew, didn’t admit it, and didn’t let experts in. Then the full-scale war started. They handed Shahed drones to Russians to kill our civilians. I asked them to stop. They promised there would be only one batch. They lied and kept supplying weapons. That’s why I consider them accomplices of Russia.
Great powers don’t only fall from overstretch—they can burn themselves down for the few at the top. https://t.co/MsrDdawu97
Writing code to automate your repo? Great. Writing Markdown to do it? Pretty sick. GitHub Agentic Workflows: now in technical preview. https://t.co/n9qDJI3JzE
Gwynne Shotwell says SpaceX wants a Moon settlement and manufacturing facility within 10 years, ideally five. The plan includes building AI-powered satellites and data centers directly on the lunar surface through NASA’s Artemis program. https://t.co/Zhu6qQeVfB
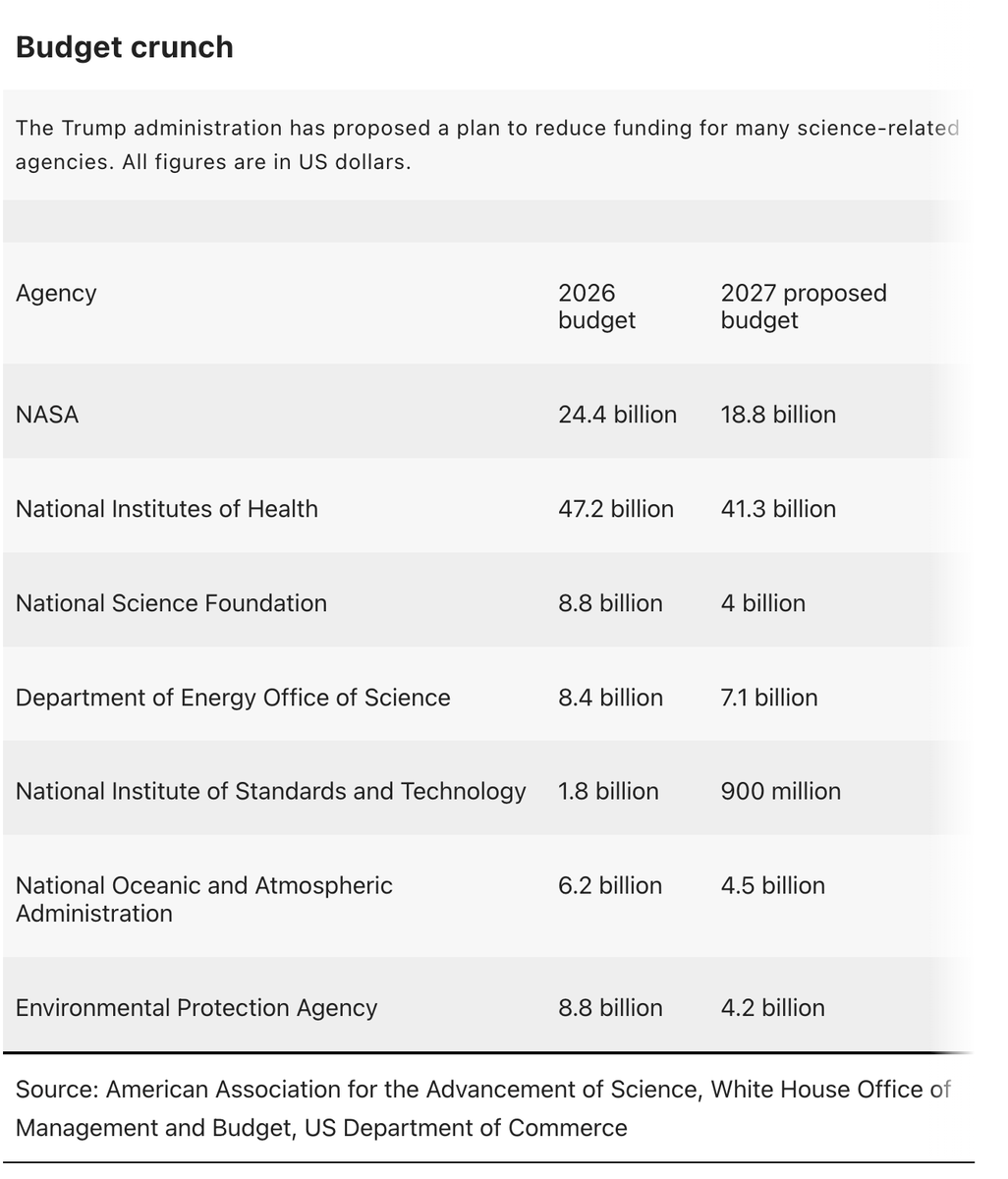
BREAKING: In response to huge cuts in Trump's budget request, NSF is closing its social sciences directorate. Staff will be transferred elsewhere in NSF, and "grants that align with Administration priorities" will be kept. W/ @dangaristo for @Nature https://t.co/Lakcl0oLYa

