Your curated collection of saved posts and media
@xindelt Please join discord and start a support thread: https://t.co/SxWoPjZTVD

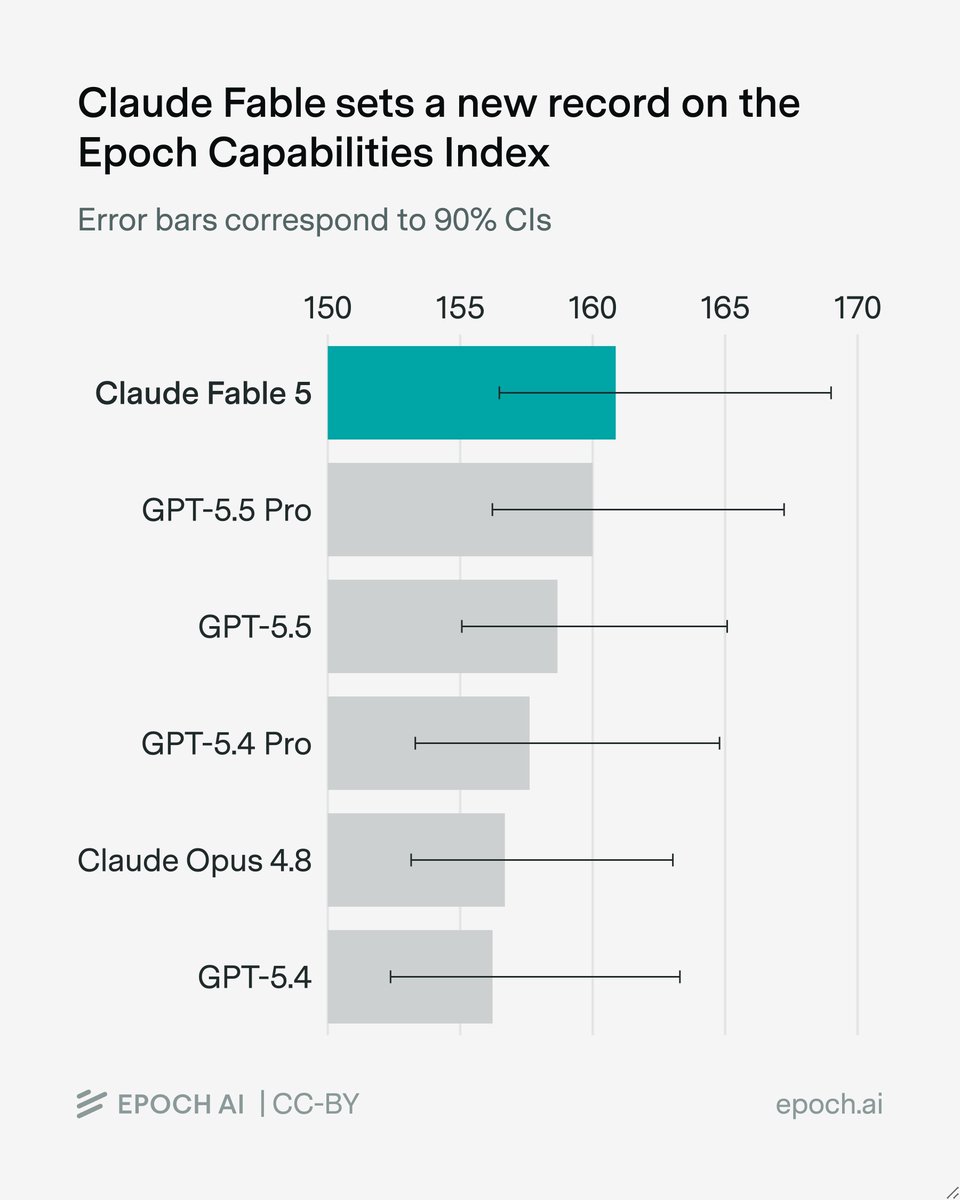
Claude Fable 5 achieves a new high score of 161 on the Epoch Capabilities Index! This beats out GPT-5.5 Pro by 1 point, and is the first time Anthropic has taken the lead on the ECI in over a year. https://t.co/qBArsYoZF1
@abowenwk yeah that turned out great https://t.co/c6yGBXsAC1

