Your curated collection of saved posts and media
■ #Fintech needs #Capital and trust for #women, not more #diversity panels https://t.co/uY1QoZQSTw #Finserv #data #VentureCapital @sallyeaves @SpirosMargaris @ahier @BetaMoroney @Khulood_Almani @efipm @YuHelenYu @Shi4Tech @FrRonconi @CurieuxExplorer @BetaMoroney @NeiraOsci @JimMarous @MHcommunicate @enricomolinari @Fabriziobustama @enilev @FinMKTG @HaroldSinnott @kalydeoo @dinisguarda @AkwyZ @globaliqx @Eli_Krumova

Warren Buffett isn’t just the best investor in the world, he’s in a league of his own. Imagine investing $10,000 in Berkshire Hathaway back in 1965… Today, that would be worth over $2 billion (!) Here are 100 of his most powerful investing quotes: https://t.co/4GtKpBjjr0

Is AI really trying to escape human control and blackmail people? https://t.co/AzXnZ4tTS5 @arstechnica @benjedwards

DeepSeek’s next AI model delayed by attempt to use Chinese chips https://t.co/9GywF2CrIB @EleanorOlcott @ft

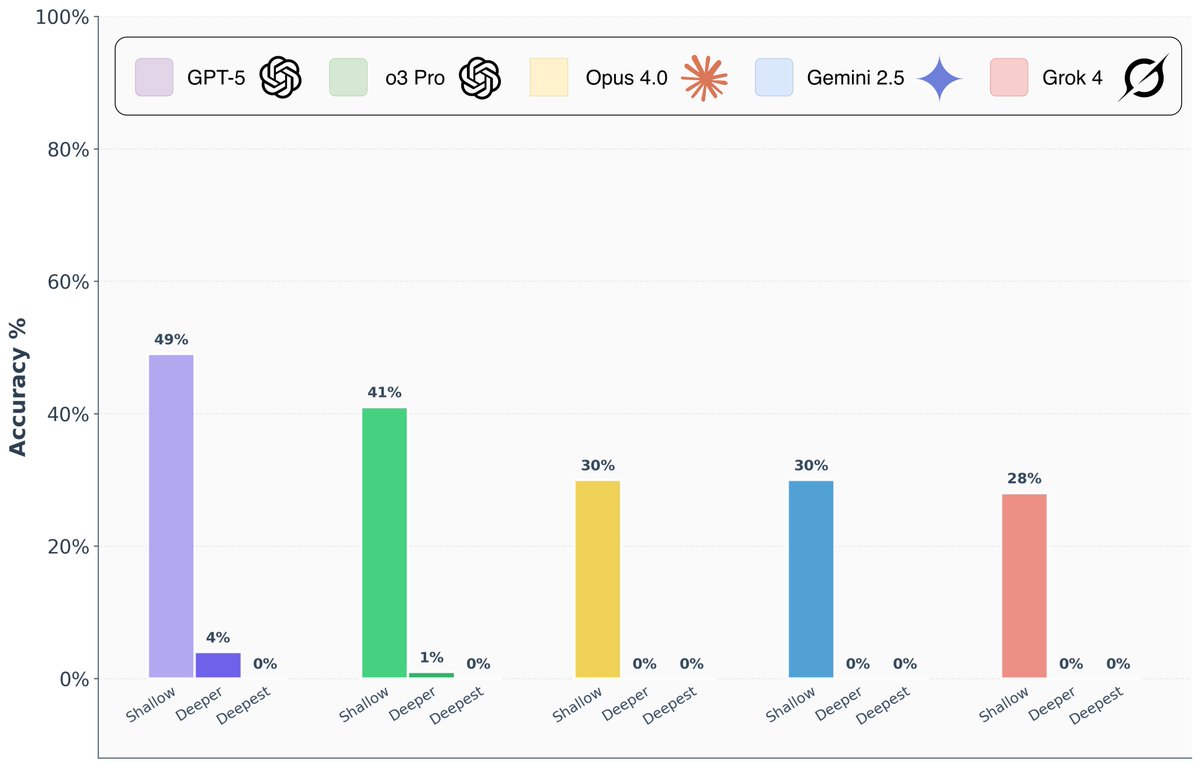
Are frontier AI models really capable of “PhD-level” reasoning? To answer this question, we introduce FormulaOne, a new reasoning benchmark of expert-level Dynamic Programming problems. We have curated a benchmark consisting of three tiers, in increasing complexity, which we call ‘shallow’, ‘deeper’, ‘deepest’. The results are remarkable: - On the ‘shallow’ tier, top models reach performance of 50%-70%, indicating that the models are familiar with the subject matter. - On ‘deeper’, Grok 4, Gemini-Pro, o3-Pro, Opus-4 all solve at most 1/100 problems. GPT-5 Pro is significantly better, but still solves only 4/100 problems. - On ‘deepest’, all models collapse to 0% success rate. 🧵
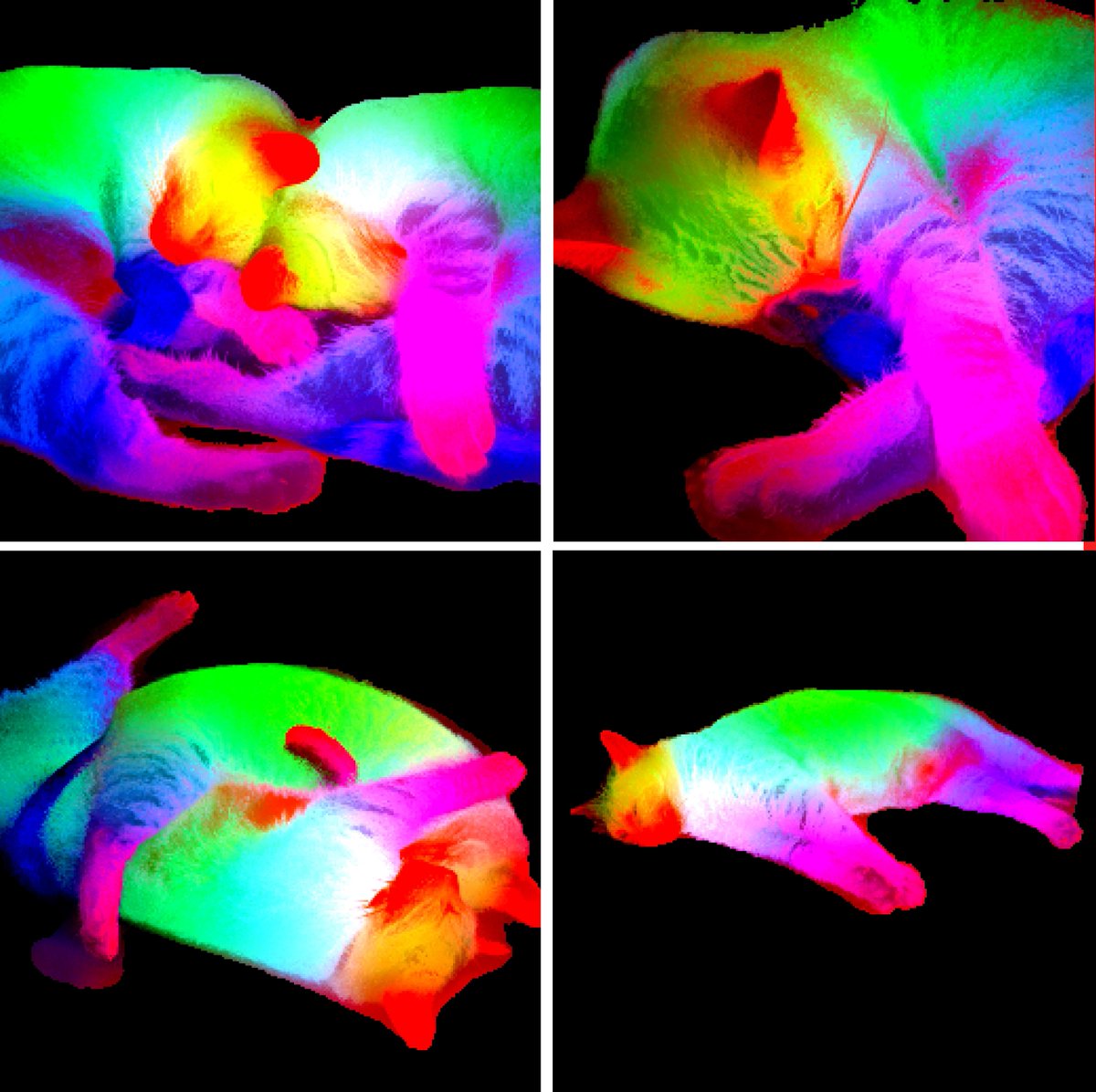
Introducing DINOv3 🦕🦕🦕 A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale. High quality dense features, combining unprecedented semantic and geometric scene understanding. Three reasons why this matters… https://t.co/kOajLhcBi9
As part of our exploratory work on potential model welfare, we recently gave Claude Opus 4 and 4.1 the ability to end a rare subset of conversations on https://t.co/uLbS2JNczH. https://t.co/O6WIc7b9Jp

