Your curated collection of saved posts and media
Meet Gemma 4: our new family of open models you can run on your own hardware. Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵

We just released Gemma 4 — our most intelligent open models to date. Built from the same world-class research as Gemini 3, Gemma 4 brings breakthrough intelligence directly to your own hardware for advanced reasoning and agentic workflows. Released under a commercially permissive Apache 2.0 license so anyone can build powerful AI tools. 🧵↓
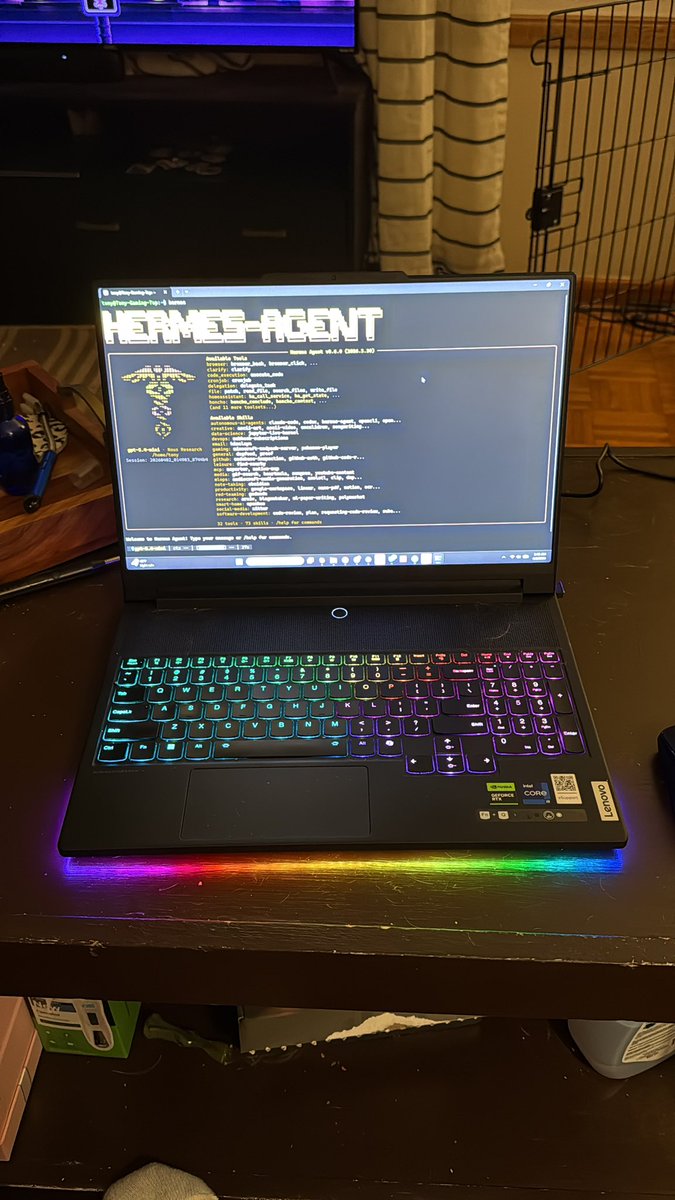
After using @NousResearch Hermes Agent the past couple of weeks, I can confidently say this is the first AI agent platform I would be willing to market and distribute as a professional install and setup service for clients. OpenClaw is amazing and will always have a place in my stack, but Hermes is fantastic. And I hate to say this, but there’s a pretty big gap. I don’t doubt OpenClaw will continue to evolve and get more awesome. I’ll be there every step of the way. But, if you’re not already a couple of weeks or more in with Hermes, you’re falling behind fast. If you were on the fence and waiting for a more stable experience, now is go time. Step into the future! 🤘🏻🔥
We also overhauled the docs — new guides for GRPO training, vLLM serving, training stability, debugging, and agent-specific workflows. Full release notes: https://t.co/iL9iaBUuzm Docs: https://t.co/7FS3EQTuxs pip install axolotl==0.16.0

Do Phone-Use Agents Respect Your Privacy? paper: https://t.co/1yGuE9cpl6 https://t.co/gZWQoTPASr


Gemma 4 is out on Hugging Face blog: https://t.co/WNGzOPfUJ2 https://t.co/FnVMPNLBzG


Let's go! https://t.co/HakmkNzDT2


So happy to see Google release Gemma 4 today in apache 2.0 that gives you frontier capabilities locally. You can use it right away in all your favorite open agent platforms like openclaw, opencode, pi, Hermes by asking it to change your model to local gemma 4 with llama-server. Local AI is having its moment and we’re here for it!

