Your curated collection of saved posts and media
Two weeks later, this is now the state-of-the-art in local text to video models, still on my computer, still completely off-line. Pretty rapid progress. https://t.co/3NwdGVCiL3
On one hand, these are obviously much worse "otter using wifi on an airplane" than any state-of-the AI text-to-video generation, it looks like something from 2022. On the other, it was done entirely offline on my computer using open AI video generation tools, a new capability. h
Generating a Multimedia Research Report with LLM Structured Outputs 🧱📑 In our brand-new video 💫, we show you how to build a simple report generator that can summarize insights from complex documents (e.g. a slide deck), and synthesize a report with interleaving text and images. Structured outputs is a key building block towards building agentic RAG / report generation workflows, and this video is a great way to get started. Video: https://t.co/P3LdK9fGlb Notebook: https://t.co/o42mgKHjdg Signup for LlamaCloud: https://t.co/yQGTiRSNvj

Statistical Rethinking (2024 Edition) Includes lecture recordings and slides. https://t.co/l2LCn19T5m

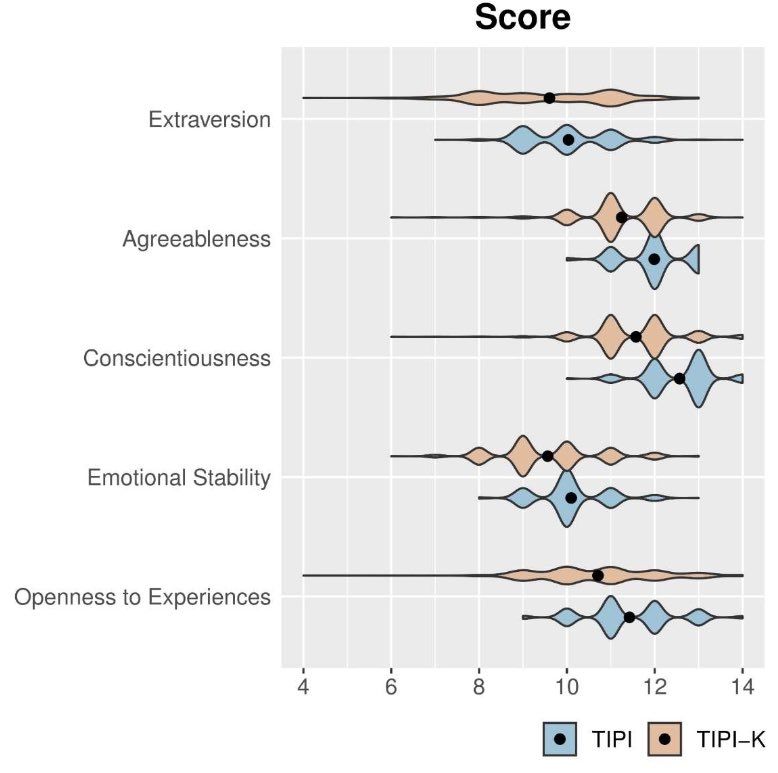
The “personality” and “opinions” of AI are not stable, they are influenced by prompting & sycophancy Ab example: when GPT-4 was prompted in Korean to act Korean & prompted in English to act American, GPT-4 replicated Big-5 personality differences between Koreans & Americans https://t.co/jUYGDr5YfG
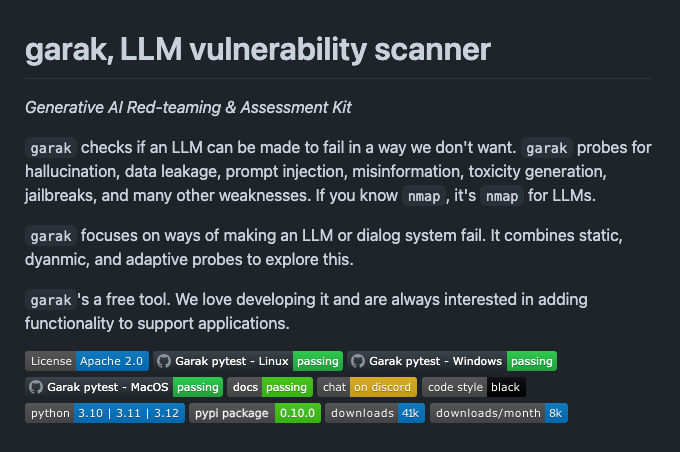
🐙garak - LLM Vulnerability Scanner Great project from NVIDIA to perform AI red-teaming and vulnerability assessment on LLM applications. https://t.co/nnc4c7tDlF
Hahahaha! I believe this refers to RND (Random Net Distill). I too was looking at Montezuma a lot back then. Fun times, but in retrospect, pretty silly/naive RL approaches all around the community, the whole from scratch + hack exploration thing. https://t.co/j17RqS8aMR
https://t.co/KA1tZYvgd3

