@johnowhitaker
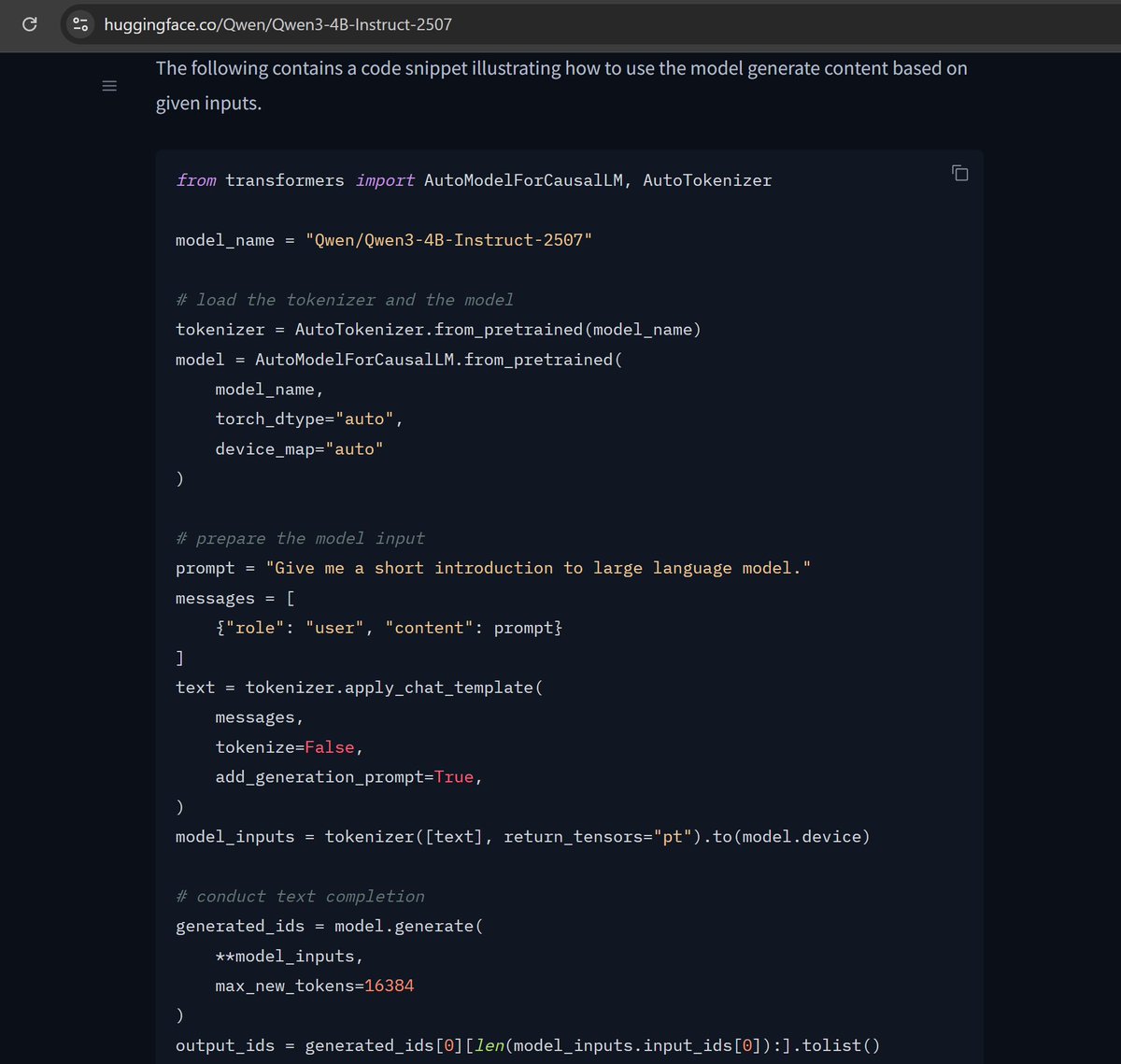
If I paste the demo code from the HF model page, model.generate takes 12.5 s to generate 100 tokens on my 3090. Feels ~10X too slow for a 4B model! Is this just the state of hf's default generate vs optimized inference things or am I missing something obvious? https://t.co/s1wVNvmsOb