@TheTuringPost
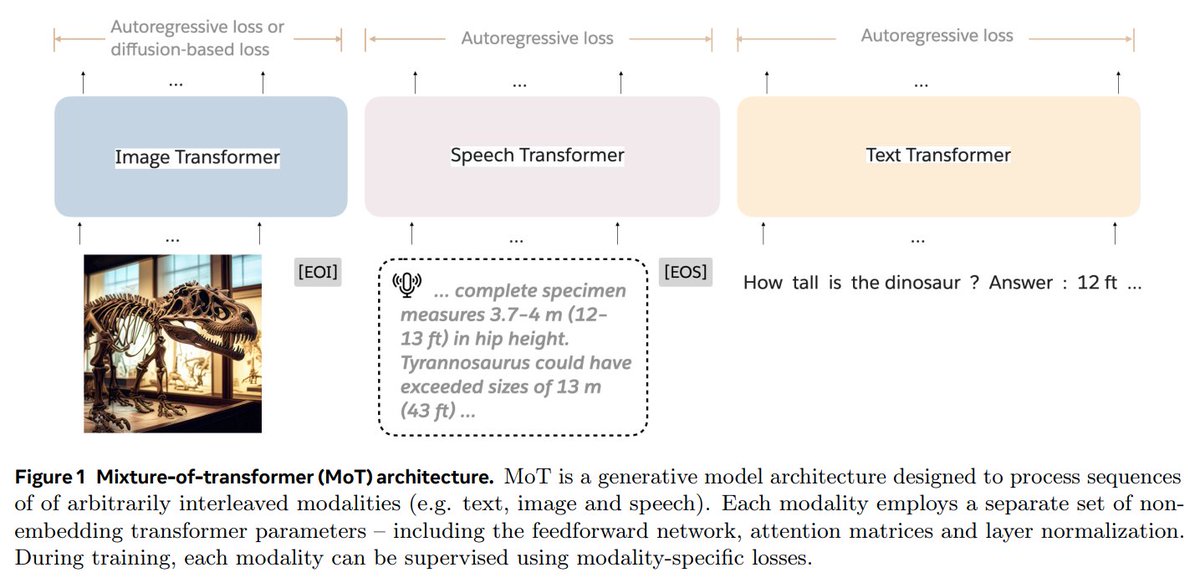
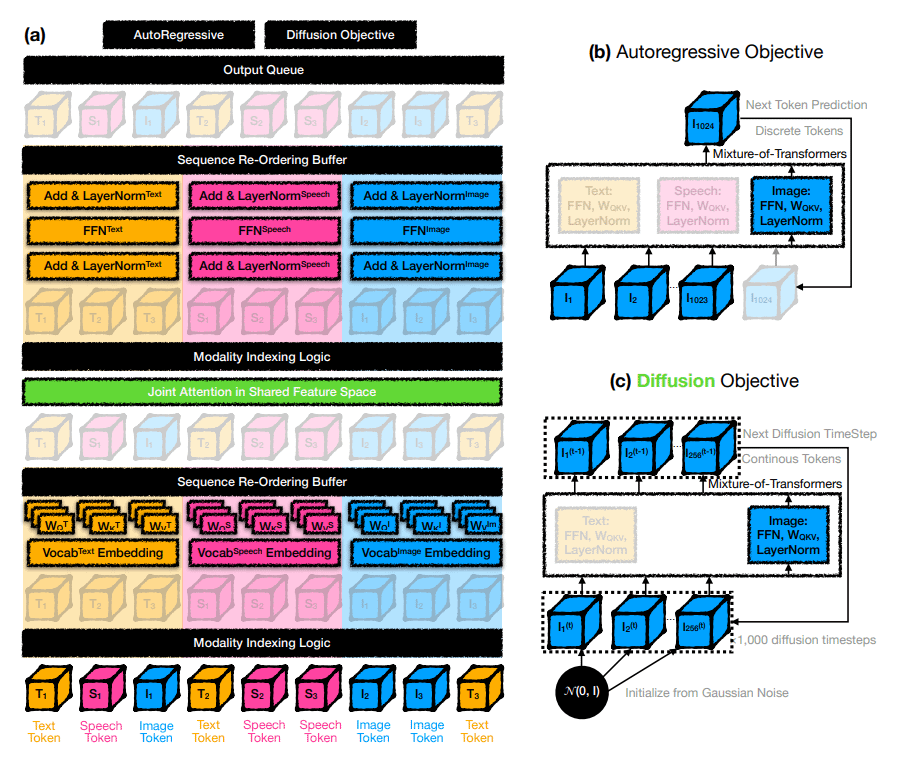
Mixture-of-Transformers (MoT) is a new @AIatMeta and @Stanford's MLLM design for efficient training of MLLMs using less computing power. It uses specific networks for each type of input: text, images, and speech, while still sharing attention across all the data. 👇 https://t.co/nYdDECRnOR