HF: https://t.co/ScIfxCTEVZ Paper: https://t.co/RdxuinmCeS https://t.co/JulVnnbTmG

Looks like there is a new round of LLM battles on @lmarena_ai this weekend 👀👀👀 - anonymous-chatbot - some reports suggest that it is an improved 4o with better formatting and instruction use. - secret-chatbot - potentially a bigger size gemini-exp model mentioned last week. https://t.co/644PApBxn2
anonymous-chatbot is back in the arena this is usually reserved for GPT-4o model updates inside ChatGPT 👀 https://t.co/OGSRJ7a6Ty

Being in the training data is useful. A few of the LLMs do a good “explain this like Ethan Mollick” - not nearly as good as me (in my opinion) - but kind of neat to see a form of intellectual legacy happen in real time. https://t.co/m2ahDpannZ

Multimodal vision continues to be the most difficult AI ability to get a strong intuition for. The models can do incredible things like recognize places from subtle clues or read emotion & attitudes, but also miss stuff, like the fact that this image is upsettingly distorted. https://t.co/VhpUoRd0Uw

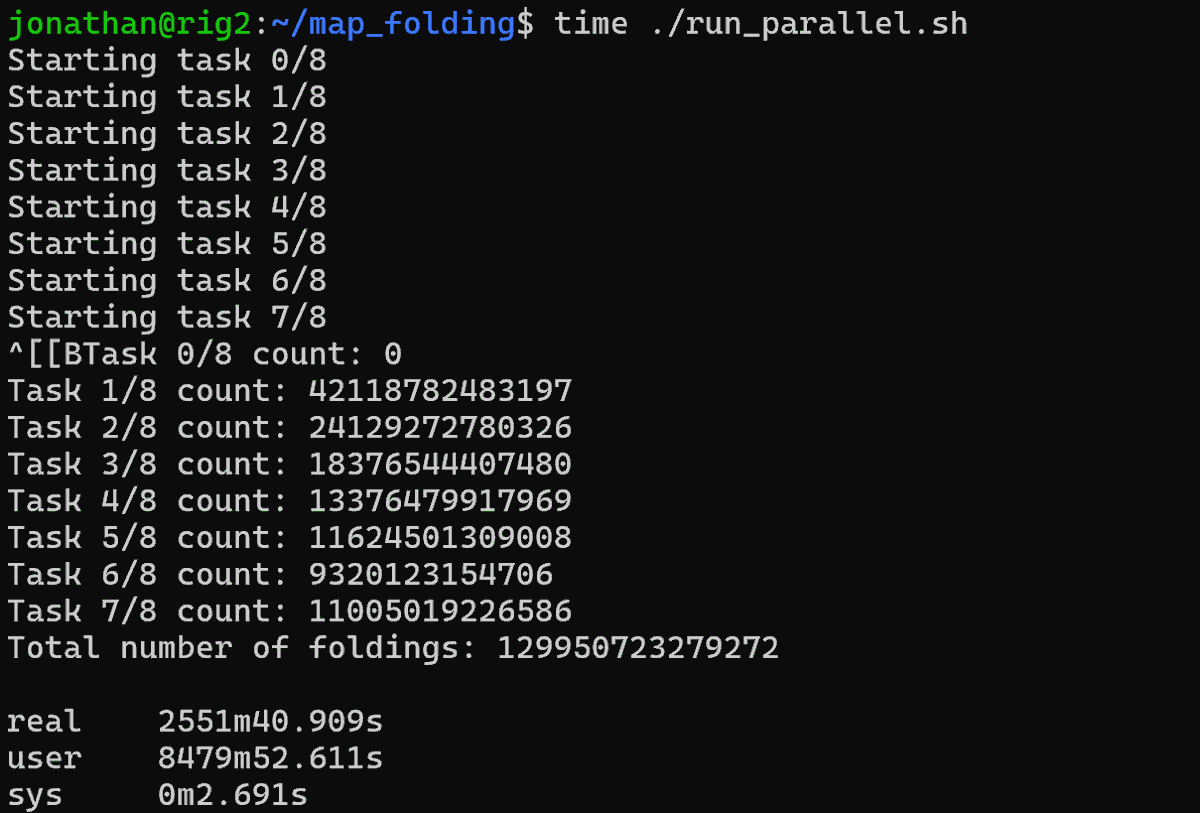
Nerd-sniped by a video from the channel 'Physics for the Birds', I looked into what it would take to add an extra item to this sequence of integers: https://t.co/WugJCkKP0t (Number of ways of folding an n X n sheet of stamps) Calculating the already-known 7x7 case took 42 hours. https://t.co/h47MB4tYq4
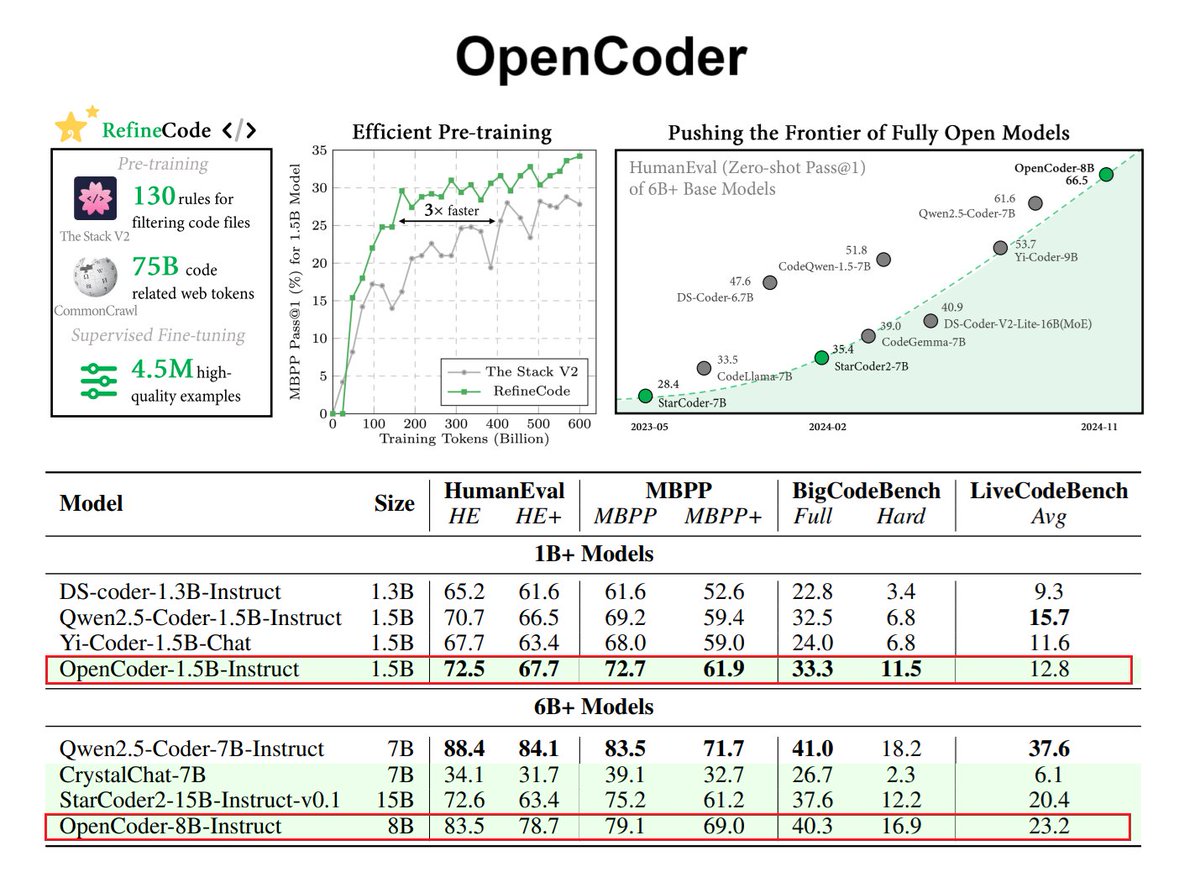
Where the field is headed (agentic workflows with advanced tool/computer use) open-source code LLMs are going to be a big deal! Great to see this new effort, OpenCode, a fully open-source LLM specialized for code generation and understanding. Main factors for building high-performing code LLMs: - effective data cleaning with code-optimized heuristic rules for deduplication, - recall of relevant text corpus related to code - high-quality synthetic in both annealing and supervised fine-tuning stages OpenCoder surpasses previous fully open models at the 6B+ parameter scale and releases not just the model weights but also the complete training pipeline, datasets, and protocols to enable reproducible research.

