@dair_ai
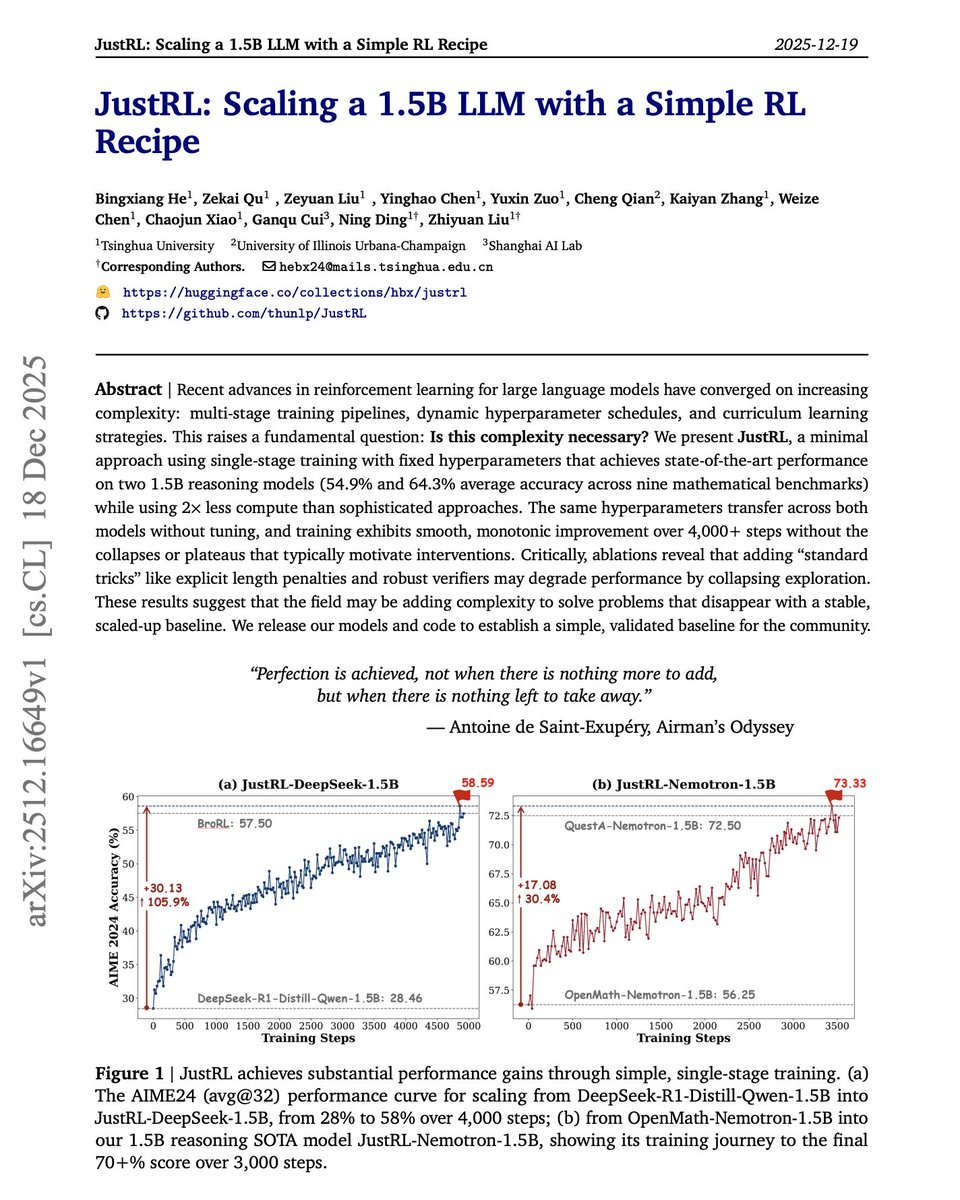
Sometimes less is more. More complexity in RL training isn't always the answer. The default approach to improving small language models with RL today involves multi-stage training pipelines, dynamic hyperparameter schedules, curriculum learning, and length penalties. But what if these techniques are solving problems that simpler approaches never create? This new research introduces JustRL, a minimal RL recipe that uses single-stage training with fixed hyperparameters to achieve state-of-the-art performance on 1.5B reasoning models. They stripped away everything non-essential. No progressive context lengthening. No adaptive temperature scheduling. No mid-training reference model resets. No length penalties. Just basic GRPO with fixed hyperparameters throughout training. Results: JustRL-DeepSeek-1.5B achieves 54.9% average accuracy across nine mathematical benchmarks. JustRL-Nemotron-1.5B reaches 64.3%. The best part: JustRL uses 2x less compute than more sophisticated approaches. On AIME 2024, performance improves from 28% to 58% over 4,000 steps of smooth, monotonic training without the collapses or plateaus that typically motivate complex interventions. Perhaps most surprising: ablations show that adding "standard tricks" like explicit length penalties and robust verifiers actually degrades performance by collapsing exploration. The model naturally compresses responses from 8,000 to 4,000-5,000 tokens without any penalty term. The same hyperparameters transfer across both models without tuning. No per-model optimization required. Paper: https://t.co/88X69gfBbU Learn to build with AI agents in our academy: https://t.co/zQXQt0PMbG