This is the NUDT mosquito drone, a spy UAV built by China's National University of Defense Technology for covert surveillance you can't see coming. Under 0.3 grams. Wings that flap 500 times a second. Sensors built for covert surveillance, all packed into a body you'd swat without thinking.
Cartesia Sonic 3.5 is now available on Together AI. We added 150+ @cartesia Sonic 3.5 voices to voice finder, so developers can listen, compare, and pick the right voice for real-time agents before deploying on Together AI. https://t.co/U3dk6hcMub
Spotify 👉 https://t.co/FZbbj0KuGM Youtube 👉 https://t.co/XJzCSDBP0W Apple Podcasts 👉 https://t.co/rD7ciZZdKC


Want unreleased @GeminiApp features before anyone else? Love breaking, testing, and shaping new tech? We're opening a limited number of slots for power users to join the Gemini Trusted Tester program. Sign up here: https://t.co/kSsRsavJPv https://t.co/6sxYCb8S0y

Das ZDF hat reagiert, in der Beschreibung der Sendung steht nun, die Formulierung zu Beginn (Musk habe zur Jagd auf Migranten aufgerufen) sei "unpräzise und deshalb missverständlich". Immer diese Missverständnisse, kennt man ja noch von Charlie Kirk https://t.co/83V0aDZaRA
I want to publicly apologize to the hundred of poor souls that I forgot to respond to in the DM request tab amen please forgive the smoothness of sulci https://t.co/fMF8upz0wi

Unrelated to AI, I find it amusing that my home city has complex civic rituals that can curse or bless you depending on your offerings to a statue. Non-residents do not understand our folkways or their powers. https://t.co/Z9Ztic4Gtz
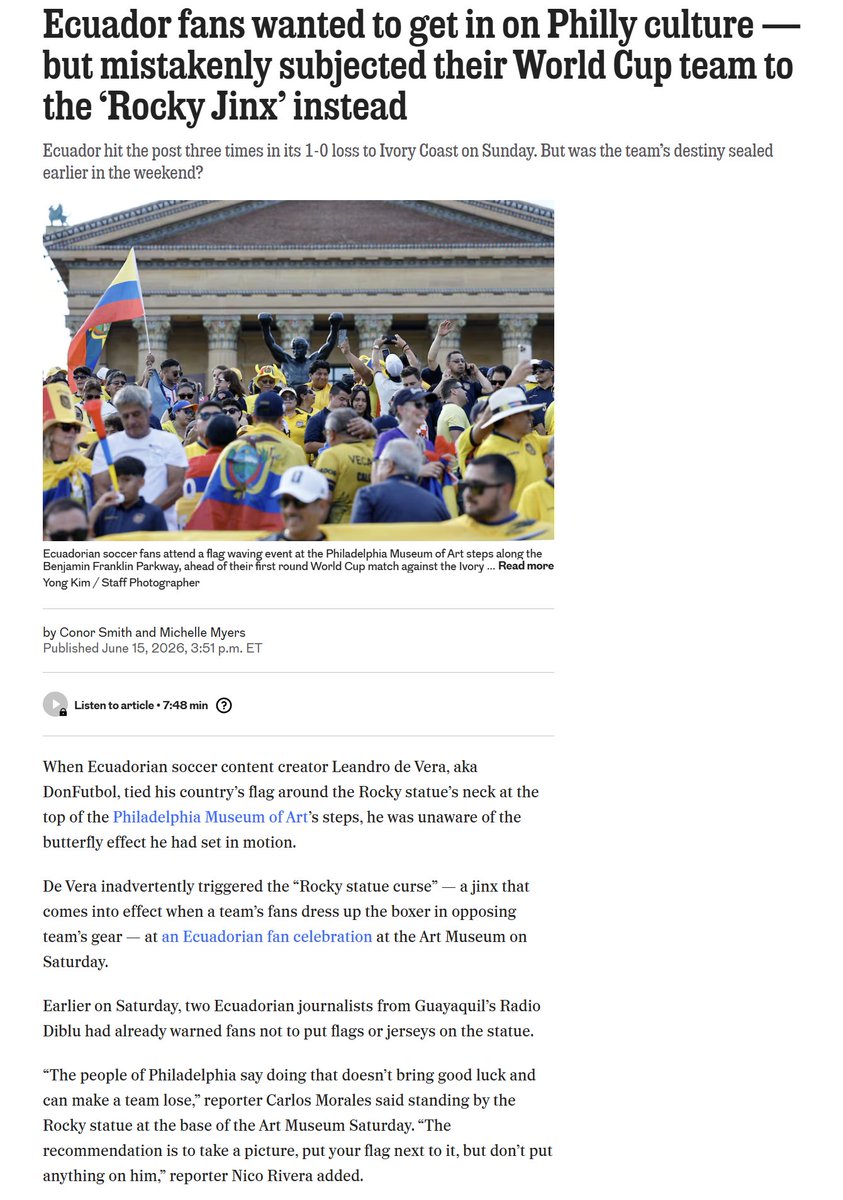
Do not dismiss the Powers of Philadelphia. https://t.co/p5KiNPiXEE