Claude's so good at this kind of thing lol https://t.co/paKeFuLWE9

devin is rebuilding our documentation https://t.co/uHpPpXPAhK
There is a lot of ruin in a social network, and they are pretty durable, especially when there are no real alternatives. But with the rise of alternatives, the dynamics shift. Any crisis here could be the one causing a rapid cascading network collapse of major X communities. https://t.co/KiNzPwnABe
The sudden increase in the rate that big accounts are quitting X is notable. I am sure this site will continue, and even grow, but feels like the end of an era of Twitter as intellectual town square. I am sticking around, but, increasingly, good discussion is spread across sites

This was impressive: "Claude, I need you to give me a fictional deep alternate history, think Tim Powers or Matthew Rossi or Pinchon" "Go deeper" Hamilton really did scratch an equation into a bridge, Augustus De Morgan was real, there was a Lithuanian book smuggling movement... https://t.co/LLf9S3p6ri

[14 Nov 2024] Congrats to @GeminiApp for retaking the #1 LLM crown from @OpenAI! https://t.co/AAQuduq03R https://t.co/d85VXRbkSU
gemini-exp-1114…. available in Google AI Studio right now, enjoy : ) https://t.co/fBrh6UGcJz
Remember exercise pages from textbooks? Large-scale collection of these across all realms of knowledge now moves billions of dollars. Textbooks written primarily for LLMs, compressed to weights, emergent solutions served to humans, or (over time) directly enacted for automation. https://t.co/PjO97NeUdR

I got NotebookLM to play a role-playing game by giving it a 308 page manual Pretty good application of the rules, the character creation is very good (quoting accurately from 100 pages in) with small hallucinations, and the adventure is pretty solid! Take a listen to 4:00 on... https://t.co/7uMLAA3NEU
Whether you're at #EMNLP2024 in person or following from your feed, here are 5️⃣ research papers being presented by AI research teams at Meta to add to your reading list. 1️⃣ Distilling System 2 into System 1: https://t.co/bGWYvuAVzs 2️⃣ Altogether: Image Captioning via Re-aligning Alt-text: https://t.co/8kvewKBe9B 3️⃣ Beyond Turn-Based Interfaces: Synchronous LLMs for Full-Duplex Dialogue: https://t.co/mCKjjTEeKn 4️⃣ Memory-Efficient Fine-Tuning of Transformers via Token Selection: https://t.co/OTthVwdgmm 5️⃣ To the Globe (TTG): Towards Language-Driven Guaranteed Travel Planning: https://t.co/Yt6qray2sf


Complete Prompt Engineering Curriculum Whether you are building an AI agent or complex RAG systems, prompt engineering is key to build effectively. There are lots of approaches out there but in our new LLM prompting courses, we teach you about the methods and best practices that work in real-world LLM applications. Enroll in our academy to start learning: https://t.co/zQXQt0PMbG

I'm thrilled to announce that François Charton (@f_charton @AIatMeta) will be kicking off our new AI for Science seminar series next Wednesday. He is at the forefront of using AI for mathematics, cryptography, and theoretical physics. @datascience_uw https://t.co/8wTojx76yt https://t.co/IkpbgPmws8

