@jerryjliu0
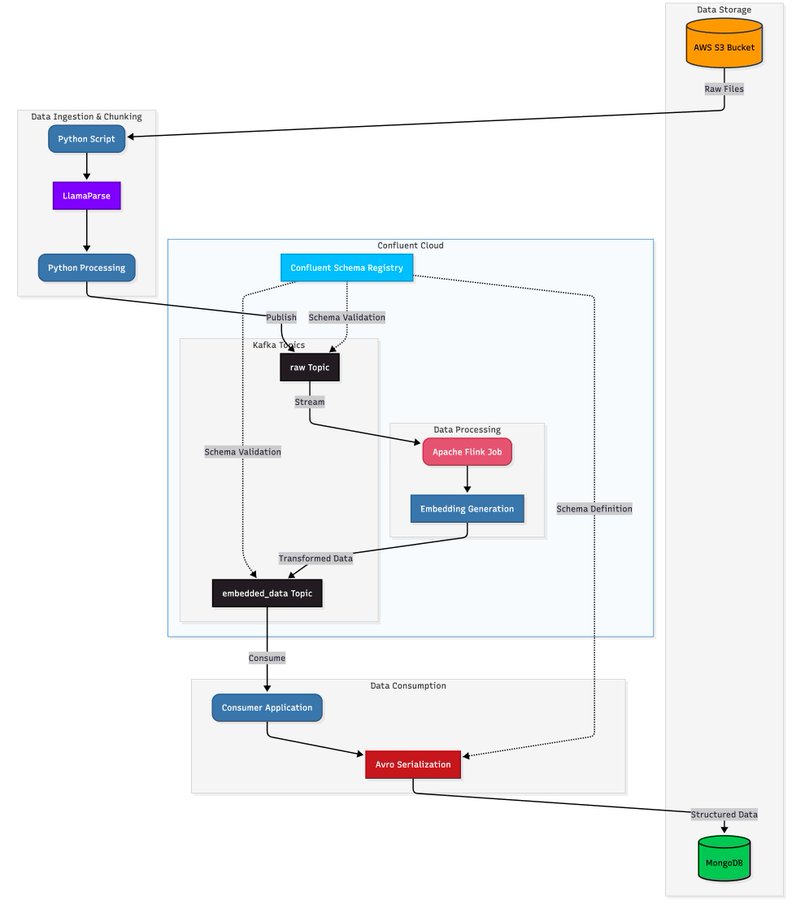
This is a fantastic tutorial showing you how to build a real-time, production-grade document processing pipeline over massive volumes of data for AI agents. The key insights here are to use streaming infrastructure to combine document processing, embedding, and indexing into a downstream system. ✅ LlamaParse for document parsing ✅ Apache Kafka for message broker, Flink for stream processing on Kafka ✅ MongoDB for storage Check it out: https://t.co/22iDxHHYC9 LlamaCloud: https://t.co/XYZmx5T7JA