We’re sharing an early preview of Raven Prism, our stylish ambient computer in glasses form, ahead of its launch later this year. Raven Prism is Linux-based with a ARM64 architecture and devs have already built apps for it. If you’re at AWE, come by our booth for a demo! https://t.co/KGsj8TVLXs @raven_computer

Yes we can! Thanks for the @Starcloud_ shoutout @TheTimes! https://t.co/nvgkeIX6wu

Yes we can! Thanks for the @Starcloud_ shoutout @TheTimes! https://t.co/nvgkeIX6wu

@bonsai_robotics autonomy: pure vision-based, AI-native, autonomy—just 6 inches leeway, 24/7 precision. https://t.co/6LMEQt15El
@charliebcurran https://t.co/JYj6puaUPO
🚨 AI-EMEA: Mistral Vibe is absolutely cooking. I just put it through a serious stress test, and it passed with flying colours. Took it head-to-head against DeepSeek v4, Kimi 2.6, and Qwen 3.7. Massive context window + serious complexity. I threw a full 30-page script analysing

In partnership with @stripe, Hermes Agent now supports a full suite of Stripe skills. Your agent can buy things, pay per-call APIs, and provision its own SaaS, with configurable safety limits on every action. https://t.co/Gw3LINkCd3

can you guess what i'm working on https://t.co/yUR6h1rIc7
if your app is primarily on cloudflare workers hit me up and I'll get you on https://t.co/on6yrIlqhC today

if your app is primarily on cloudflare workers hit me up and I'll get you on https://t.co/on6yrIlqhC today

Sakana Marlin, Your Virtual CSO. https://t.co/IemtHKI7z4

@enjoyingthewind Thats too much to spend my time replying to all of them, lol Dynamic workflows is coming: https://t.co/tZ2yOvEcF0 Read the docs here for the rest: https://t.co/C8TYvL8ov7