Reasoning LLMs is one of the most interesting trends to watch going into 2025. I’ve been thinking a lot about how to build with reasoning LLMs, specifically agentic workflows. How can AI devs take advantage of components like MoA and MCTS when there is barely any research for it, not to mention the lack of insights and best practices? First, how do we enable devs to build with reasoning capabilities? I like how Nous Research is approaching this with their Forge Reasoning APIs and “Reasoning Layer” components (MoA, MCTS, and Chain of Code). I think it’s way too early for such a reasoning layer but it seems that things are quickly moving in that direction; the o1 model series together with this forge reasoning API is a good indication of what’s to come. Some thoughts on the Forge Reasoning API vs o1 for language agents: I’ve been experimenting extensively with the o1 models and they are hard to customise. However, for many multi-agent systems, there is a need to get them to take on a persona that helps produce richer and more reliable outputs and facilitates better communication between agents. To achieve this, I often need to prompt the agents to behave and act a certain way and take on different roles depending on where they are in the conversation or process. Having the ability to use the right reasoning component or a combination, with configurable parameters (similar to the LLM itself), will be useful to build more complex and effective agentic systems. Customization is key here. Extended thoughts here: https://t.co/XglPppukqc

Closing the feedback loop is so underrated and a key way to continuously improve our AI products and UXes https://t.co/uSin6eNZXe https://t.co/zqpvMAbkAz

Spent time today digging in the literature for valuable benchmarks and found quite a few interesting ones that meet these criteria: - Has scores of real humans. - Shows models scoring much lower than humans. - Seems to test for fairly general ability, not silly spelling tricks. https://t.co/e4mmHRkIa4
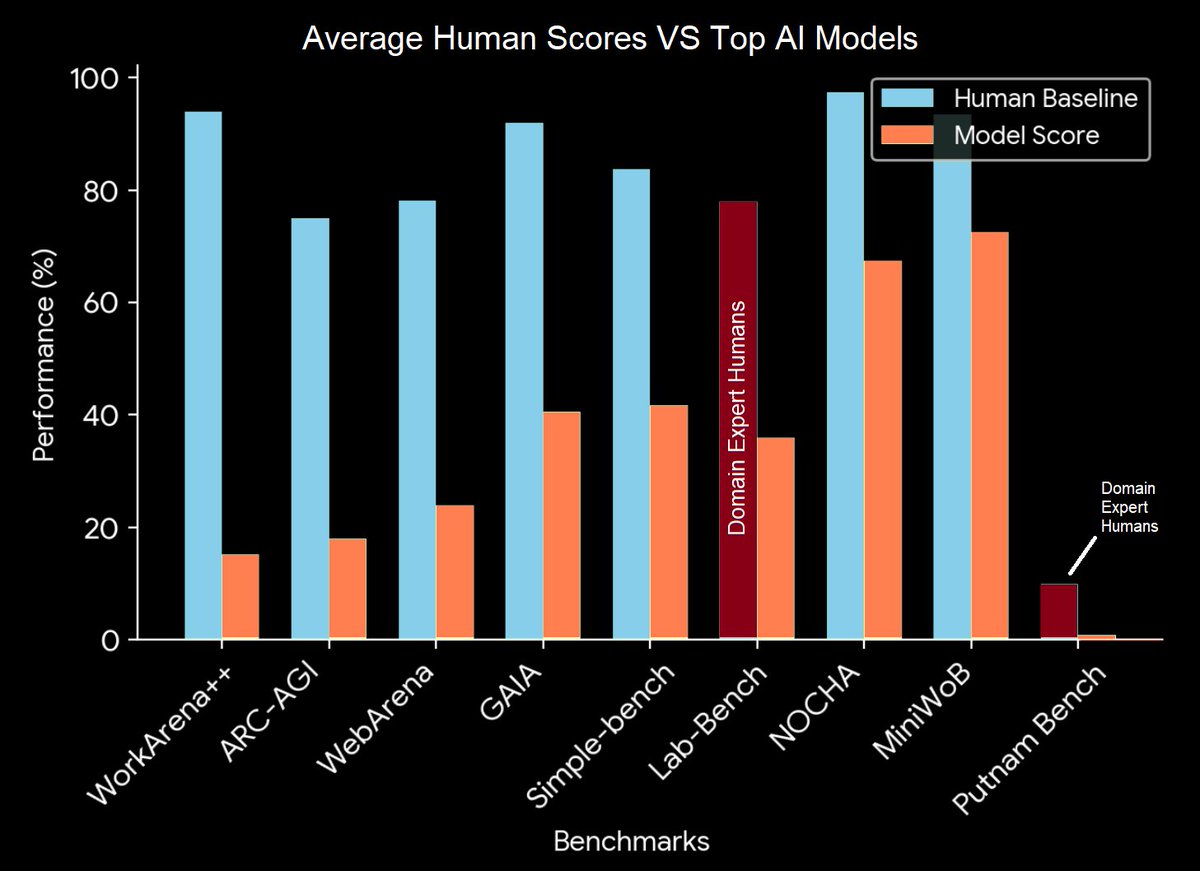
At least for non-experts: “AI-generated poems are now ‘more human than human’… participants are more likely to judge that AI-generated poems are human-authored, compared to actual human-authored poems…. participants rate AI-generated poems more highly than human-written poems” https://t.co/cP5bk1KLjy

