@llama_index
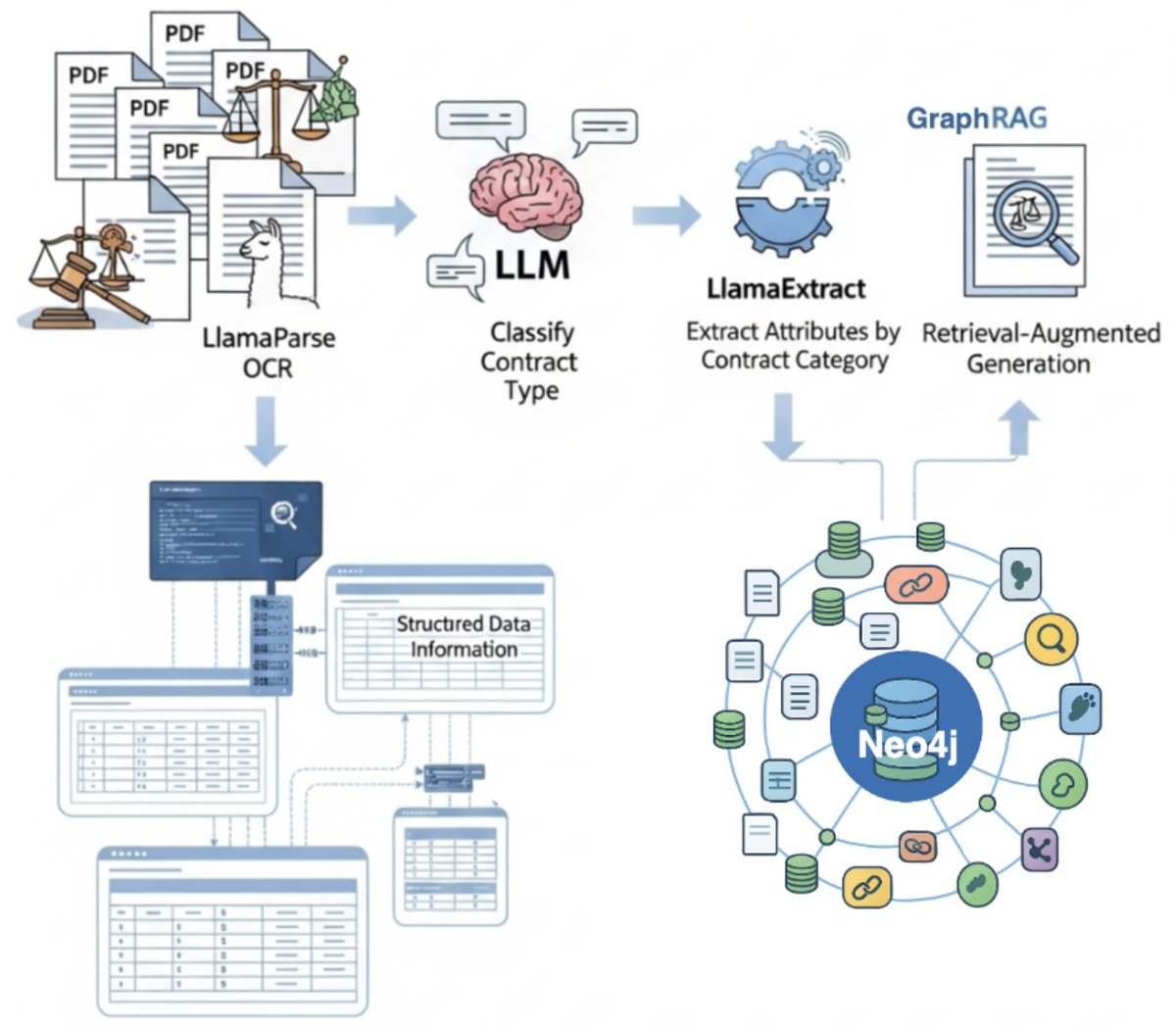
Transform unstructured legal documents into queryable knowledge graphs that understand not just content, but relationships between entities. This comprehensive tutorial shows you how to build a knowldedge graph creation workflow using LlamaCloud and @neo4j for legal contract processing: 📄 Use LlamaParse to extract clean text from PDF documents, even complex legal contracts 🤖 Classify contract types using an LLM to enable context-aware processing 🔍 Extract structured data with LlamaExtract, tailoring extraction schemas to each contract category 🕸️ Store everything in @neo4j as a rich knowledge graph that captures intricate relationships between parties, locations, and contract terms The tutorial includes complete code for building an agentic workflow that processes contracts from PDF to knowledge graph in a single pipeline. Check out the full cookbook: https://t.co/gS7Q1trda8