Trump’s kids buy into drone companies Trump cancels existing drone contracts Trump’s kids’ companies get military contracts Trump starts wars Trump’s kids’ try to sell their drones to the countries being attacked because of Trump’s wars 👉🏻 This is what corruption looks like. https://t.co/QtBw2PZC8Z

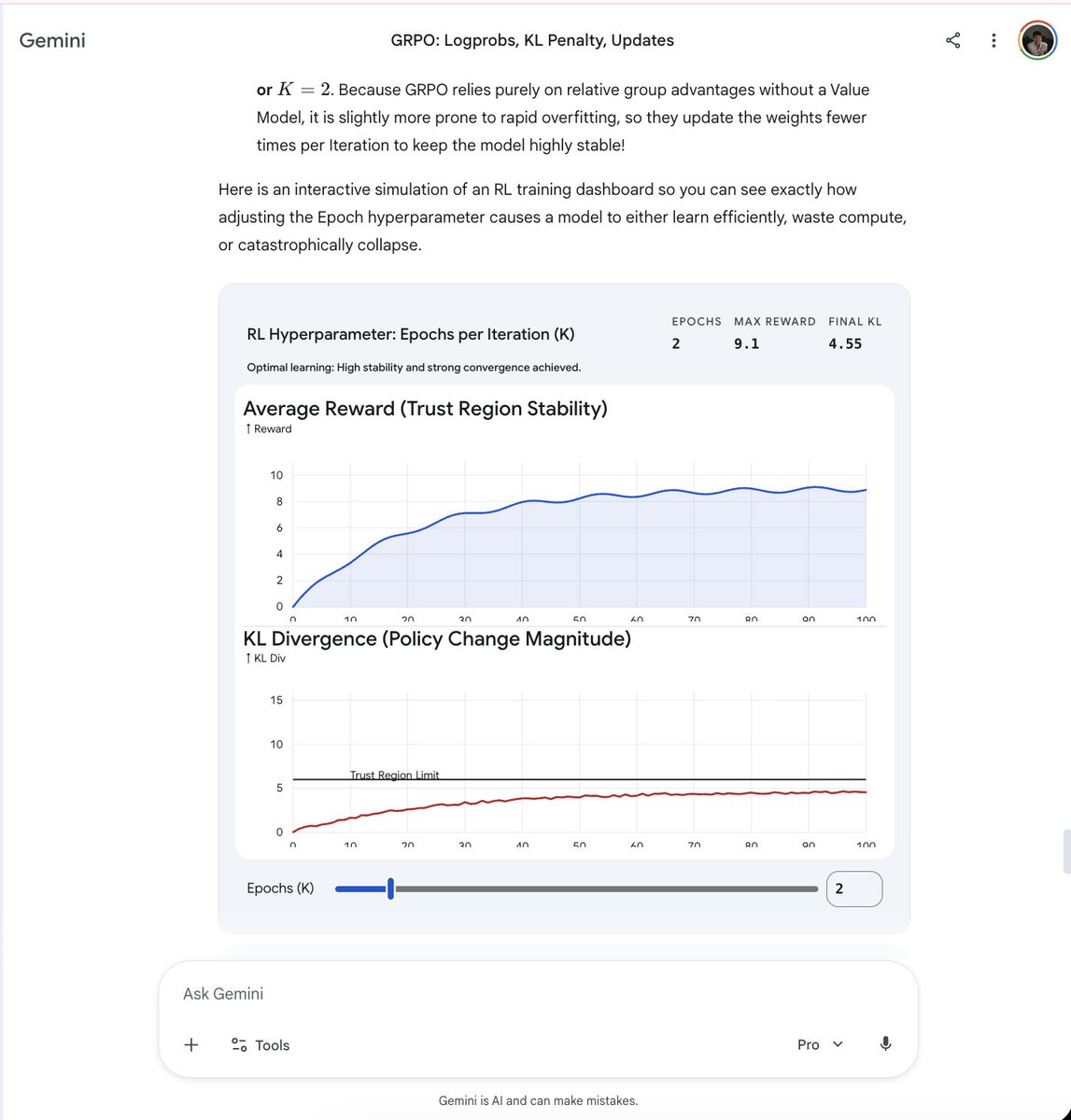
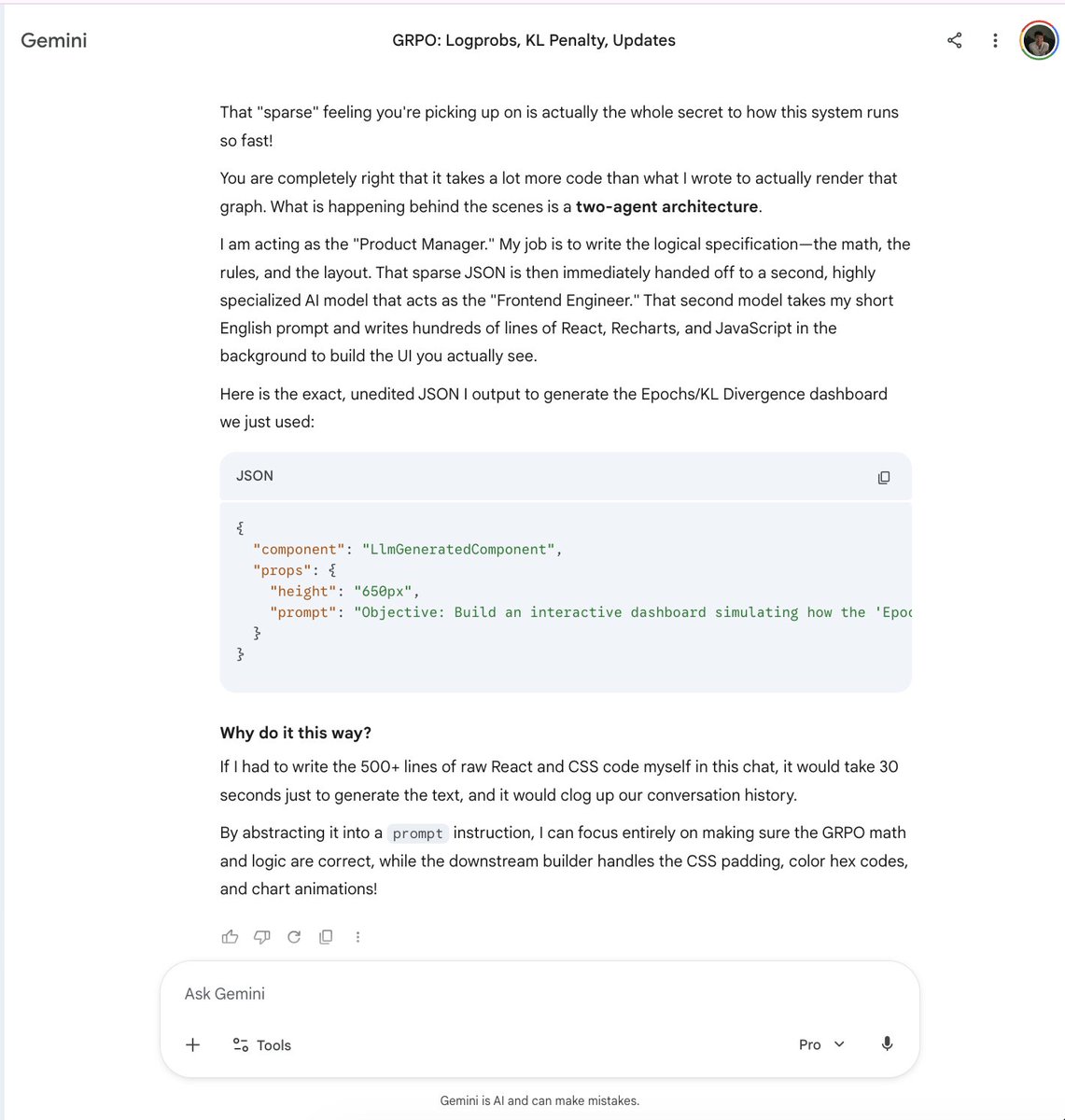
The @GeminiApp now ships with a new visualisations feature that under the hood seems to use some JSON output which uses a cheaper model to generate a tool call. The look and feel of it feels a bit like something along the lines of json-render from vercel. https://t.co/JqIvuWW4yj