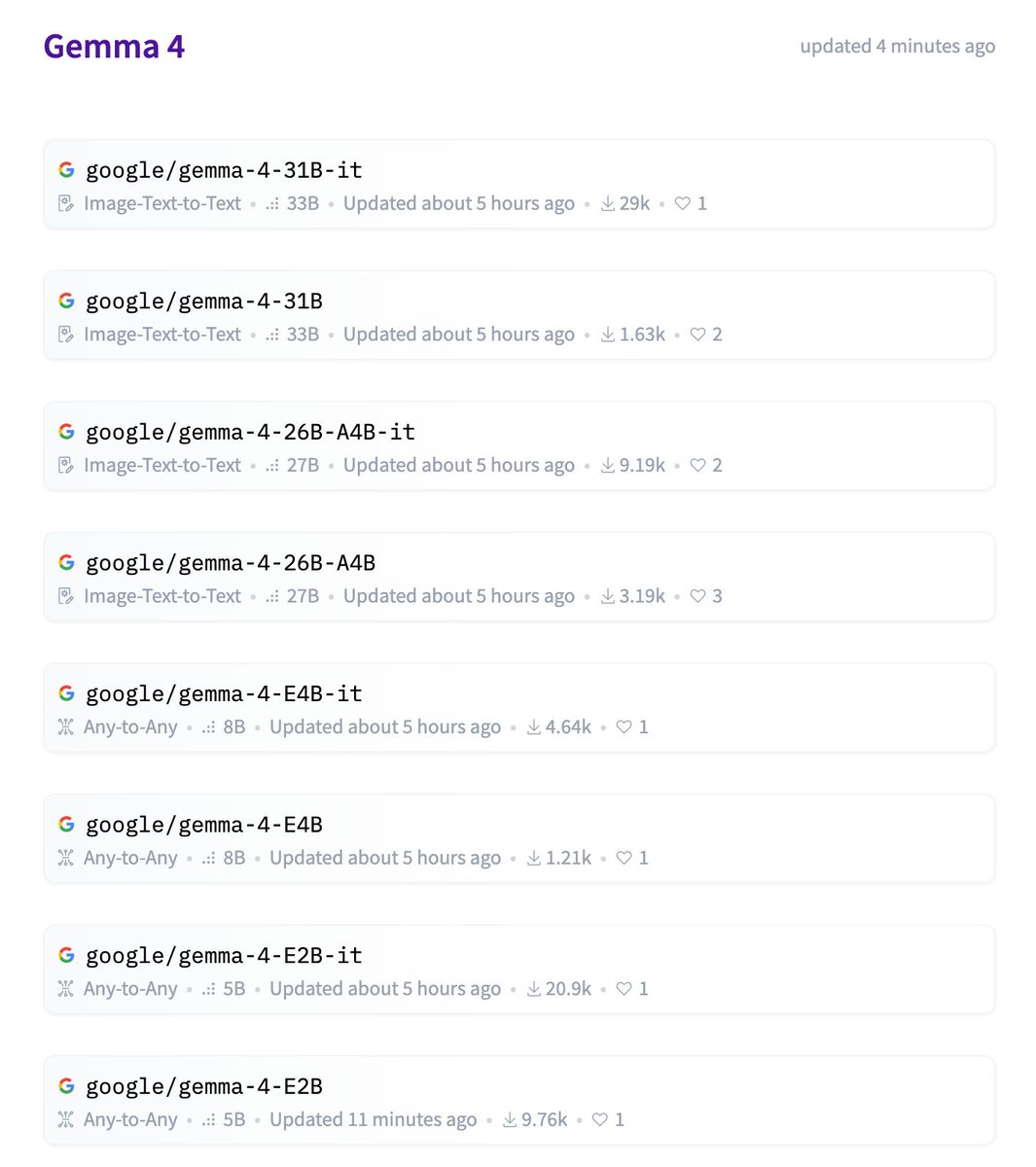
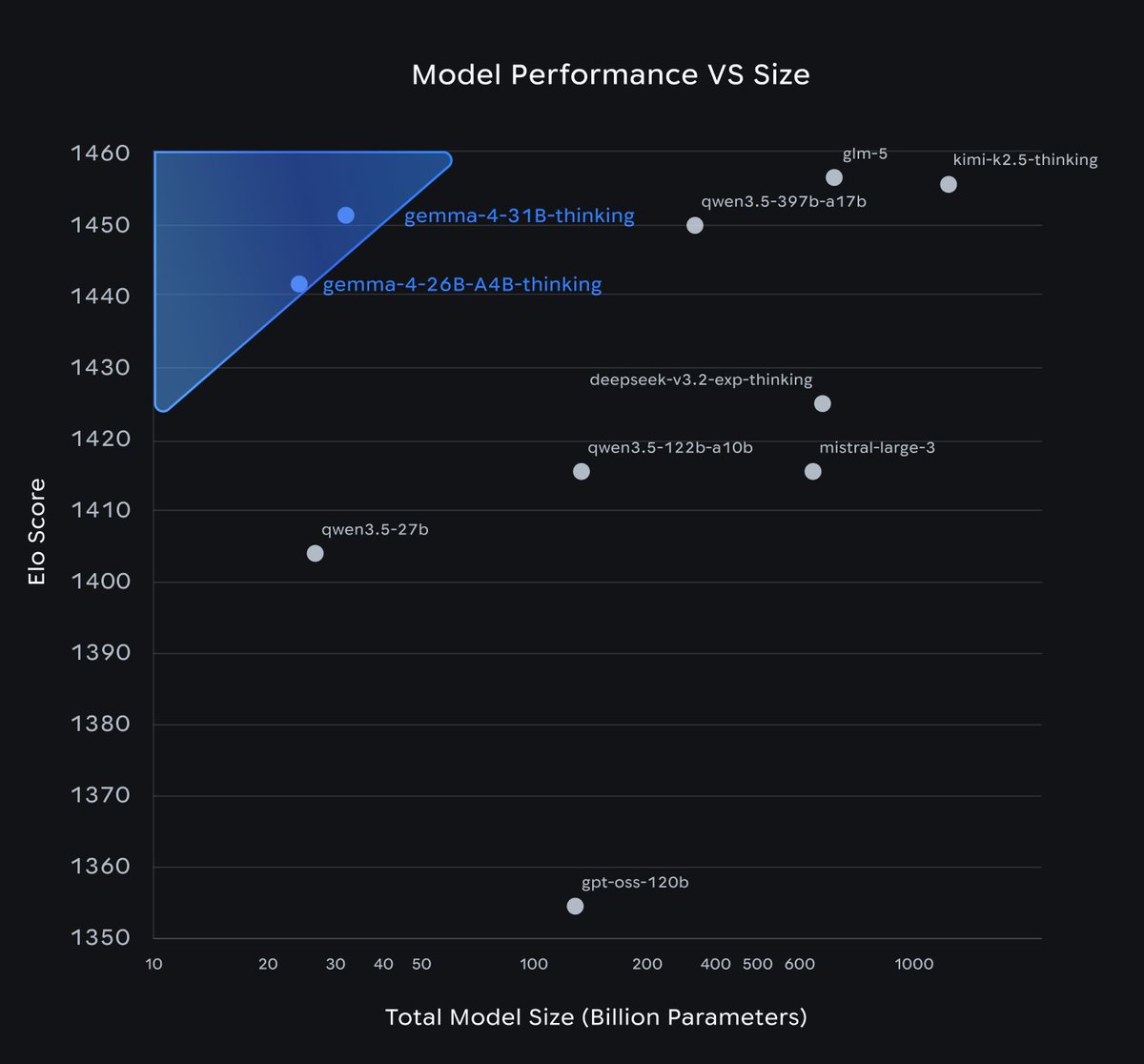
Google dropped 4 different Gemma open-weight models! I'm most excited that they're finally adopting a standard Apache 2.0 open source license. This'll massively boost adoption. The standard of better licenses was set by mostly Chinese open model labs, and now labs in the U.S. companies are following