@maxseitzer
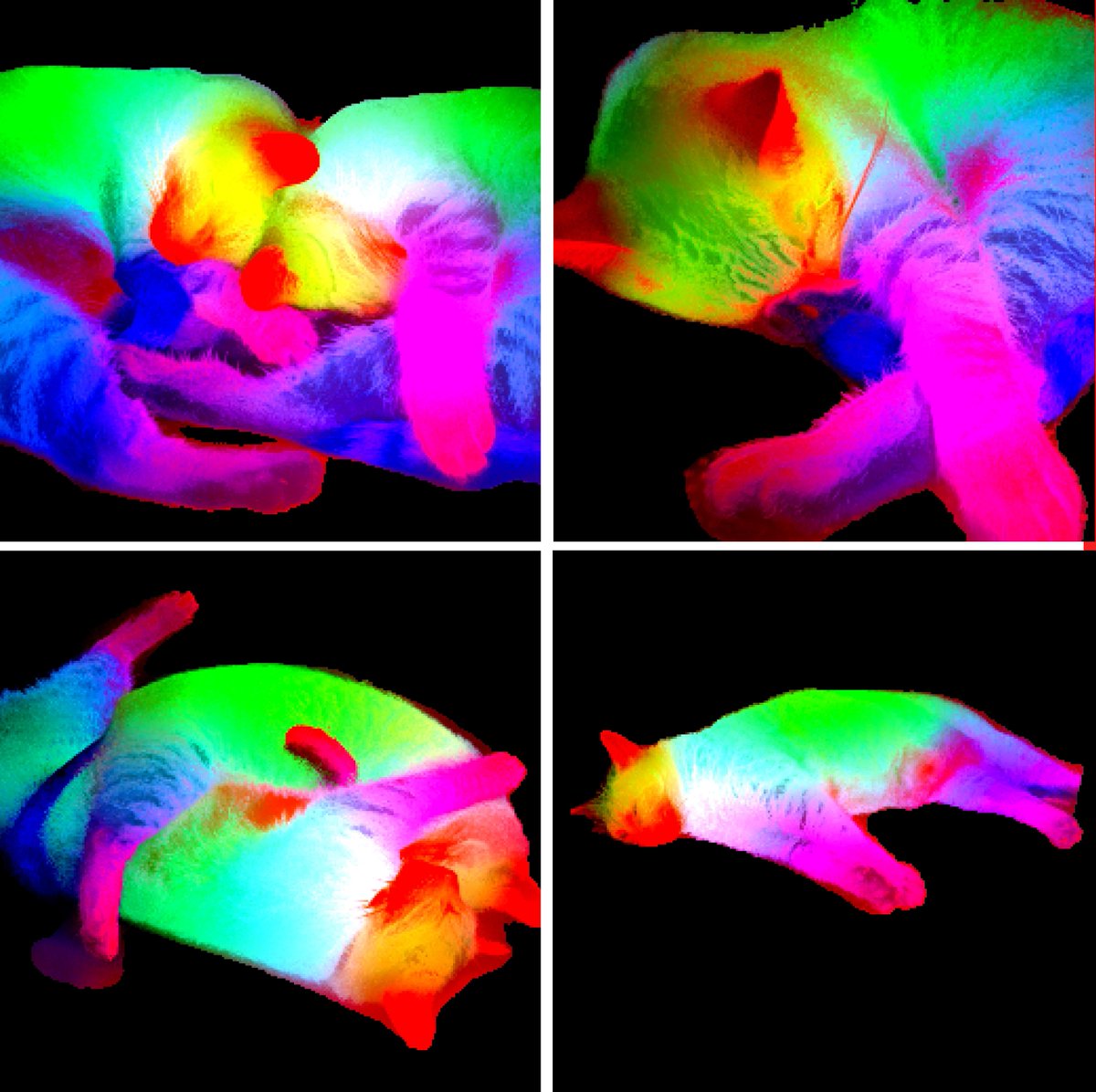
Introducing DINOv3 🦕🦕🦕 A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale. High quality dense features, combining unprecedented semantic and geometric scene understanding. Three reasons why this matters… https://t.co/kOajLhcBi9