The global quantum race is accelerating, and by 2030 the distinction between quantum computing companies and post-quantum technology providers will likely dissolve. Instead, they will form a single integrated ecosystem—from quantum hardware and algorithms to post-quantum cryptography and semiconductor security. •Quantum leaders like IonQ, Rigetti, D-Wave, and QCI are racing to achieve practical, scalable quantum processors for computation and optimization. •Post-quantum players like SEALSQ provide the cryptographic and semiconductor backbone required to secure data, devices, and communications in a world where quantum attacks threaten today’s encryption. Critically, in terms of revenue evolution, it is expected that post-quantum security providers will grow faster in the short-to-medium term. The urgency comes from the industry’s need to acquire quantum-resistant technology now to prevent vulnerabilities that could emerge within the next five years as adversaries prepare for “harvest now, decrypt later” attacks. ________________________________________ 2025 Revenue & Valuation Comparison among Quantum players Company2025 Revenue Projection2025 ValuationStrategic Role by 2030 (Quantum/Post-Quantum Ecosystem) IonQ (IONQ)~$82–100M~$12.2BLeader in trapped-ion quantum hardware; expected to dominate commercial cloud quantum services and hybrid AI+Quantum workloads. D-Wave (QBTS)~$24–25M~$6.2BPioneer in quantum annealing; positioned for optimization use-cases in logistics, AI, and material science. Rigetti (RGTI)~$8.8M~$5.8BDeveloper of superconducting gate-based qubits; focus on scaling qubit fidelity and hybrid HPC-quantum integration. Quantum Computing Inc. (QCI/QUBT)~$10–12M*~$350–400M*Focused on quantum-ready software and photonic-based quantum systems; strong in making quantum resources accessible to enterprises. (*analyst estimates). SEALSQ (LAES)~$16–20M~$415–424MFocused on post-quantum cryptography and quantum software using a “picks and shovels during the Gold Rush” model. Rather than building a full quantum computer at this stage, SEALSQ provides essential cybersecurity hardware and middleware that enable secure integration between quantum and conventional systems. On the roadmap: entry into AI-powered quantum computer development, positioning SEALSQ to evolve from enabler to direct competitor in quantum hardware. Key Insight By 2030, quantum and post-quantum firms will converge: •Hardware & algorithms (IonQ, Rigetti, D-Wave, QCI) will deliver raw quantum capabilities. •Security, middleware, and semiconductor integration (SEALSQ and peers) will safeguard and operationalize the ecosystem. •In the short term (next 5 years), post-quantum security is expected to drive revenue growth first, as enterprises and governments urgently deploy PQC to protect against looming threats. •@SEALSQcorp $LAES, in particular, positions itself as a critical enabler: selling the equivalent of “shovels” in the Gold Rush—indispensable hardware and software for running and securing quantum systems—while keeping an eye on AI-driven quantum computing as its long-term play.
What if your baby never walks? What if they are never able to live independently? What if you could have stopped it… but chose not to? That’s the question @OrchidInc’s embryo screening forces. You optimize everything… career, diet, skincare… but you’re going to chance it on your child’s genome, one of the most significant determinants of their health?
35% off our evals course: https://t.co/whBkfSUz6m Link to YT video: https://t.co/idPaNL6Vxt