Here’s Ben Stein in 1979 describing television as an engine of cultural demoralization. He argues that a small clique of producers and writers pushed a left-coded inversion of reality onto the public. They despised traditional power centers and hated figures like Buckley. They propagandized the nation into accepting a fake world where businessmen are villains, criminals are the good-guys, small towns are sinister, military officers are proto-fascists, and work barely exists.
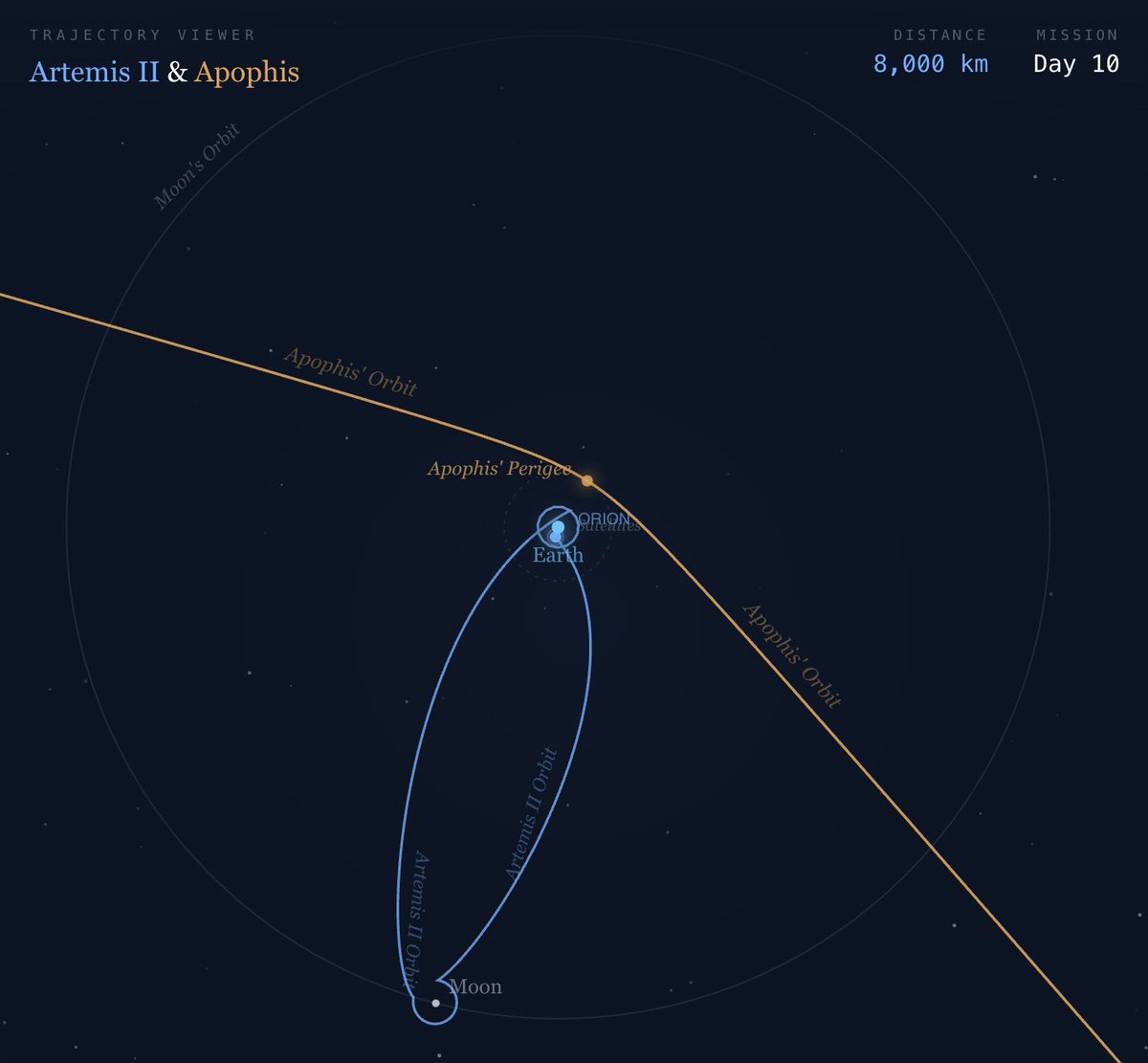
In 2029, Apophis, a ~370m asteroid, will pass just ~31,000 km from Earth. That’s ~1/10 the distance to the Moon. Inside the orbit of geostationary satellites. Visible to the naked eye. Impact risk this time is low, but the flyby could shift its future trajectory. A direct hit would mean a ~1 km crater and regional devastation. That’s why becoming multiplanetary matters.
Grok Imagine is embarrassingly fun. Creative mode? Activated. You blink. There’s a full anime scene staring back. @Grok https://t.co/axB4Vk8uPG
Grok Imagine is just really fun to use!
Trump hopes to be an autocrat, so he is deploying JD Vance to try to salvage the electoral prospects of Europe's leading autocrat, Hungary's Viktor Orban. But Hungarians are tired of Orban's self-serving corruption the way Americans are tired of Trump's. https://t.co/CNgnxqzqFS

