@rasbt
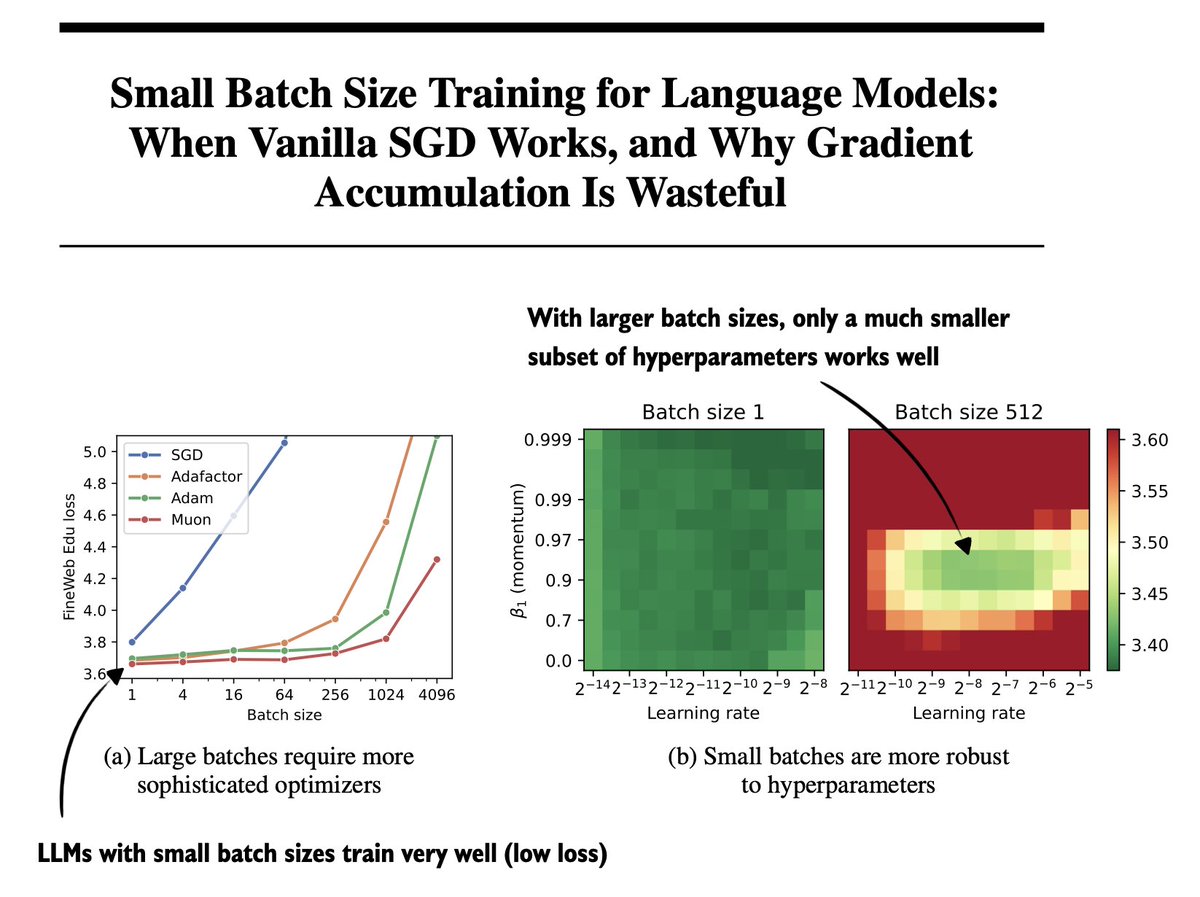
One of the underrated papers this year: "Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful" (https://t.co/0O4XjGDLIP) (I can confirm this holds for RLVR, too! I have some experiments to share soon.) https://t.co/Vy6yVeGqiK