The beatings (free books) will continue until everyone looks at their data: 1. LLM Evals FAQ: https://t.co/BzEHwvobz5 2. Beyond Naive RAG: Practical Advanced Methods https://t.co/x2870kdHoZ

Water Ico sphere #b3d #blender https://t.co/g6LFAh9cFv
Water Ico sphere #b3d #blender https://t.co/g6LFAh9cFv
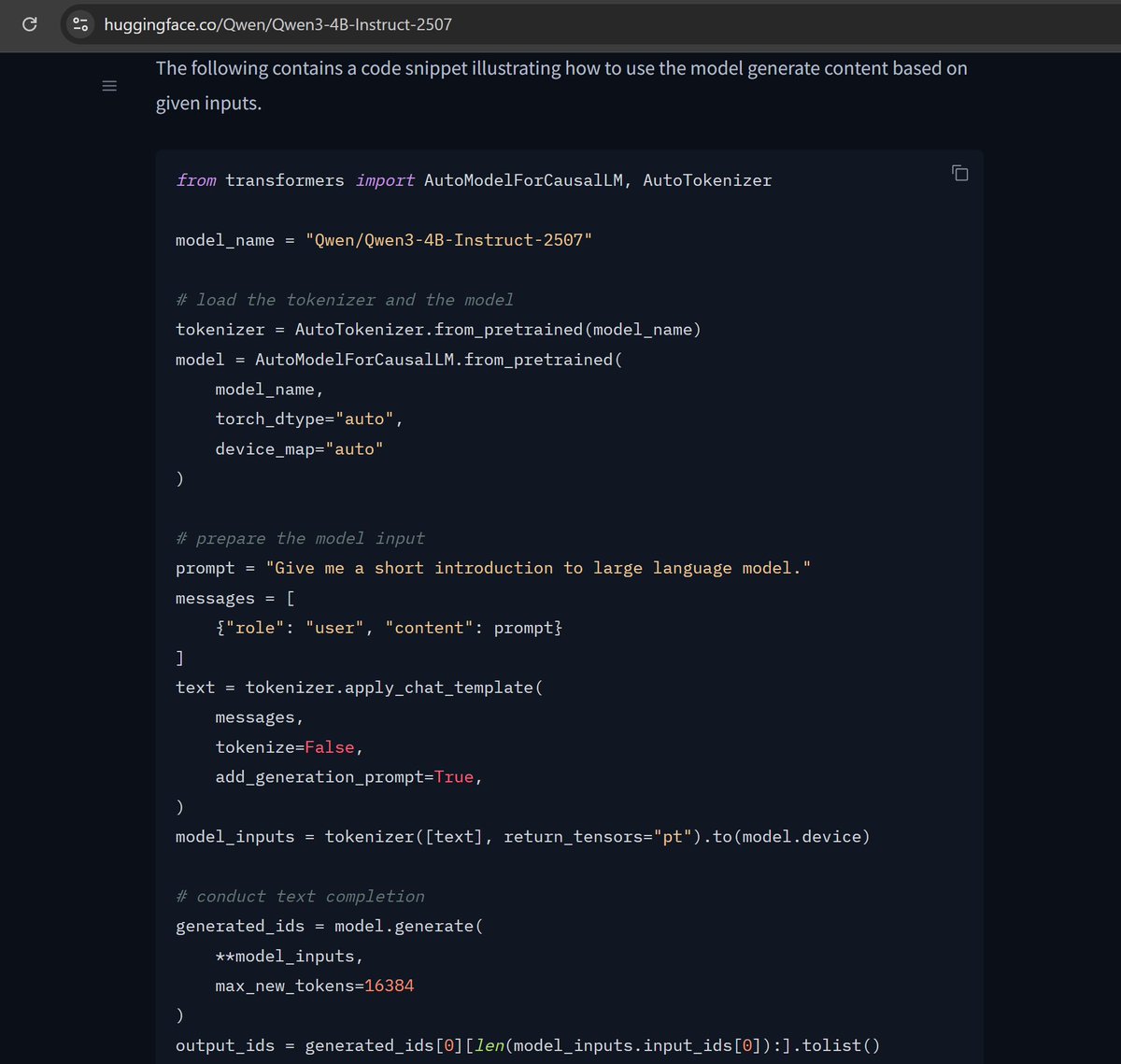
If I paste the demo code from the HF model page, model.generate takes 12.5 s to generate 100 tokens on my 3090. Feels ~10X too slow for a 4B model! Is this just the state of hf's default generate vs optimized inference things or am I missing something obvious? https://t.co/s1wVNvmsOb
Detailed post here: https://t.co/kTEHGBsaOi