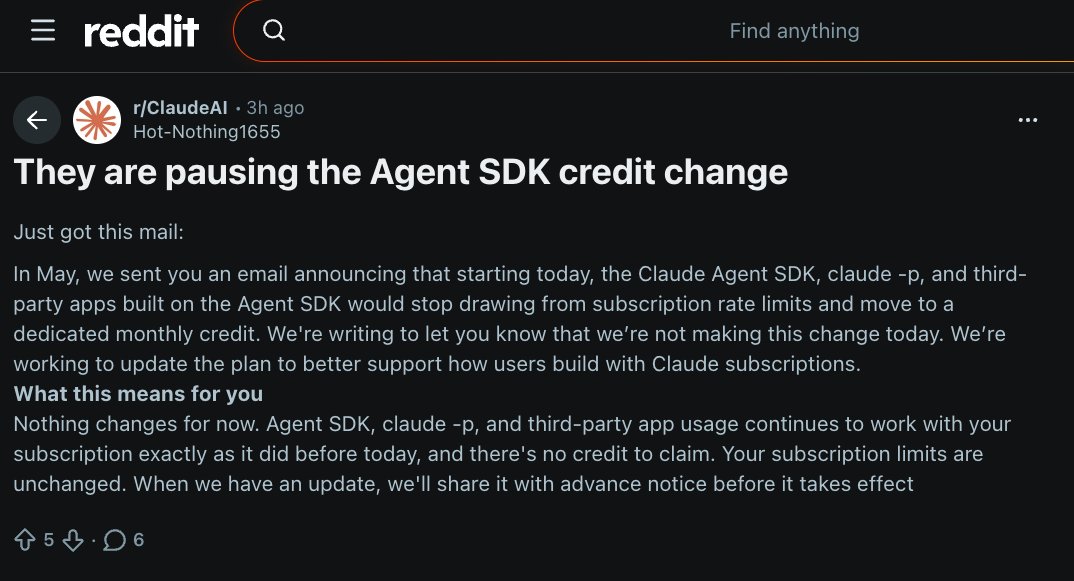
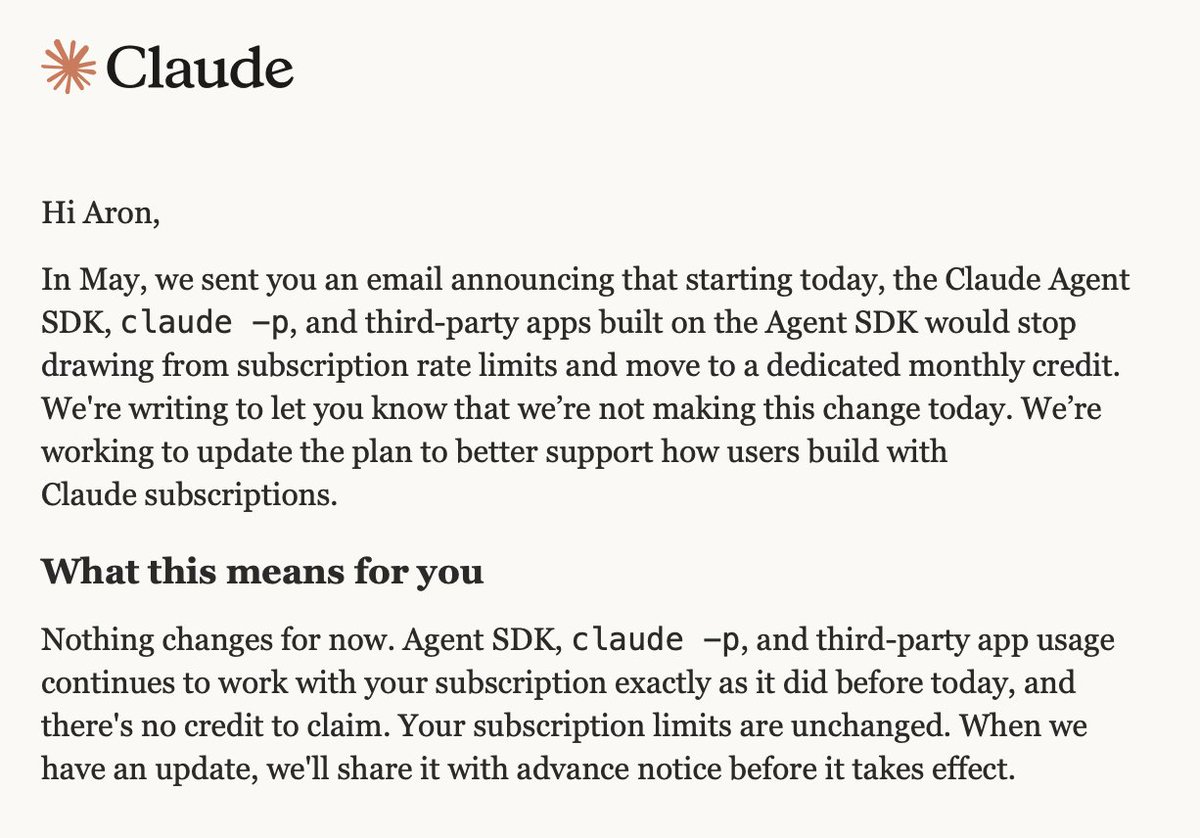
Is this real? I haven't received any communication. Wild if true. I moved a lot of my stuff away from the Claude Agent SDK due to the way they were going to charge programmatic use of Claude Code. It's tiring to run in circles with this stuff, but hope they reconsider things. https://t.co/eU6lv9WUCk
Use the OpenAI Developers plugin in Codex to build faster with OpenAI tools by setting up API keys, finding the right docs, and debugging along the way. https://t.co/ztBd3h3oeb
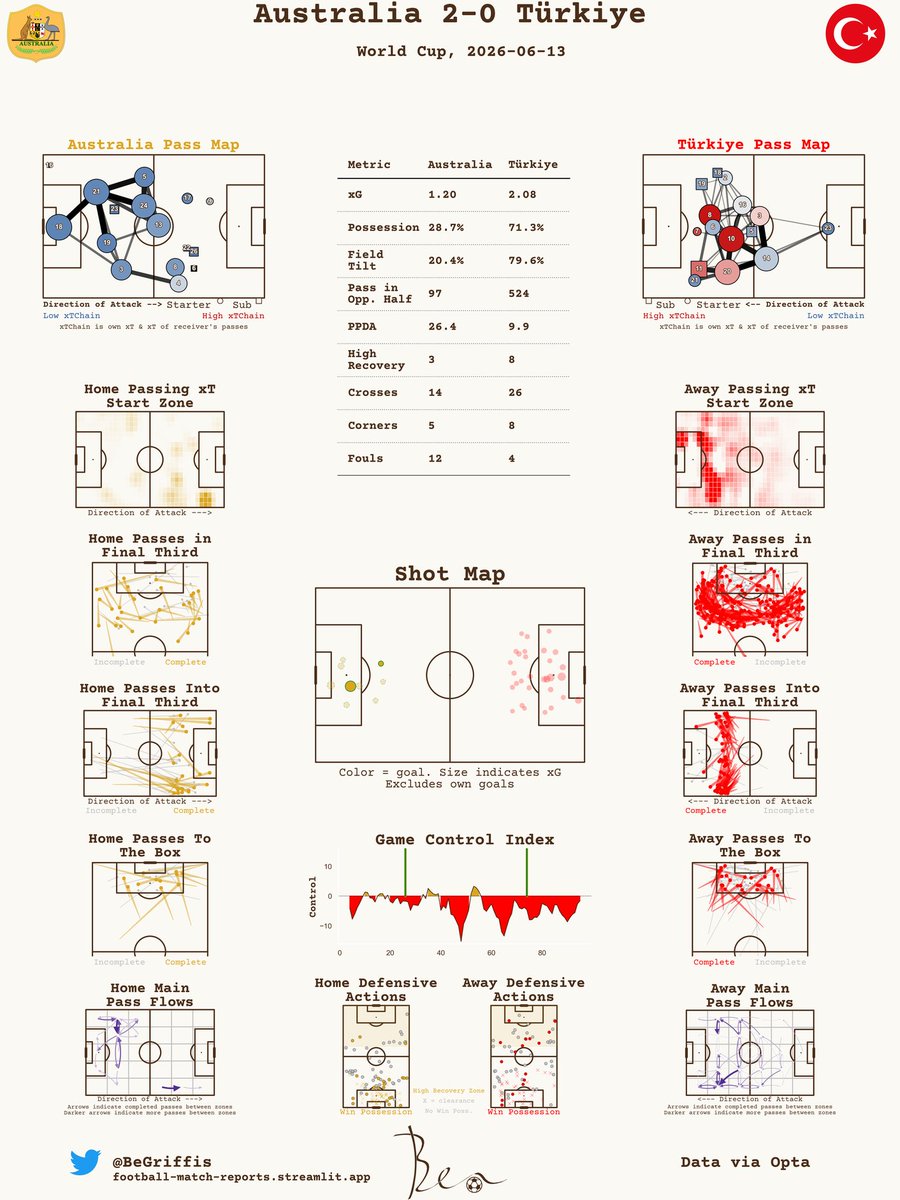
"Australians all let us rejoice" 🇦🇺 2-0 🇹🇷 Lovely low-block, countering performance from Australia to beat Turkey. Clinical. Lovely goals too #FIFAWorldCup #Socceroos https://t.co/Rt9zZlNr7i
Together with my co-founders Michael @MichaelPoli6, Stefano @Massastrello and Armin @athmsx, I am excited to announce @RadicalNumerics is emerging from stealth with a $50M seed round to build general biological intelligence. We’re also sharing an early preview of our new model Omnii, the most powerful genome language model to date. Omnii preview link: https://t.co/ouikMtRVwf At Radical Numerics, our mission is to master the code of life, and to drive the frontier of biological AI for both design and defense. This is our dual mandate, which comes from something our own team helped make possible. Our founding team trained Evo and Evo 2, the largest biological AI models (40B params) trained on DNA sequences. Trillions of tokens across all of life, from microbes to mammals. It’s fully open source, and created the field now known as generative genomics. Last year, scientists used Evo to generate the world’s first