Taught gemini how to highlight PDF text in a document :) Dropping in a bit in our docs https://t.co/1Vx4Lm08AJ

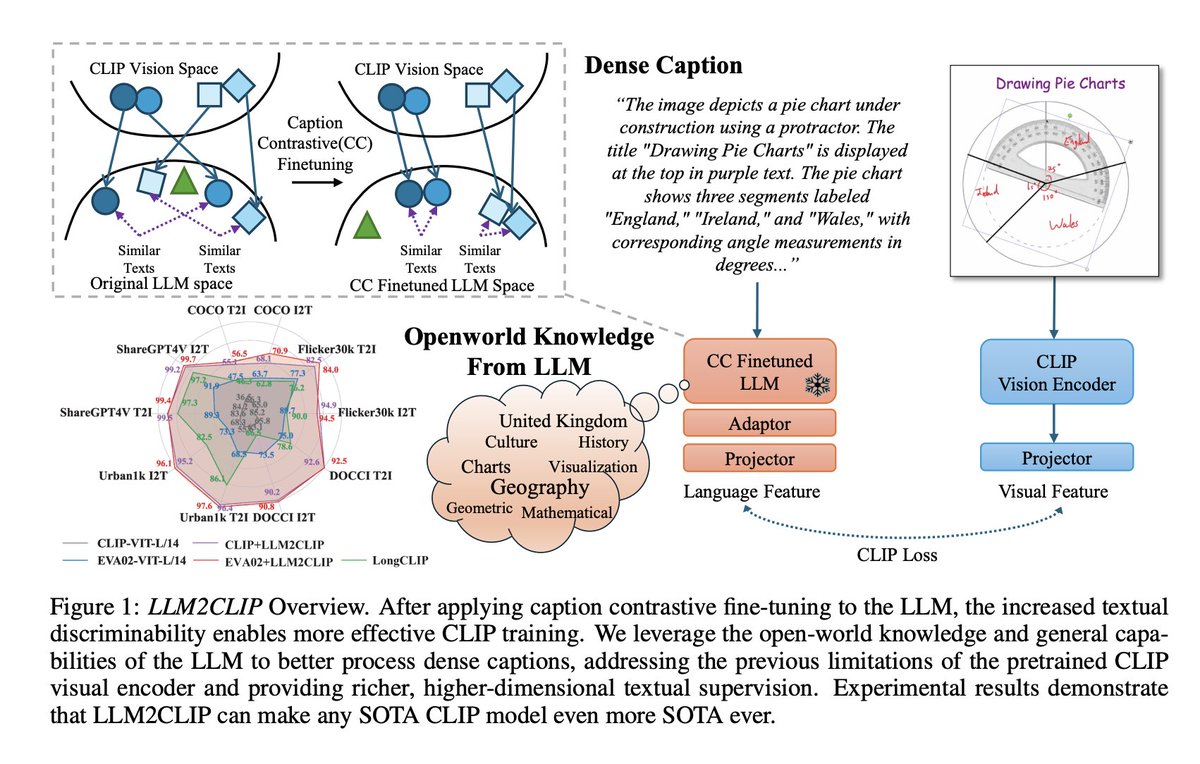
Microsoft released LLM2CLIP: a CLIP model with longer context window for complex text inputs 🤯 TLDR; they replaced CLIP's text encoder with various LLMs fine-tuned on captioning, better top-k accuracy on retrieval 🔥 All models with Apache 2.0 license on @huggingface 😍 https://t.co/xvwaWmZJj1
🤣😅😂 https://t.co/CTf7GqAjXF
@HamelHusain Nah this is good -- people who are enthusiastic to spam the buttons deserve more