Important point from Deep Learning with Python... https://t.co/dsYebeDVG4

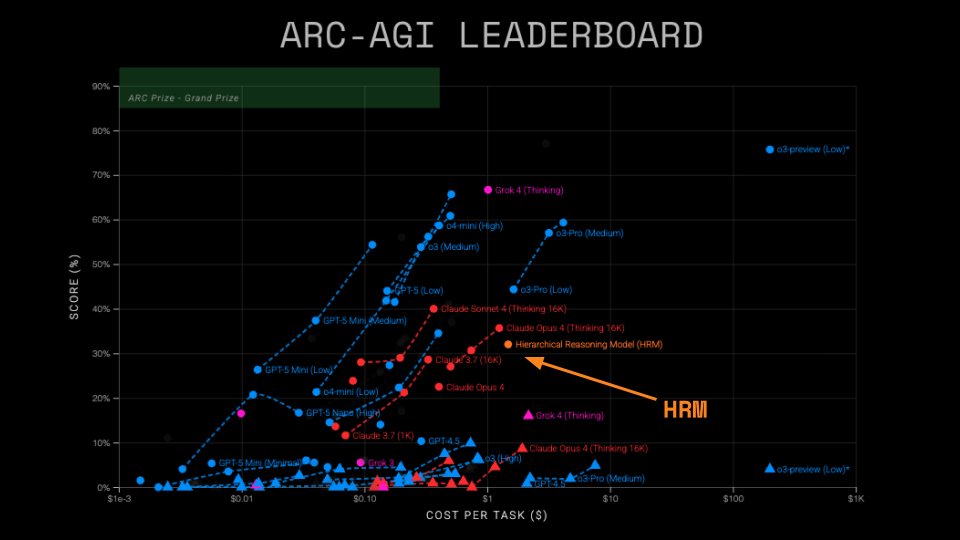
Analyzing the Hierarchical Reasoning Model by @makingAGI We verified scores on hidden tasks, ran ablations, and found that performance comes from an unexpected source ARC-AGI Semi Private Scores: * ARC-AGI-1: 32% * ARC-AGI-2: 2% Our 4 findings: https://t.co/hVBsio83g7
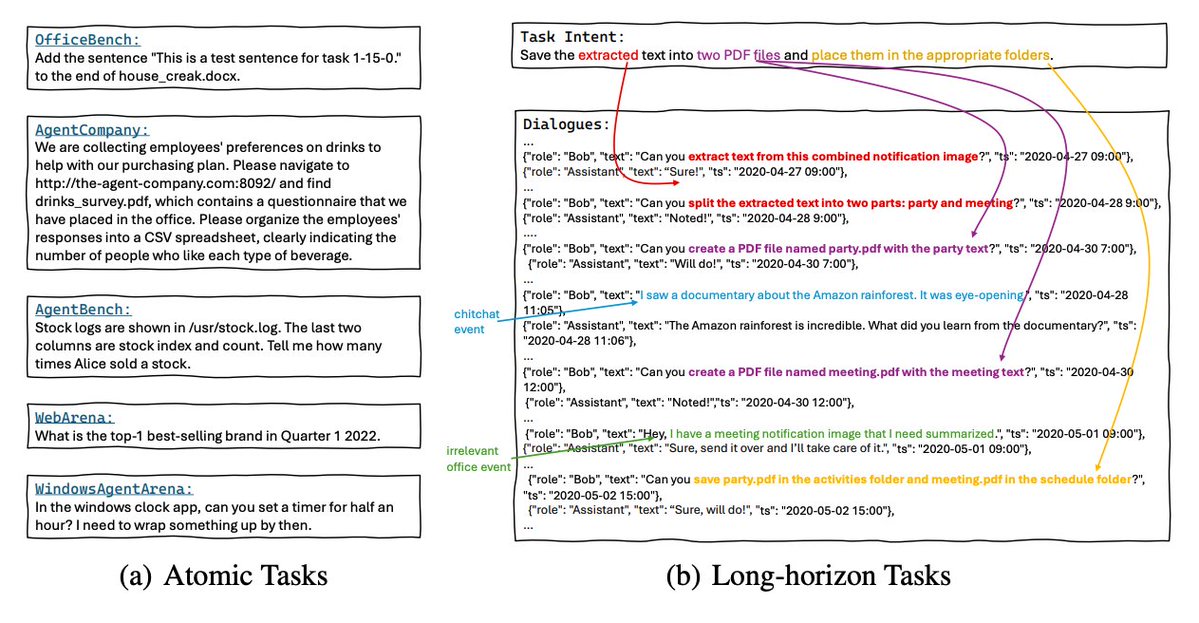
AI Agents are terrible at long-horizon tasks. Even the new GPT-5 model struggles with long-horizon tasks. This is one of the most pressing challenges when building AI agents. Pay attention, AI devs! This is a neat paper that went largely unnoticed. Here are my notes: https://t.co/aAmrJxlQLx

