@ValerioCapraro
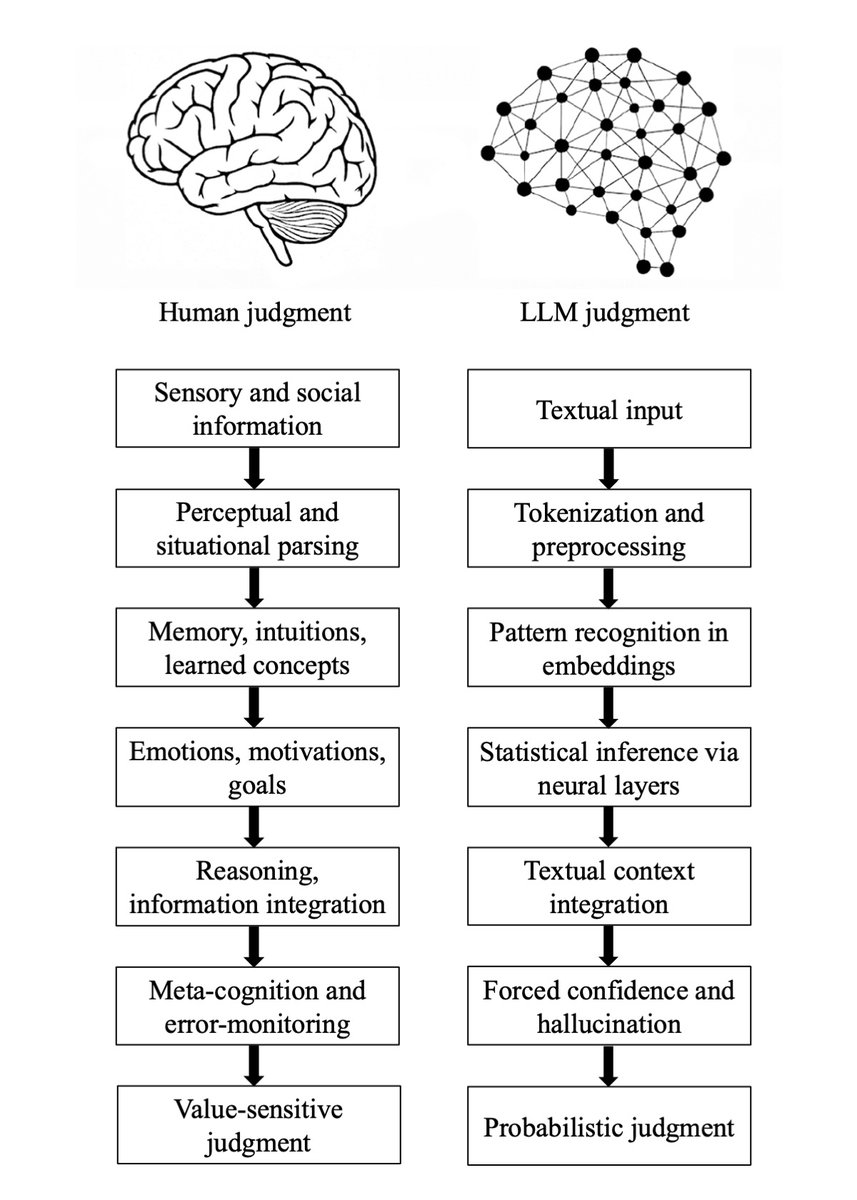
Major preprint just out! We compare how humans and LLMs form judgments across seven epistemological stages. We highlight seven fault lines, points at which humans and LLMs fundamentally diverge: The Grounding fault: Humans anchor judgment in perceptual, embodied, and social experience, whereas LLMs begin from text alone, reconstructing meaning indirectly from symbols. The Parsing fault: Humans parse situations through integrated perceptual and conceptual processes; LLMs perform mechanical tokenization that yields a structurally convenient but semantically thin representation. The Experience fault: Humans rely on episodic memory, intuitive physics and psychology, and learned concepts; LLMs rely solely on statistical associations encoded in embeddings. The Motivation fault: Human judgment is guided by emotions, goals, values, and evolutionarily shaped motivations; LLMs have no intrinsic preferences, aims, or affective significance. The Causality fault: Humans reason using causal models, counterfactuals, and principled evaluation; LLMs integrate textual context without constructing causal explanations, depending instead on surface correlations. The Metacognitive fault: Humans monitor uncertainty, detect errors, and can suspend judgment; LLMs lack metacognition and must always produce an output, making hallucinations structurally unavoidable. The Value fault: Human judgments reflect identity, morality, and real-world stakes; LLM "judgments" are probabilistic next-token predictions without intrinsic valuation or accountability. Despite these fault lines, humans systematically over-believe LLM outputs, because fluent and confident language produce a credibility bias. We argue that this creates a structural condition, Epistemia: linguistic plausibility substitutes for epistemic evaluation, producing the feeling of knowing without actually knowing. To address Epistemia, we propose three complementary strategies: epistemic evaluation, epistemic governance, and epistemic literacy. Full paper in the first reply. Joint with @Walter4C & @matjazperc