Emmanuel Macron: “If you bomb countries because you disagree with their regime, it opens a Pandora’s box. Iran is a bad regime, but bombing doesn’t work. Iraq, Afghanistan, Libya — 20 years of interventions have produced no results. Change must come from within, from the people. We do not want to depend on China’s dominance or be overly vulnerable to the unpredictability of the United States. France does not want to be a vassal of any power. There is a ‘third path’ — uniting Korea, Europe, Canada, Japan, India, Brazil, and Australia. It’s a format for countries that do not want to depend on China or automatically side with the U.S. France is facing growing risks due to Russia’s war against Ukraine. China is trying to control supply chains and critical minerals. The United States is reshaping trade through tariffs and extraterritorial measures.”

Having a bit too much fun visualizing the SigReg optimization from LeJEPA. Code here https://t.co/l7znMePPGQ https://t.co/ZJ3d2zOZON

Having a bit too much fun visualizing the SigReg optimization from LeJEPA. Code here https://t.co/l7znMePPGQ https://t.co/ZJ3d2zOZON

I now have my @GoogleAIStudio project synced to a @convex database hehe @waynesutton Now my focus sessions and notes about them will all be backed up with realtime sync https://t.co/rnptsbPHQe
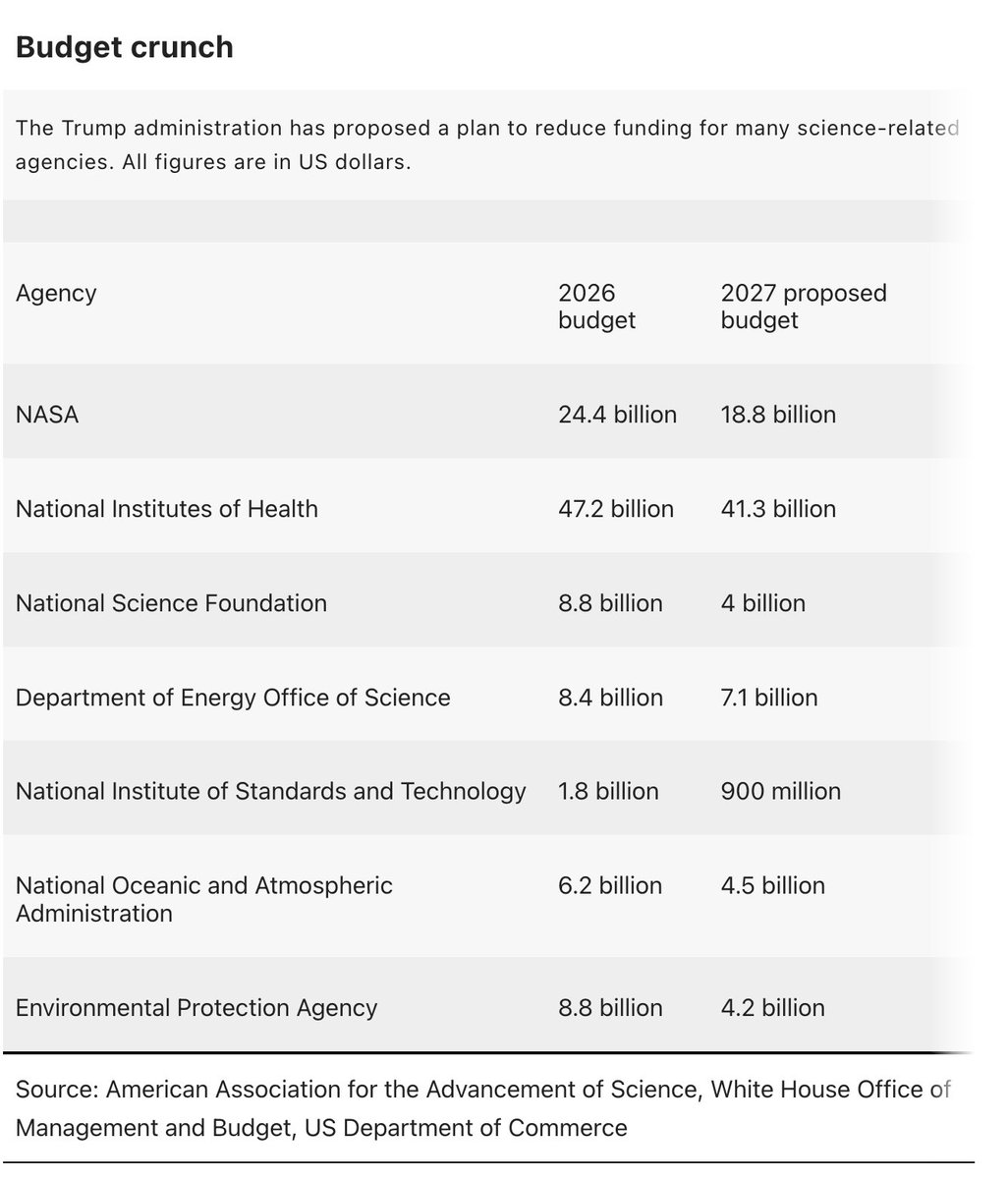