What's new? The work presents a new benchmark and data‑generation pipeline to test agents on realistic, multi‑day office tasks across Word, Excel, PDF, Email, and Calendar. OdysseyBench targets long‑horizon, context‑dependent workflows instead of atomic tasks. Two splits: OdysseyBench+ (300 tasks distilled from real OfficeBench cases) and OdysseyBench‑Neo (302 newly synthesized, more complex tasks). Tasks require retrieving key facts from multi‑day dialogues and coordinating actions across apps.
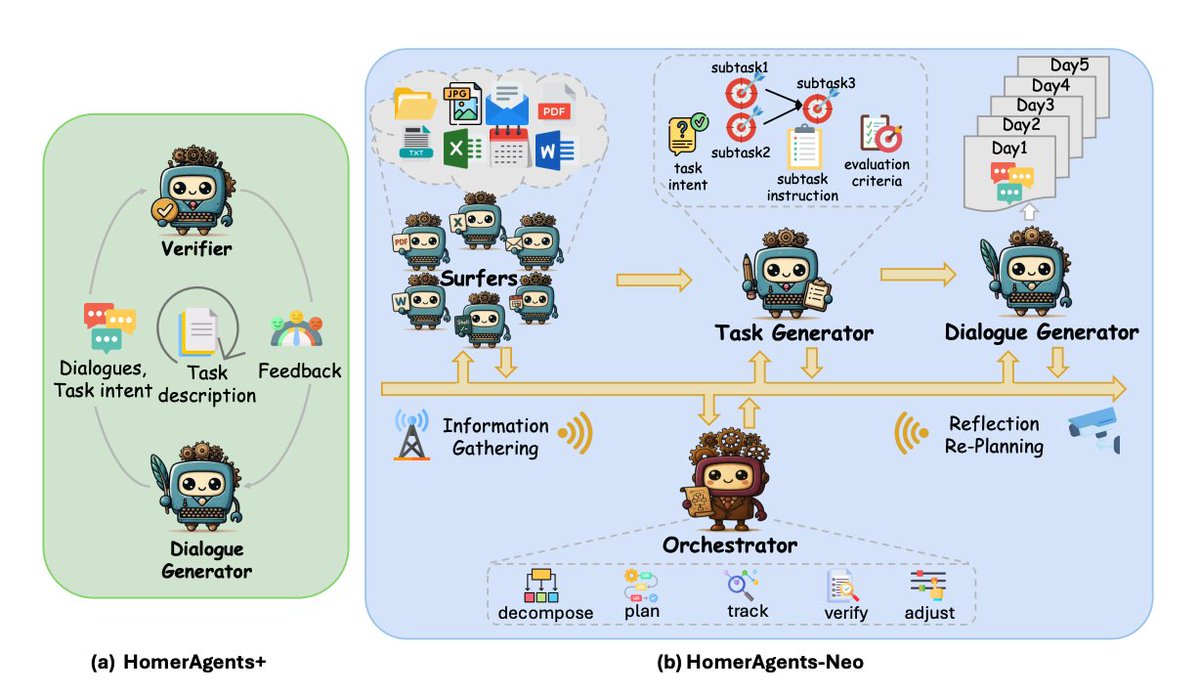
How it’s built The authors propose HOMERAGENTS, a multi-agent framework that automates the generation of long-horizon workflow benchmarks. HOMERAGENTS has two paths: HOMERAGENTS+ iteratively turns atomic OfficeBench items into rich multi‑day dialogues via a generator‑verifier loop. This leads to OdysseyBench+. HOMERAGENTS‑NEO, which explores an app environment, generates tasks (intent, subtasks, eval criteria), and then synthesizes 5‑day dialogues. All agents use GPT‑4.1; at least five calendar days of dialogue are produced per task.
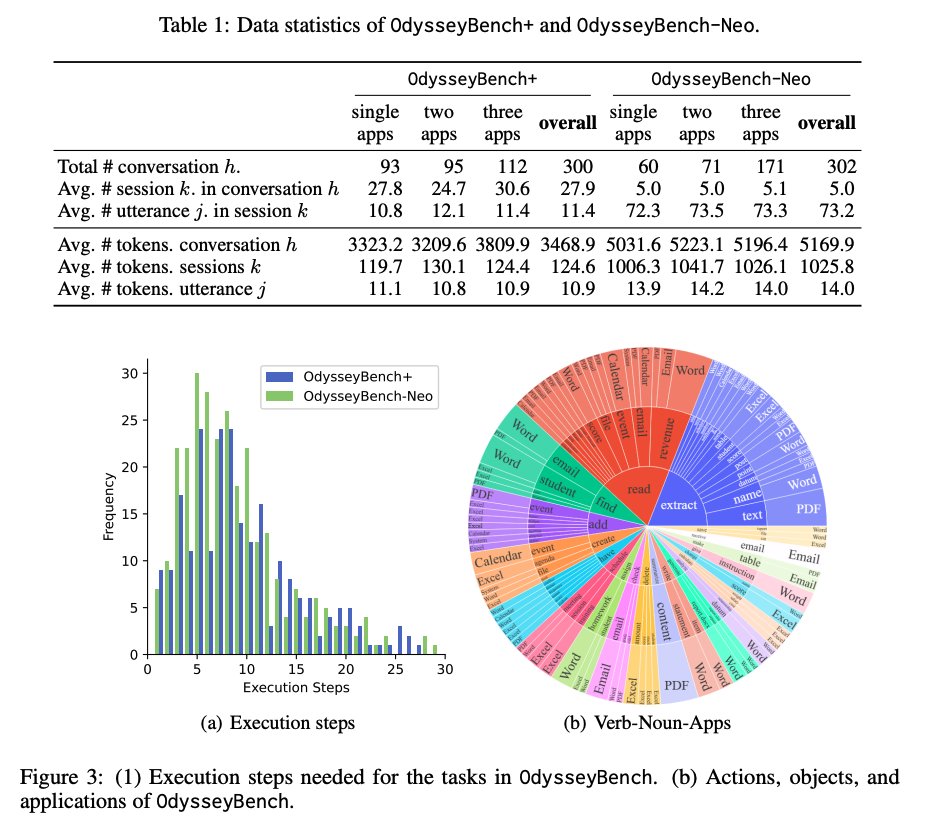
Data & Evaluation 602 total tasks: 153 single‑app, 166 two‑app, 283 three‑app. Neo conversations are longer and denser (≈49% more tokens) than Plus. Execution steps cluster around 3–15. Automated checks (exact/fuzzy/execution‑based) compute pass rate after running agents inside a Dockerized office stack; LLM‑judge and human curation raise data quality.