votes! (And people enthusiastic enough to write a script to spam them... even better :D )
OpenCoder doesn't get enough love They open-sourced the entire pipeline to create QwenCoder-level code models. This includes: - Large datasets - High-quality models - Eval framework Tons of great lessons and observations in the paper 📝 Paper: https://t.co/gh4DSeHj35 https://t.co/4geAGctnsC
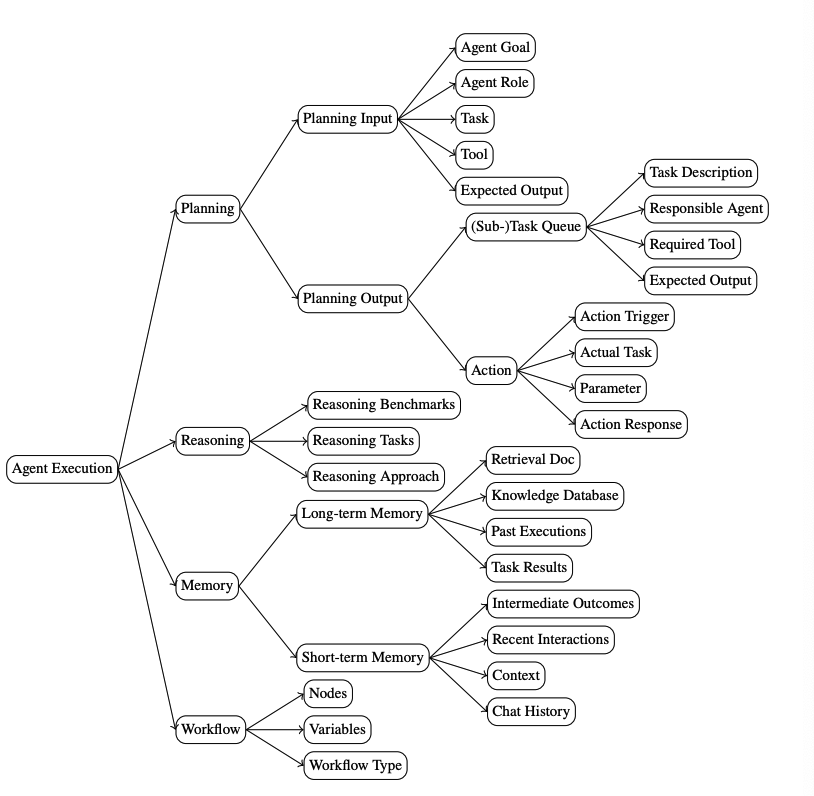
A Taxonomy of AgentOps for Enabling Observability of Foundation Model based Agents New research analyzes AgentOps platforms and tools, highlighting