@ldjconfirmed
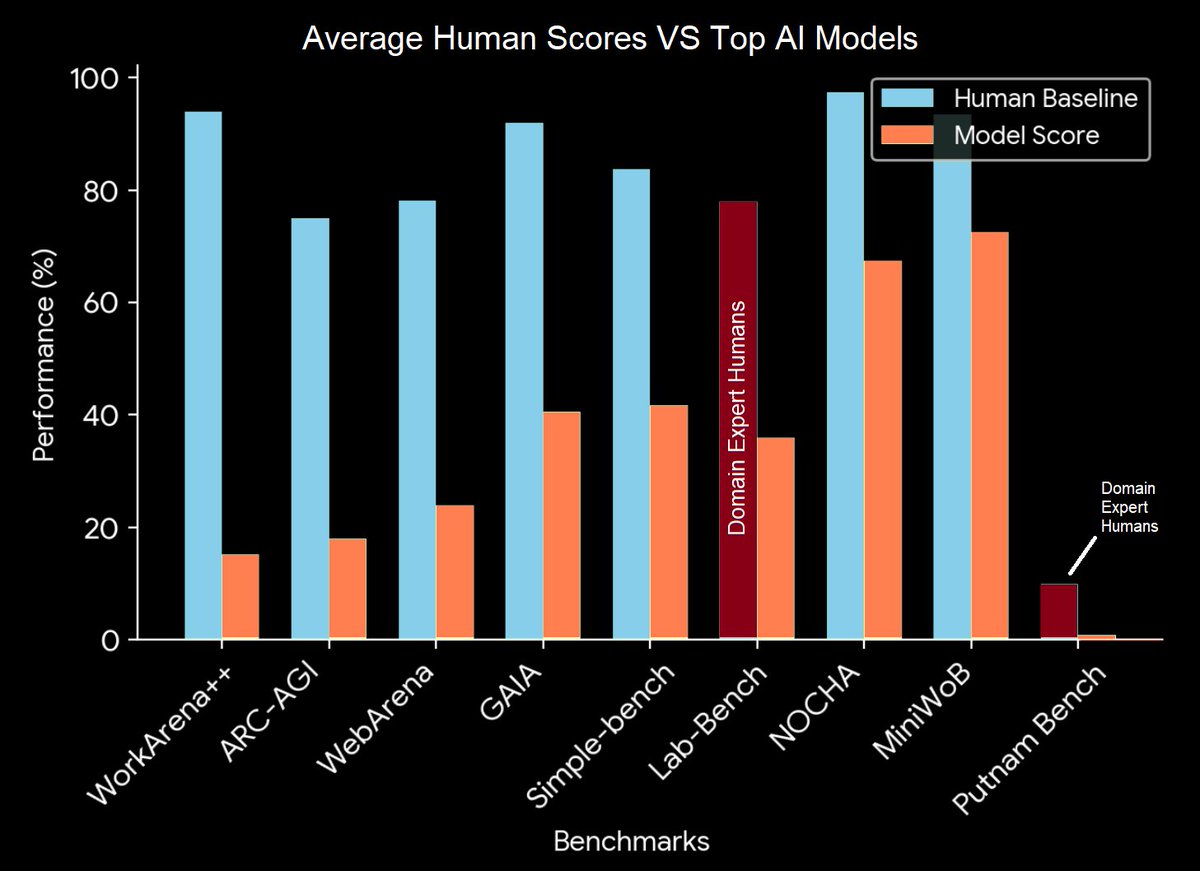
Spent time today digging in the literature for valuable benchmarks and found quite a few interesting ones that meet these criteria: - Has scores of real humans. - Shows models scoring much lower than humans. - Seems to test for fairly general ability, not silly spelling tricks. https://t.co/e4mmHRkIa4