Main Results Performance drops as apps increase; even top models struggle on 3‑app tasks. Example: on OdysseyBench+, o3 goes 72.83%→30.36% from 1‑app to 3‑app; GPT‑4.1 goes 55.91%→12.50%. Humans exceed 90% across settings. RAG with semantic summaries beats raw retrieval at far lower token budgets; chunk‑level summaries reach ≈56% on Neo vs. 52% long‑context with ~20% tokens. Execution steps remain similar or shrink with summarized memory.
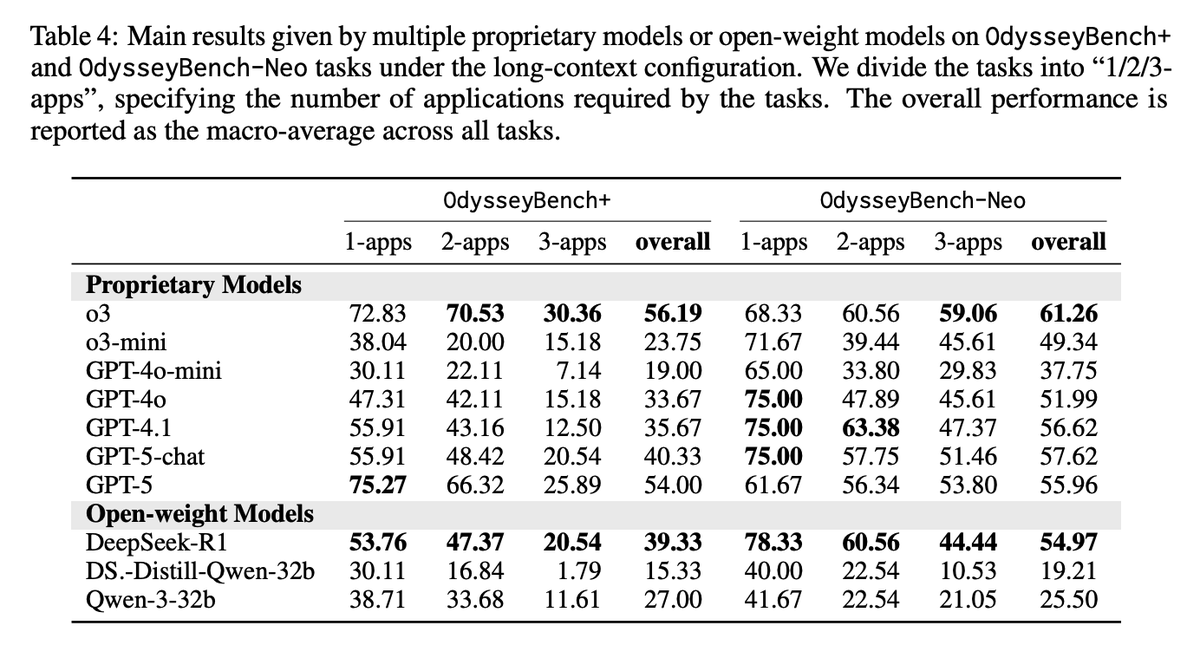
Semantic compression beats raw long context Chunk-level summaries in RAG not only matched or outperformed long-context baselines but did so with ~20% of the tokens. Well-structured summarization improves retrieval precision, reduces noise, and can even shorten execution steps. This is useful to build more efficient, accurate long-horizon agents.
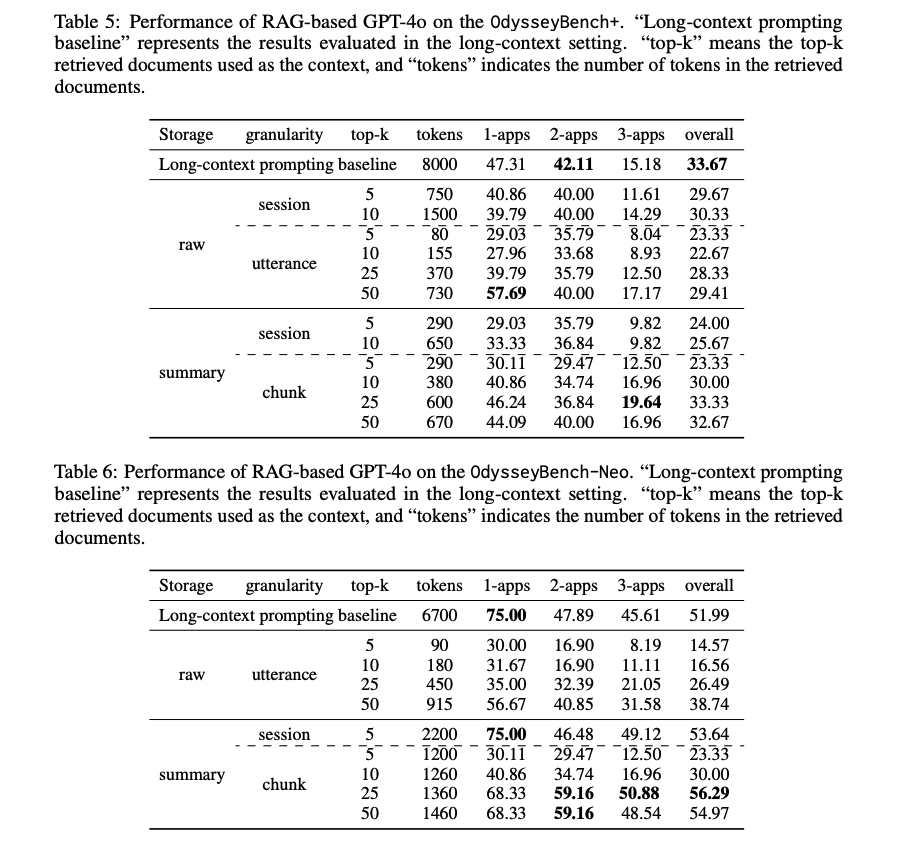
Where Agents Fail Typical errors include missing referenced files, skipping required actions, wrong tool choice (e.g., trying to “create PDF” directly instead of writing in Word, then converting), and poor planning order. File creation/editing in docx/xlsx is particularly error‑prone. The authors argue that semantic compression and coherent aggregation are essential for multi‑step reasoning in long contexts. Paper: https://t.co/YPZinw0uiy