the need for comprehensive observability and traceability features to ensure reliability in foundation model-based autonomous agent systems across their development and production lifecycle.
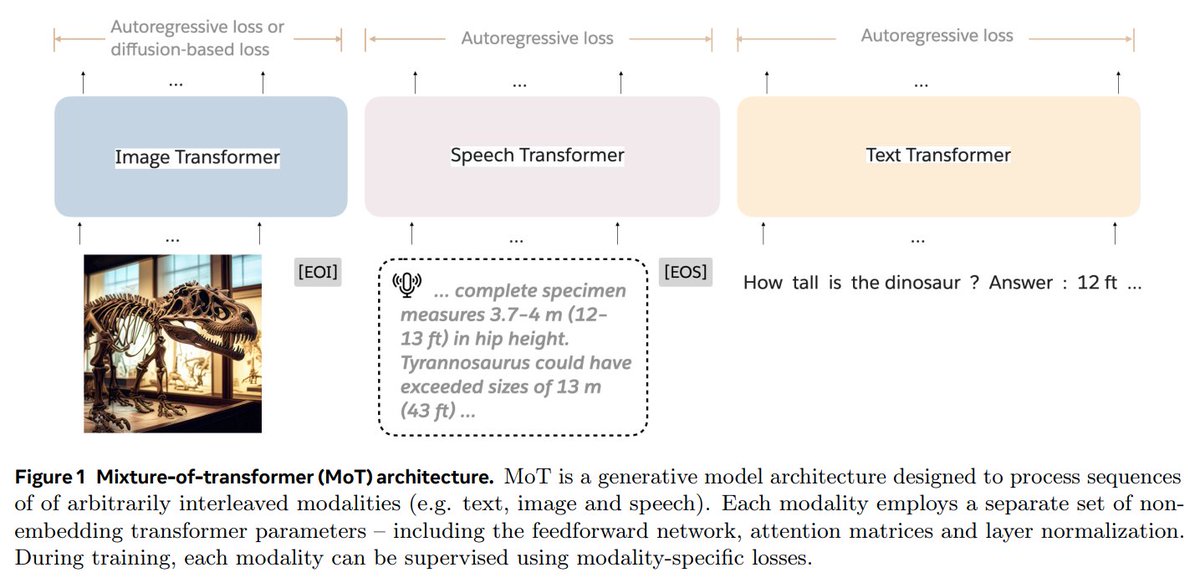
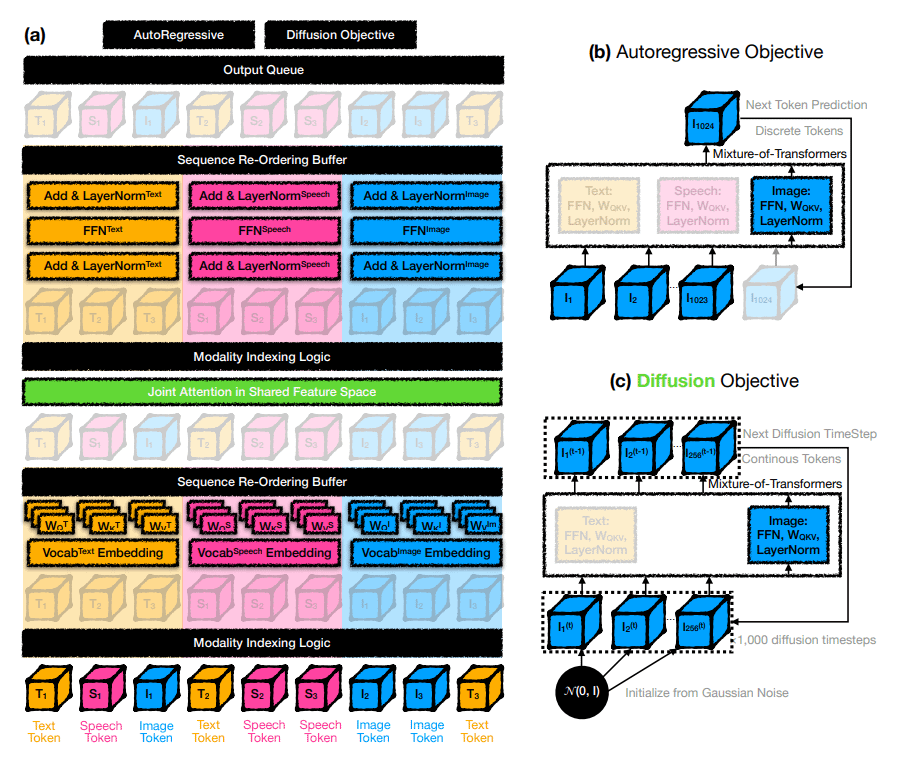
Mixture-of-Transformers (MoT) is a new @AIatMeta and @Stanford's MLLM design for efficient training of MLLMs using less computing power. It uses specific networks for each type of input: text, images, and speech, while still sharing attention across all the data. 👇 https://t.co/nYdDECRnOR