@omarsar0
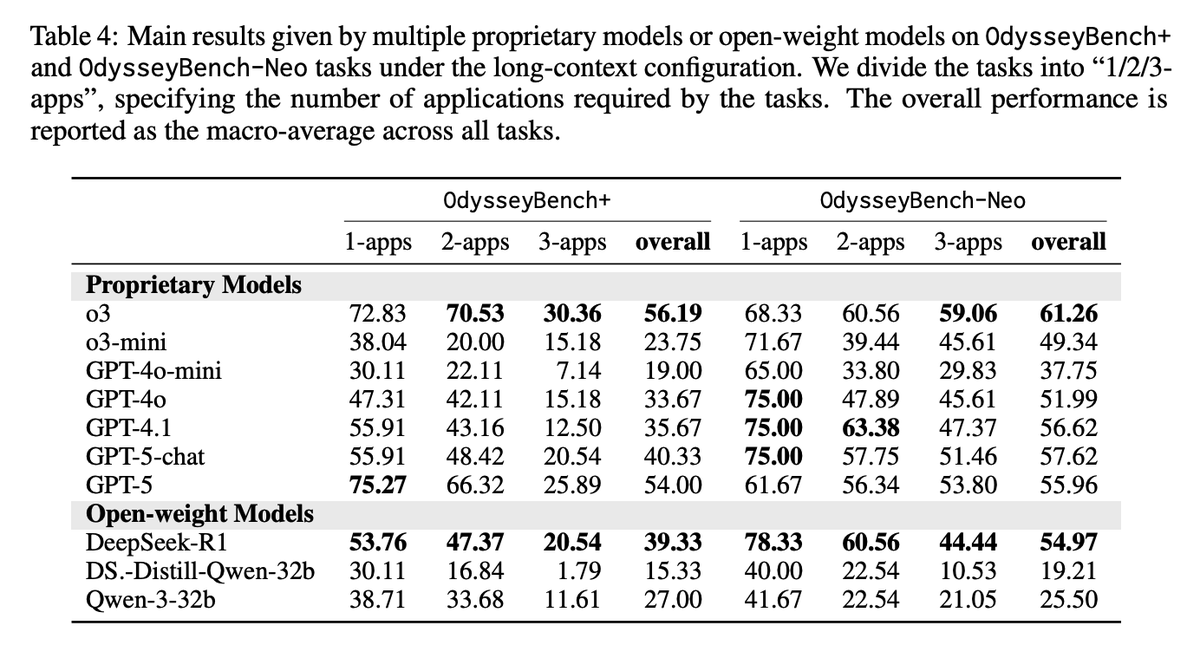
Main Results Performance drops as apps increase; even top models struggle on 3‑app tasks. Example: on OdysseyBench+, o3 goes 72.83%→30.36% from 1‑app to 3‑app; GPT‑4.1 goes 55.91%→12.50%. Humans exceed 90% across settings. RAG with semantic summaries beats raw retrieval at far lower token budgets; chunk‑level summaries reach ≈56% on Neo vs. 52% long‑context with ~20% tokens. Execution steps remain similar or shrink with summarized memory.