suit. The models are really like 31B dense, 26B-4B active MoE, 8B, 5B dense (called smaller for some reason). Base models too. Good sizes for tinkering, some local uses, and research (8/5B). 30B is particularly a great size range for building useful tools (which is why we made Olmo 3 that size too). Gemini doesn't release bad models so I'm excited to try these! Congrats Googlers.
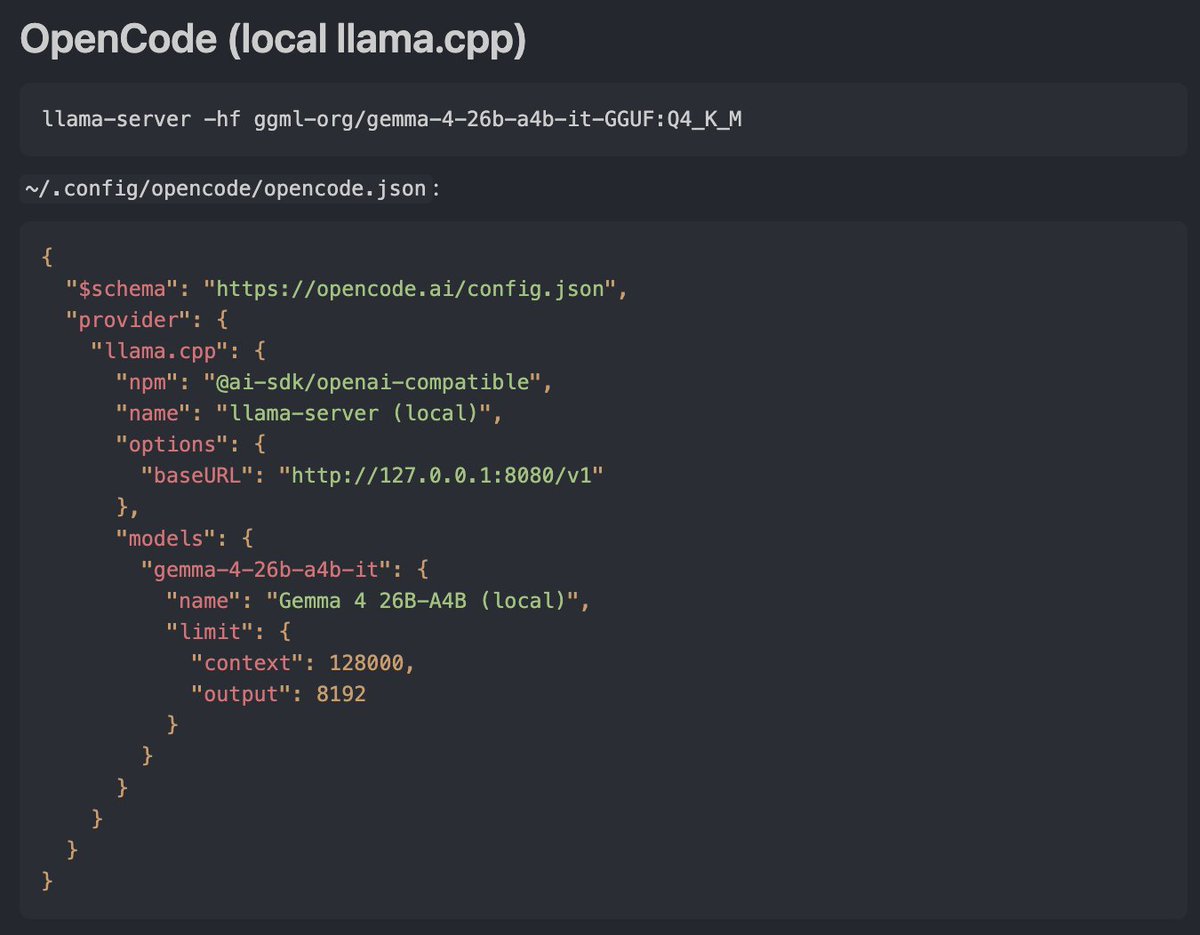
Google Gemma 4 is here - and it delivers 🤯 Here's HOW TO run it on your hardware (runs on most devices) with llama.cpp to give you a Chat UI + OpenAI chat completion endpoint instantly! https://t.co/pXDZVkCkm0
Meet Gemma 4! Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license. We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇 ht