complete genome from scratch using AI. Turns out it was a bacteriophage—a type of virus. It functioned in the real world, and in this case it was harmless. But for us, it was a clear turning point. It showed that AI is no longer just analyzing biology. It is on the cusp of generating functional lifeforms. Eventually, AI will have the power to design and control life itself. That should make all of us incredibly excited, and incredibly uneasy. (Anyone can design DNA with a new function, and have it synthesized and delivered, like something from Amazon Prime). The same technology that will help us cure cancer is the very technology that might create the next global pandemic, or worse, allow the creation of bioweapons that can wipe out populations. We believe these forces are inseparable. If you work on the frontier of biology, you have to build technology to safeguard it from its misuse. Existing biosecurity tools are sorely losing the arms race, relying on outdated “have I seen this exact thing before?” style algorithms. We founded Radical Numerics to turn the tide. And we can’t do that by training on textbooks and natural language. We must understand the language of biology from the raw physical data itself, to reason across every molecule and modality, from DNA to proteins. The next frontier for AI goes far beyond chatbots or video generators to models that can understand and engineer life. Today, we’re previewing Omnii, which is already far surpassing Evo 2, and will continue improving as we scale and add new modalities (training now). 1. For human health, Omnii can read and write whole genomes (more on writing later). It’s state of the art (SOTA) on detecting causal variants for disease, and can rank Alzheimer's mutations zero-shot. We’re partnering with a diagnostics company to use Omnii for early cancer detection (pancreatic and multi-cancer). 2. For defense, Omnii is SOTA at detecting AI-generated pathogens. We benchmarked existing detection tools, and they simply can’t detect the AI-generated ones (“deepfake viruses”). We’re partnering with a US national lab to pilot Omnii for detecting the next pandemic, both natural and AI-generated. We have a data center full of Blackwells in construction now to build the most powerful biological AI models ever. This mission takes a new kind of AI lab that can actually scale on physical, biological data: new alignment research (mid/post training), scaling long context, building out mech interp teams to dissect what these models learn, new architectures and systems designs, all from the ground up. Our team is made up of AI researchers and scientists from top labs and institutions (e.g. Stanford, MIT, Google DeepMind), but more importantly, we all share the belief that this is the most important challenge of our lifetime. If you feel similarly, we are hiring. We aim to bring the brightest minds in AI and science together to save lives. Thanks to our partners on this journey, led by Emergence Capital @emergencecap, with Obvious Ventures @obviousvc, Triatomic @TriatomicCap , and Patrick Collison @patrickc. Our advisors include Eric Horvitz @erichorvitz, CSO of Microsoft, Chris Re @HazyResearch of Stanford, George Church @geochurch of Harvard, and Andrew Weber @AndyWeberNCB, former Assistant Secretary of Defense for Nuclear, Chemical and Biological Defense Programs. Fortune article: https://t.co/L3f3f1329T Jobs: https://t.co/EzsHSMcGJ1