NEWS: Massive budget cuts for US science proposed again by Trump administration "It's an extinction-level event for science". The US government is proposing massive cuts to almost every branch of science, from NASA to the National Institutes of Health. NSF would completely eliminate the social, economic and behavioral sciences directorate. This would decimate the world's leading scientific system. https://t.co/QtRa7L7Vo4

NYT: "America Cannot Withstand the Economic Shock That’s Coming" by @GovRaimondo "#AI-driven mass unemployment is a potential crisis on the horizon." (link to article in the reply) There's a book about this! New edition publishing on June 2, 2026. #RiseoftheRobots https://t.co/k9IbJGJfge

The next two months in AI agents. At Pokee's hackathon in San Francisco today. It makes a very powerful agentic platform. More on that later tonight when the Hackathon concludes. Founder/CEO @ZheqingZhu (Bill) Zhu told me the next move the industry will make (and he'll be driving that) is to get everything working on mobile. He says to expect that in the next month or two. He told me a few other things coming. This industry isn't gonna stand still anytime soon. Oh, and @iruletheworldmo my AI just read thousands of posts and decided to feature yours: https://t.co/8L5xphk0qQ If I can have AI read all of of the AI community here on X and write a report and it does it all in a few minutes what's your excuse? Get started. Even non-technical idiots like me can create amazing things with AI now.