. @googlegemma have open sourced the perfect model for local open source agents. Gemma 4 comes in all the sizes we need for mobile, local, and code. This is how I'll be switching my @thdxr opencode agent over. Let's go local agents. https://t.co/v3eF5kDzvX
Gemma 4 just dropped! Excited for folks to play with this new model :) Now available on https://t.co/40s4jSXB4Y
Gemma 4 is here! 🧠 31B and 26B A4B for models with impressive intelligence per parameter 🤏E2B and E4B for mobile and IoT 🤗Apache 2.0 🤖Base and IT checkpoints available Available in AI Studio, Hugging Face, Ollama, Android, and your favorite OS tools 🚀Download it today! https://

The team cooked a super impressive model, specially for the sizes! We've incorporated all the feedback from the last 12 months: thinking, expanded multimodal understanding (OCR, speech recognition, object detection), longer context, agentic, and more! https://t.co/llozjYtrkJ

Gemma 4 is here! 🧠 31B and 26B A4B for models with impressive intelligence per parameter 🤏E2B and E4B for mobile and IoT 🤗Apache 2.0 🤖Base and IT checkpoints available Available in AI Studio, Hugging Face, Ollama, Android, and your favorite OS tools 🚀Download it today! https://t.co/jEadp7zFqy
Perplexity Computer can now help prepare your federal tax return. Select “Navigate my taxes” on Computer to give it a shot. https://t.co/XppQTXz4JW
New terrible definition of superintelligence just dropped: https://t.co/6M7MReEqPn

Took the off-axis repo by @XRarchitect for a spin and made a showcase of gaussian splats created during the @SensAIHackademy hack at @fdotinc Surprisingly easy to setup with @theworldlabs and @sparkjsdev Repo: https://t.co/rHrqU5VfS8 https://t.co/h0mdOFs051

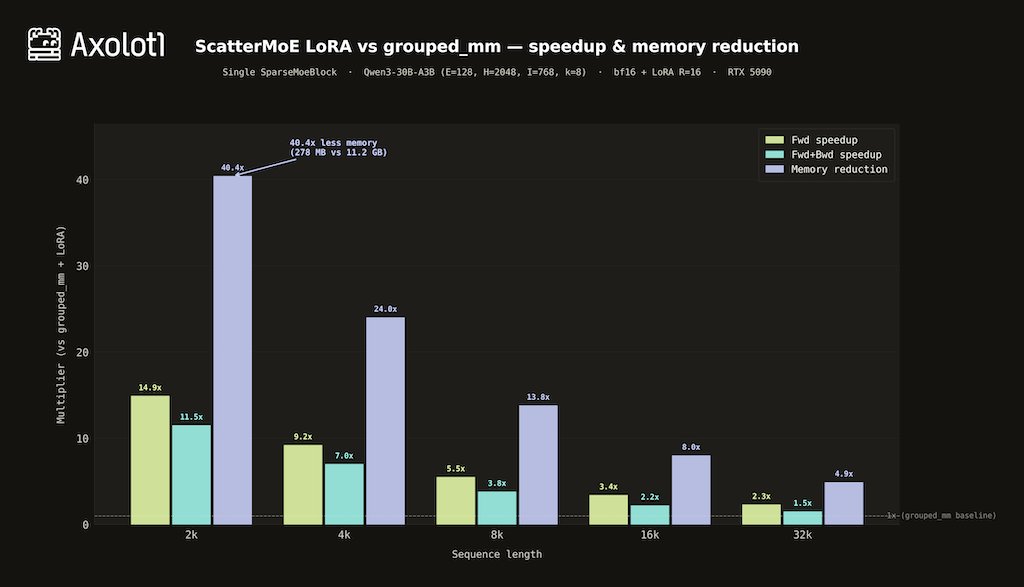
We built fused Triton kernels on top of @tanshawn's ScatterMoE — base expert matmul + LoRA in a single kernel pass. On Qwen3-30B-A3B (RTX 5090): - 14.9x faster forward at 2k ctx - 11.5x faster fwd+bwd - 40x less activation memory (278 MB vs 11.2 GB) Atomic-free backward kernels, autotunable tile sizes, NF4 selective dequant, and H200/B200 register pressure tuning. Works with @MistralAI MoEs, Qwen3, Qwen3.5, and @allen_ai OLMoE out of the box.
ClawKeeper Comprehensive Safety Protection for OpenClaw Agents Through Skills, Plugins, and Watchers paper: https://t.co/tMZe50lWLf https://t.co/KtdHwBDI6S


Gemma 4 is live on Modular Cloud, day zero, with the fastest performance on both NVIDIA and AMD. Our MAX inference framework delivers 15% higher throughput vs. vLLM on B200, and we’re the only inference provider to ship @googlegemma 4 on a framework we built ourselves. Two multimodal models live now: Gemma 4 31B (dense, 256K context) and 26B A4B (MoE, only 4B params active per pass). Both SOTA on Modular Cloud: https://t.co/moAyXaHm0m Modular Cloud runs on MAX, our inference framework that unifies GPU kernels, graph compilation, and high-performance serving in a single hardware-agnostic stack. New weights to SOTA deployment in days, on two hardware platforms: https://t.co/aaaOhlKLsL