The OpenAI Playground has improved a lot recently. I've been using it to test GPT-5 on new use cases. Watch how I use it to chat with internal docs via MCP tools. It uses the vector store feature too. Testing out the Prompt Optimizer and Evaluation features next. https://t.co/lpYFoVPqlR
Build multimodal AI applications that can analyze both text and images for market research and surveys 📊 🔍 Process images and documents together in a unified AI pipeline 📈 Extract insights from visual market data like charts, graphs, and product images 🤖 Combine multimodal analysis with LlamaParse Check out the complete multimodal market survey notebook: https://t.co/cDJt3xls3o

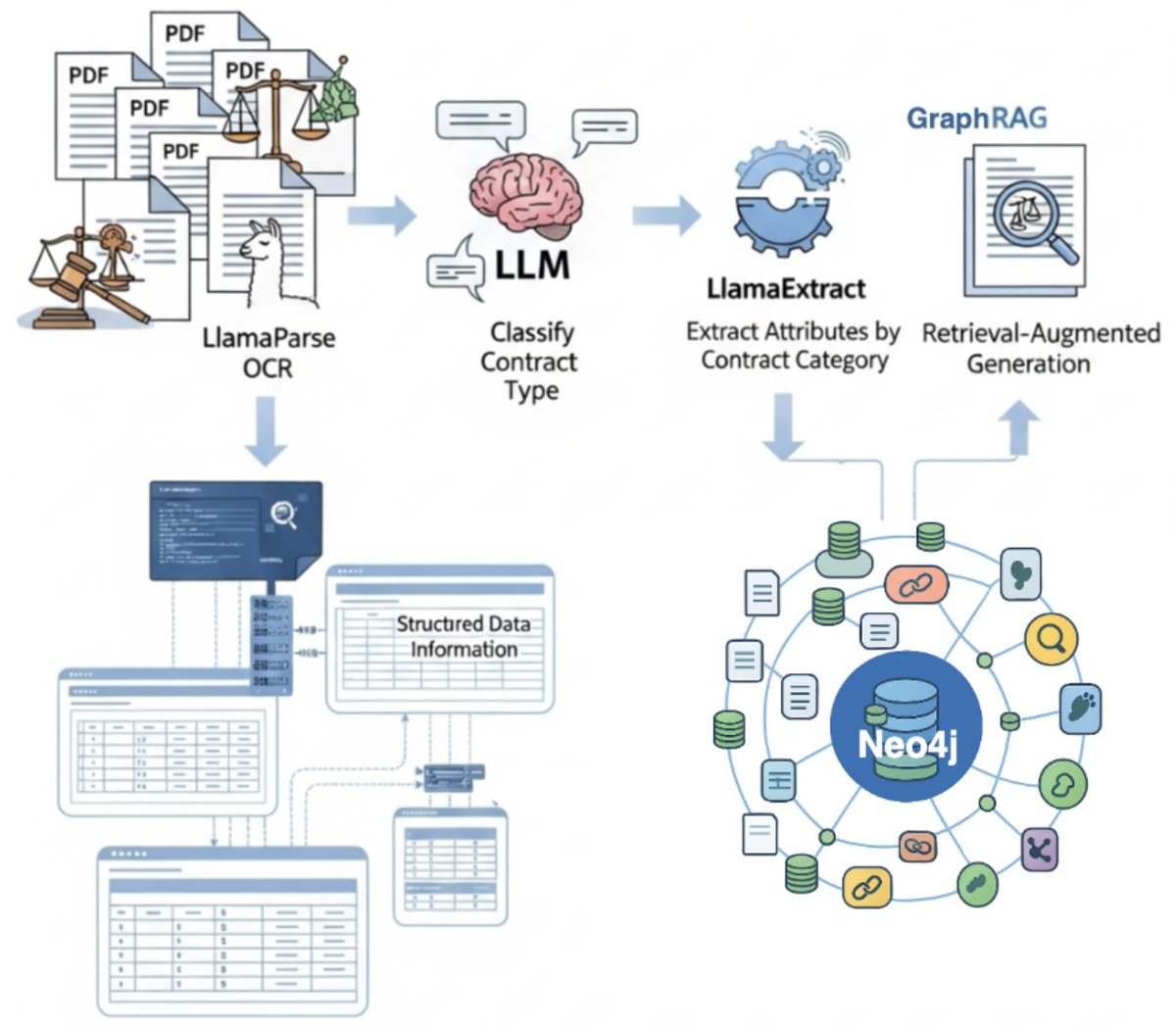
Transform unstructured legal documents into queryable knowledge graphs that understand not just content, but relationships between entities. This comprehensive tutorial shows you how to build a knowldedge graph creation workflow using LlamaCloud and @neo4j for legal contract processing: 📄 Use LlamaParse to extract clean text from PDF documents, even complex legal contracts 🤖 Classify contract types using an LLM to enable context-aware processing 🔍 Extract structured data with LlamaExtract, tailoring extraction schemas to each contract category 🕸️ Store everything in @neo4j as a rich knowledge graph that captures intricate relationships between parties, locations, and contract terms The tutorial includes complete code for building an agentic workflow that processes contracts from PDF to knowledge graph in a single pipeline. Check out the full cookbook: https://t.co/gS7Q1trda8
@anxious599 You might like https://t.co/j3Knzj7TGW
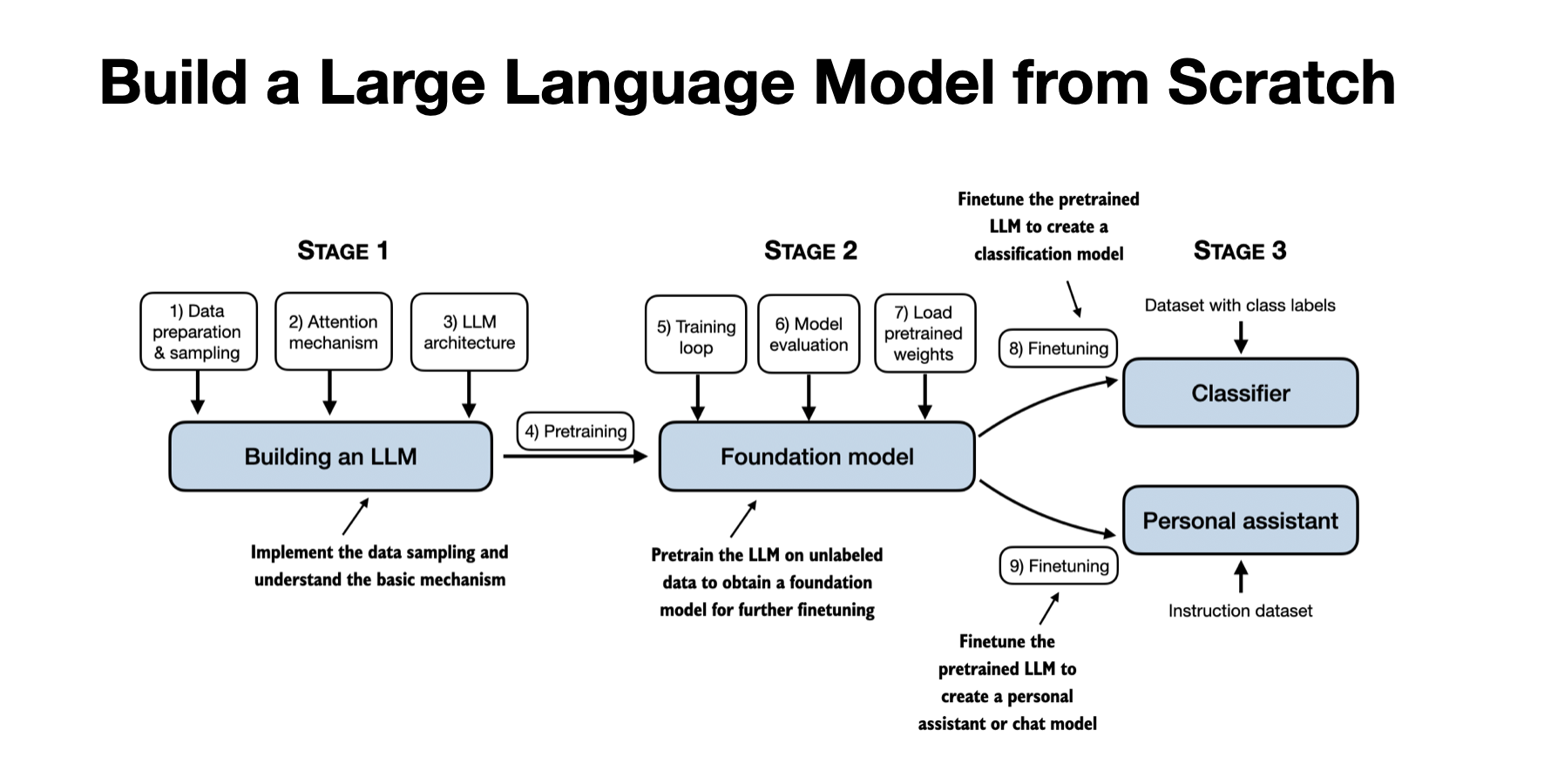
https://t.co/AGF30FctjV