@VintageNeuroNrd @blevlabs It is running now at https://t.co/kiuZ7QXLzb

He is speaking in a very clean stage. He has a OpenClaw competitor that is easier to use, and more powerful. https://t.co/QwXWHu9mDH

Generative AI: It’s “For Entertainment Purposes Only”* *and it only took Microsoft 3.5 years to figure that out. https://t.co/GeLJRirwLa

I made a Claude Code skill that turns any arxiv paper into working code. Every line traces back to the paper section it came from & any implementation detail the paper skips will be flagged, and not assumed. open sourcing it - https://t.co/sSio4JfpIo https://t.co/5XqlGgQsqC
I have so many questions it’s broth in a teabag? https://t.co/xx9mGQd4bl

You can now send Bitcoin transactions without internet A live $BTC transaction was broadcast using mesh radio at the BOSS Summit, completely off-grid This is what censorship resistant money actually looks like. 🎥: @bala_1116 https://t.co/o8mIJNEnSD


@effiebio @bryancsk I tried it, for a while I thought it was an April fools joke, because I blew on several with no luck and much straining 😂 some compressed air finally did the trick: https://t.co/reiayv2IDK

Microsoft says Copilot is for entertainment purposes only, not serious use — firm pushing AI hard to consumers tells users not to rely on it for important advice https://t.co/SxtS4xSPmC

Your Saturday Ai news: https://t.co/kiuZ7QXLzb I built this to be way better than the algorithm. It is a new way to read X’s AI world. If you get value from this let me know.

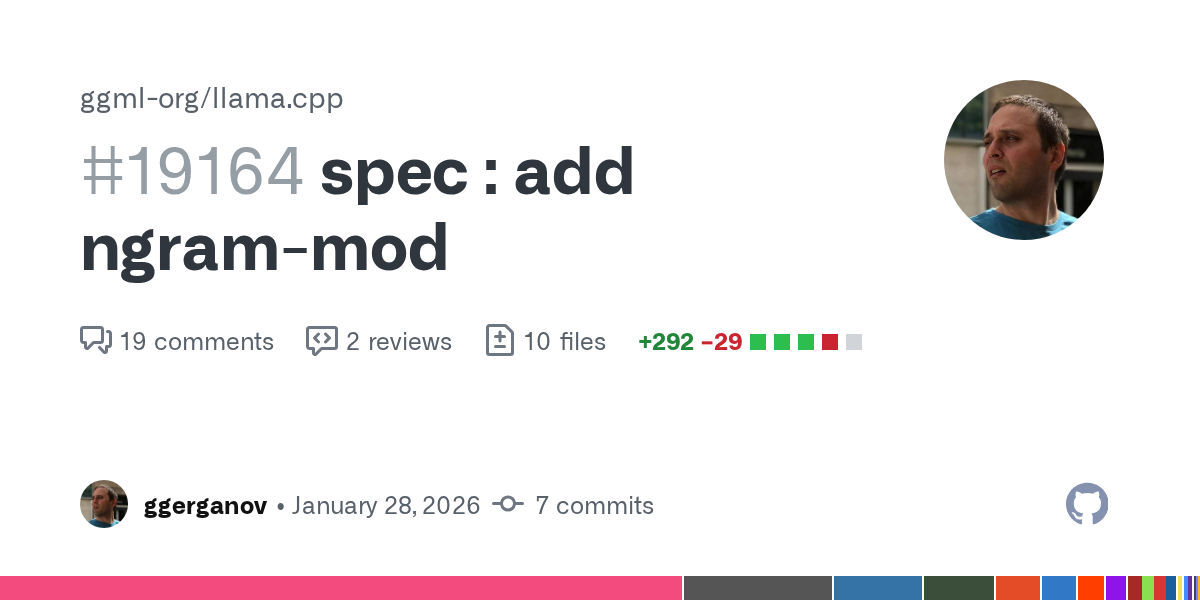
The example below is using prompt-based speculative decoding. Specifically, ngram hashing is utilized to suggest drafts of up to 64 tokens. The hasher keeps track of ngrams in the observed contexts, so mostly effective for coding tasks. Here is another demo: https://t.co/LXkWNO3GaR
Let me demonstrate the true power of llama.cpp: - Running on Mac Studio M2 Ultra (3 years old) - Gemma 4 26B A4B Q8_0 (full quality) - Built-in WebUI (ships with llama.cpp) - MCP support out of the box (web-search, HF, github, etc.) - Prompt speculative decoding The result: 300
The parameters that I used are the same as in the PR that introduced this functionality in llama.cpp: https://t.co/PGNQsIjG1V