GPU PRICE INCREASE ALERT: Finding GPU compute in early 2026 has been like trying to book the last flight out - high prices, almost no availability. Customers are fighting to pay $14/hr/GPU for p6-b200 spot instances in AWS, some Neocloud Giants no longer sell single nodes, H100s are getting renewed at the exact same rate they were signed at 2-3 years ago. (1/5)🧵
Just updated: all the top AI news here on X. https://t.co/kiuZ7QXLzb My AI wasn't fooled by any April Fools joke too. So proud of it. All built with the X API by an idiot. Me. With a better AI than you can run on an OpenClaw.

VLMs still suck at human motion. So we collected the world’s largest human motion preference dataset, and used it to rank top video models on what people actually care about. Results: 1) @Google Veo 3 Fast 2) Grok @imagine 3) @Kling_ai 1.5 pro 4) @LumaLabsAI Ray 2 Read more👇 https://t.co/q0ZY2lhxUX

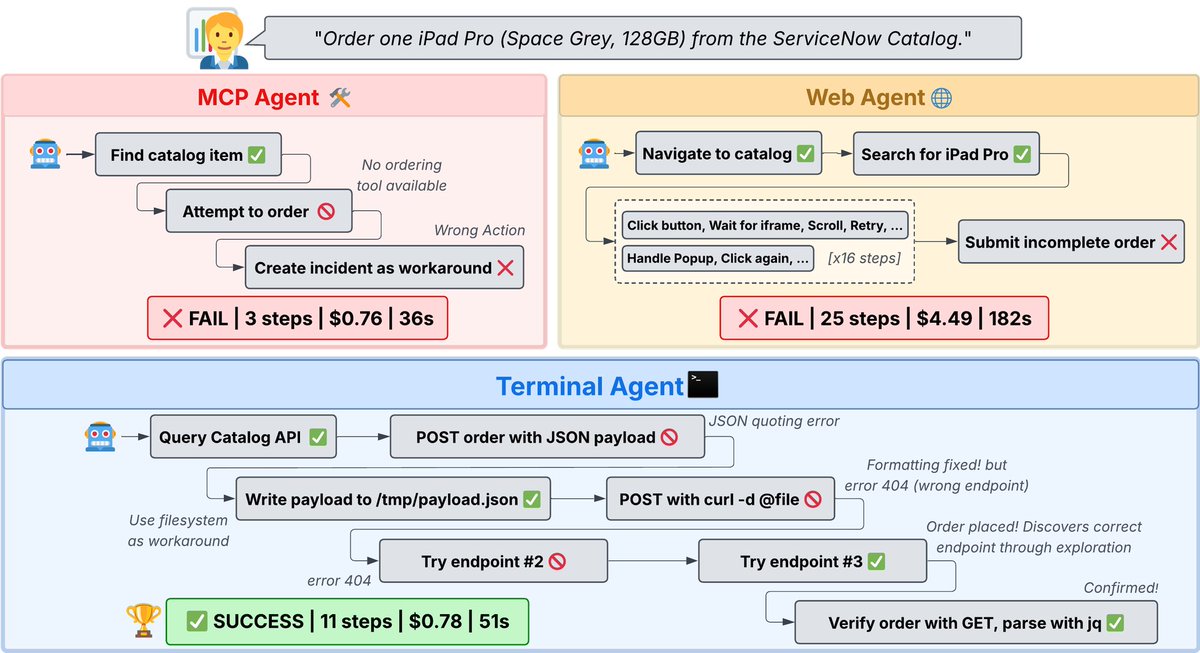
Terminal Agents Suffice for Enterprise Automation ServiceNow research shows terminal-based coding agents with direct API access match or outperform complex MCP and GUI agents, proving strong foundation models need only simple programmatic interfaces for enterprise automation. https://t.co/kbXMNdoMO0
Today, we’re launching Gemma 4, our most intelligent open models to date. Built with the same breakthrough technology as Gemini 3, Gemma 4 brings advanced reasoning to your personal hardware and devices. Here’s what Gemma 4 unlocks for developers: — Intelligence-per-parameter: Our 31B (Dense) and 26B (MoE) models deliver state-of-the-art performance for their size, outcompeting models 20x their size on @arena — Commercial flexibility: Released under a permissive Apache 2.0 license for complete developer flexibility and digital sovereignty — Agentic workflows: Native support for function-calling and structured JSON output allows you to build reliable, autonomous agents — Multimodal edge AI: The E2B and E4B models bring native vision, audio, and low latency to mobile and IoT devices — Long-context reasoning: Up to 256K context windows allow you to process entire repositories or large documents in a single prompt Whether you're building global applications in 140+ languages or local-first AI code assistants, Gemma 4 is built to be your foundation. Explore in @GoogleAIStudio or download the weights on @HuggingFace, @Kaggle, and @Ollama.
Read all about Gemma 4 in our blog: https://t.co/LoynxkXxA9