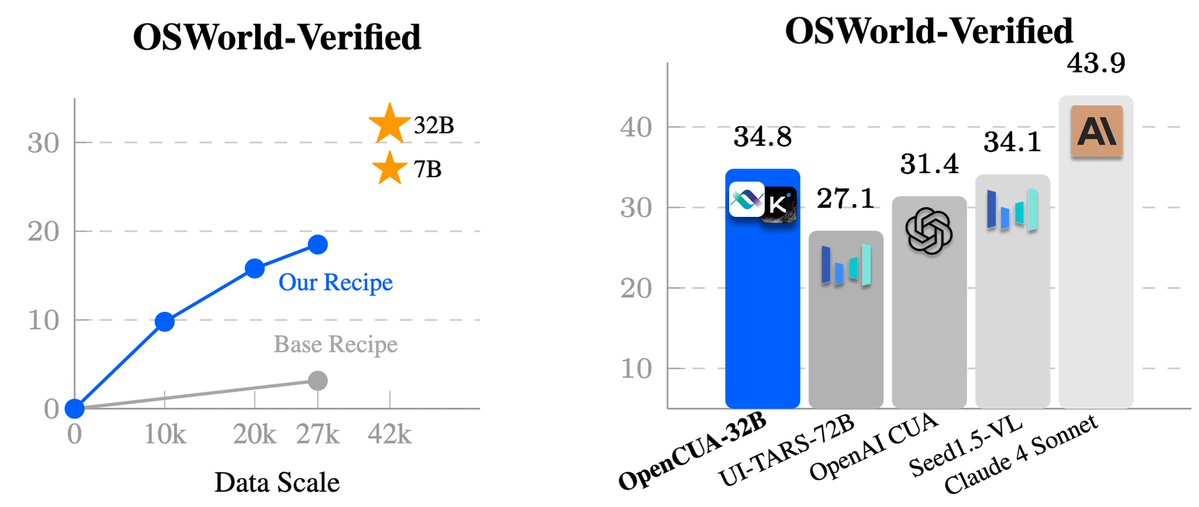
We are super excited to release OpenCUA — the first from 0 to 1 computer-use agent foundation model framework and open-source SOTA model OpenCUA-32B, matching top proprietary models on OSWorld-Verified, with full infrastructure and data. 🔗 [Paper] https://t.co/SYEio5ccNJ 📌 [Website] https://t.co/ma6bBuYiNM 🤖 [Models] https://t.co/7TVtIdjkmq 📊[Data] https://t.co/N6tQQwQkhs 💻 [Code] https://t.co/ihr8TXmG6k 🌟 OpenCUA — comprehensive open-source framework for computer-use agents, including: 📊 AgentNet — first large-scale CUA dataset (3 systems, 200+ apps & sites, 22.6K trajectories) 🏆 OpenCUA model — open-source SOTA on OSWorld-Verified (34.8% avg success, outperforms OpenAI CUA) 🖥 AgentNetTool — cross-system computer-use task annotation tool 🏁 AgentNetBench — offline CUA benchmark for fast, reproducible evaluation 💡 Why OpenCUA? Proprietary CUAs like Claude or OpenAI CUA are impressive🤯 — but there’s no large-scale open desktop agent dataset or transparent pipeline. OpenCUA changes that by offering the full open-source stack 🛠: scalable cross-system data collection, effective data formulation, model training strategy, and reproducible evaluation — powering top open-source models including OpenCUA-7B and OpenCUA-32B that excel in GUI planning & grounding. Details of OpenCUA framework👇

Part II of GPU Puzzles is here! Welcome to the detective work of GPU programming: debugging.🕵️ Puzzle 9 walks through the debugging workflow + 3 common issues, while Puzzle 10 teaches you to use @NVIDIA's compute-sanitizer to find and fix race conditions: https://t.co/PN3qxd7AqM

I vibe-checked my RAG apps. But recently I took @jxnlco's Systematically Improving RAG course and learned more about retrieval recall, segmentation, fine-tuning, product design. Now I have a repeatable improvement loop, not guesswork. Highly recommend: https://t.co/RdoVg81YHr