Breaking News: Claude is pausing the Agent SDK credit change! https://t.co/kun5cj0D0l
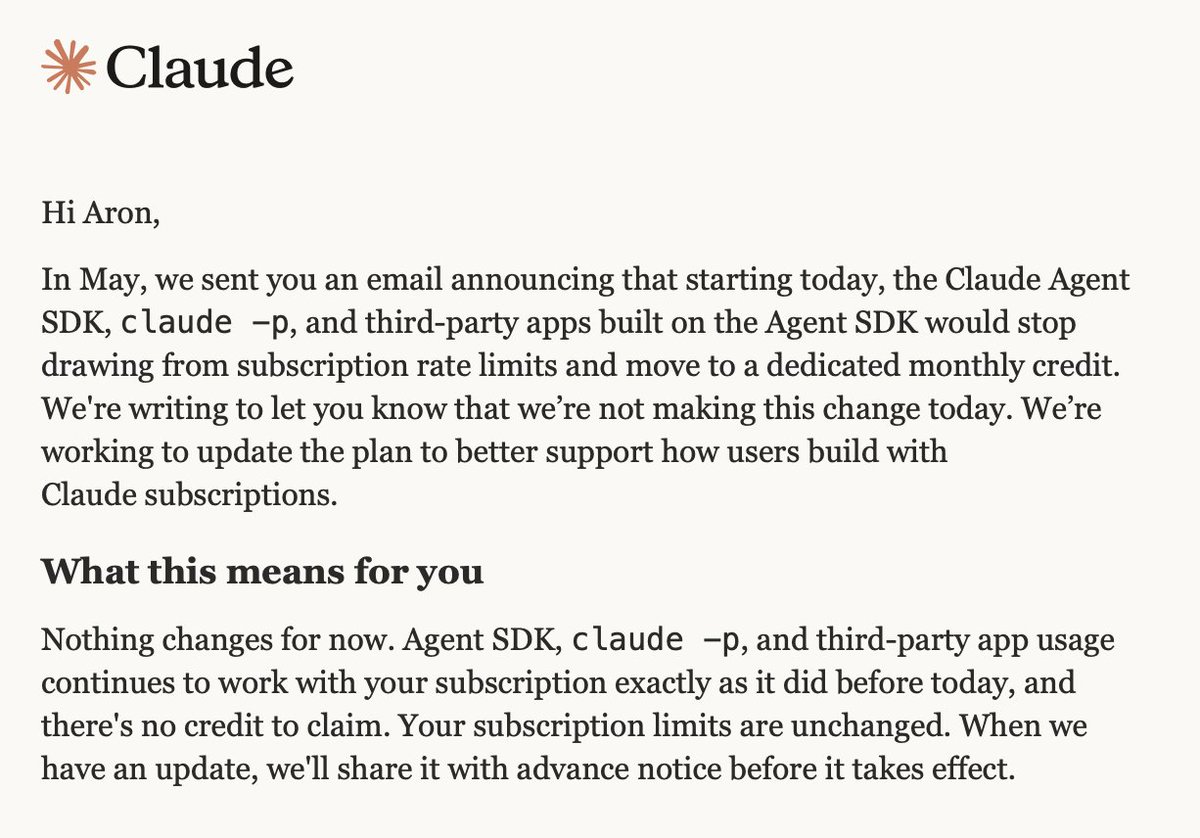
Breaking News: Claude is pausing the Agent SDK credit change! https://t.co/kun5cj0D0l
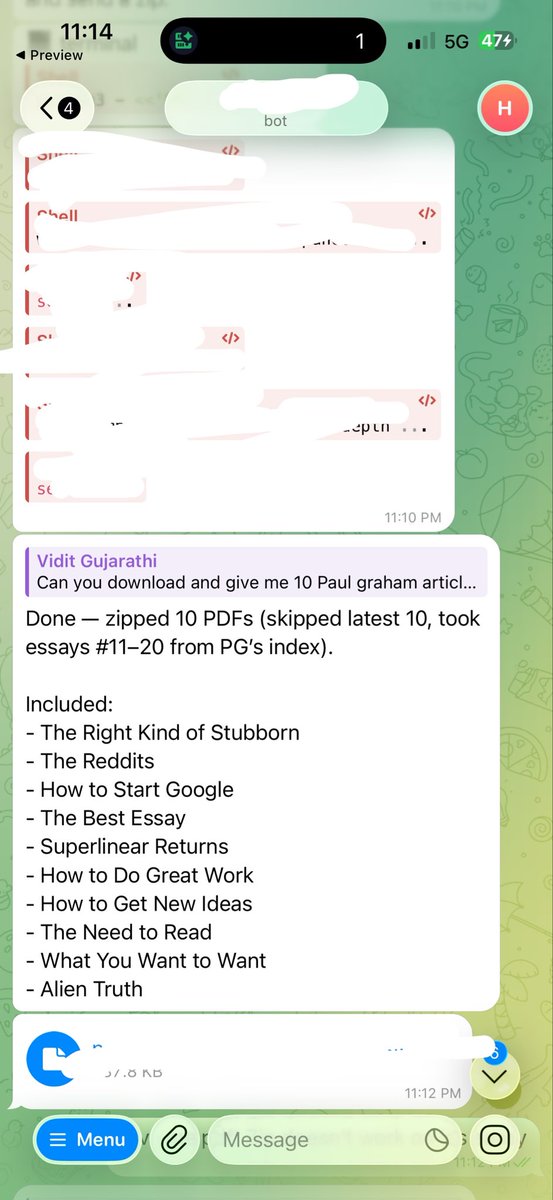
Flying to Hongkong for World rapid & blitz teams from Tashkent and I have my offline reading sorted, thanks to hermes. https://t.co/JFqJMlRgID
I shared a little more on that here if you are interested: https://t.co/NDjG0meuee
https://t.co/nV84ktpZBf