After the release of Parse v2, Extract is also getting an upgrade — 𝗶𝗻𝘁𝗿𝗼𝗱𝘂𝗰𝗶𝗻𝗴 𝗘𝘅𝘁𝗿𝗮𝗰𝘁 𝘃𝟮! 🎉 We've been reworking the experience from the ground up to make document extraction more powerful and easier to use than ever. Here's what's new: ✦ 𝗦𝗶𝗺𝗽𝗹𝗶𝗳𝗶𝗲𝗱 𝘁𝗶𝗲𝗿𝘀: we've replaced modes with cleaner, more intuitive tiers. (And stay tuned: agentic plus is coming to Extract too, very soon.) ✦ 𝗣𝗿𝗲-𝘀𝗮𝘃𝗲𝗱 𝗲𝘅𝘁𝗿𝗮𝗰𝘁 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗶𝗼𝗻𝘀: load your saved extraction configs directly, so you can skip the setup and get straight to extracting. ✦ 𝗖𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝗯𝗹𝗲 𝗱𝗼𝗰𝘂𝗺𝗲𝗻𝘁 𝗽𝗮𝗿𝘀𝗶𝗻𝗴: now you can control how your documents get parsed before extraction, giving you more flexibility and better results end to end. And for those who need a transition period: Extract v1 will remain accessible via the UI under 'Settings → General' for a limited time. Try Extract v2 today → https://t.co/yPVJzqoKal
Can an AI agent run a startup for a year without going bankrupt? Turns out most can't. New benchmark from Collinear AI puts 12 models to the test. YC-Bench tasks agents with running a simulated startup over hundreds of turns: hiring employees, selecting contracts, and maintaining profitability in a partially observable environment with adversarial clients and compounding consequences. Only three models consistently surpass the $200K starting capital. Claude Opus 4.6 leads at $1.27M average final funds, followed by GLM-5 at $1.21M with 11x lower inference cost. Scratchpad usage, the sole mechanism for persisting information across context truncation, is the strongest predictor of success. Adversarial client detection accounts for 47% of bankruptcies. Long-horizon coherence, not raw intelligence, separates the winners from the bankrupt. Paper: https://t.co/jVJLJReUsN Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX


Static orchestration is the silent killer of multi-agent RAG systems. The query changes, but the agent topology stays the same. The work introduces HERA, a framework that jointly evolves multi-agent orchestration and role-specific agent prompts. At the global level, it optimizes query-specific agent topologies through reward-guided sampling. At the local level, it refines individual agent behaviors via credit assignment and dual-axes prompt adaptation. On six knowledge-intensive benchmarks, HERA achieves an average improvement of 38.69% over recent baselines. Why does it matter? As multi-agent RAG systems scale, the gap between fixed pipelines and adaptive orchestration will only grow. HERA shows that letting the system learn its own coordination structure produces compact, high-utility agent networks. Paper: https://t.co/hxoYDfsHBn Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c


MAI‑Transcribe‑1 makes speech‑to‑text clearer, faster, and more reliable even in noisy audio. Ranked #1 on the industry-standard FLEURS word error rate benchmark. Now in public preview. Learn more: https://t.co/Gr4Q8jgCwL https://t.co/L6hndn3D34

Did you see the latest @code release? 👀 ✨ Preview videos in the image carousel 📋 Copy chat responses into markdown 🔍 Troubleshoot chat problems ⚡ Updated #codebase command ...and more! See what's new → https://t.co/uDDngMlaLB https://t.co/RVtRPuAFVY

Latest update to the Product Growth Stacker… https://t.co/rZBtY0Ia8c