The future of AI should be grounded in human agency, creativity, and understanding. @FastCompany explores the rise of world models and features insights from World Labs cofounder @drfeifei: "Her vision for World Labs—and its human-centered future—is both consistent and persistent. It's like a simulation in her world model. Once in place, it stays put." Read the full article here ↓
“I’m keenly aware of multiple clocks,” Li says. “They’re all ticking.” https://t.co/5ck44tILuz

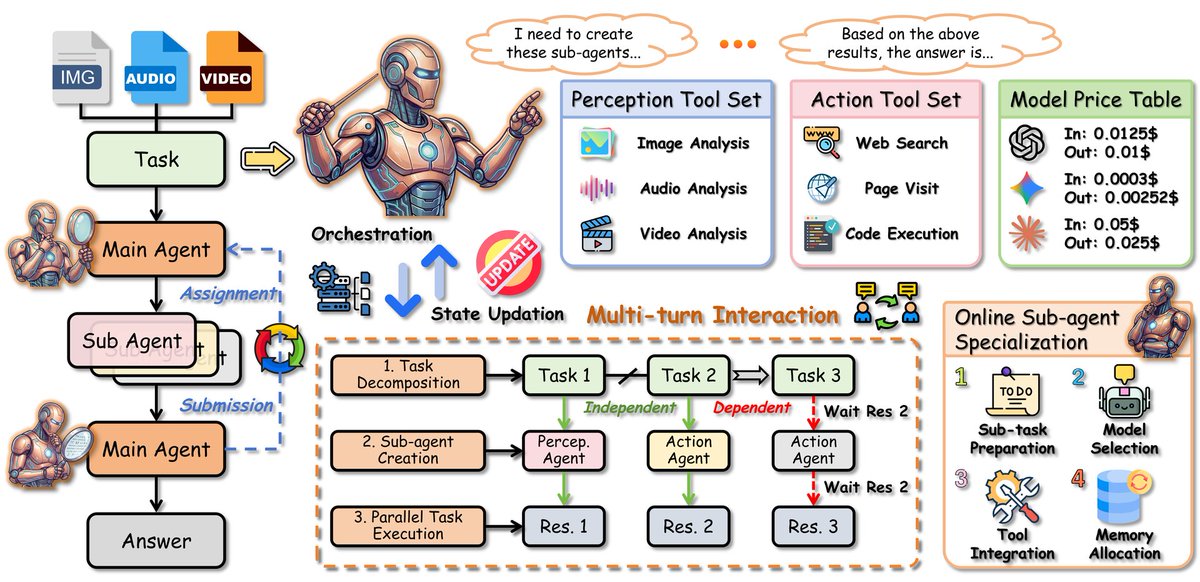
Orchestra-o1 A multi-agent orchestration framework that decomposes complex omnimodal tasks into parallel subtasks. It achieves 72.8% accuracy on OmniGAIA, surpassing the next best open-source approach by over 10 percentage points. https://t.co/u9VDfwnLUw