@llama_index
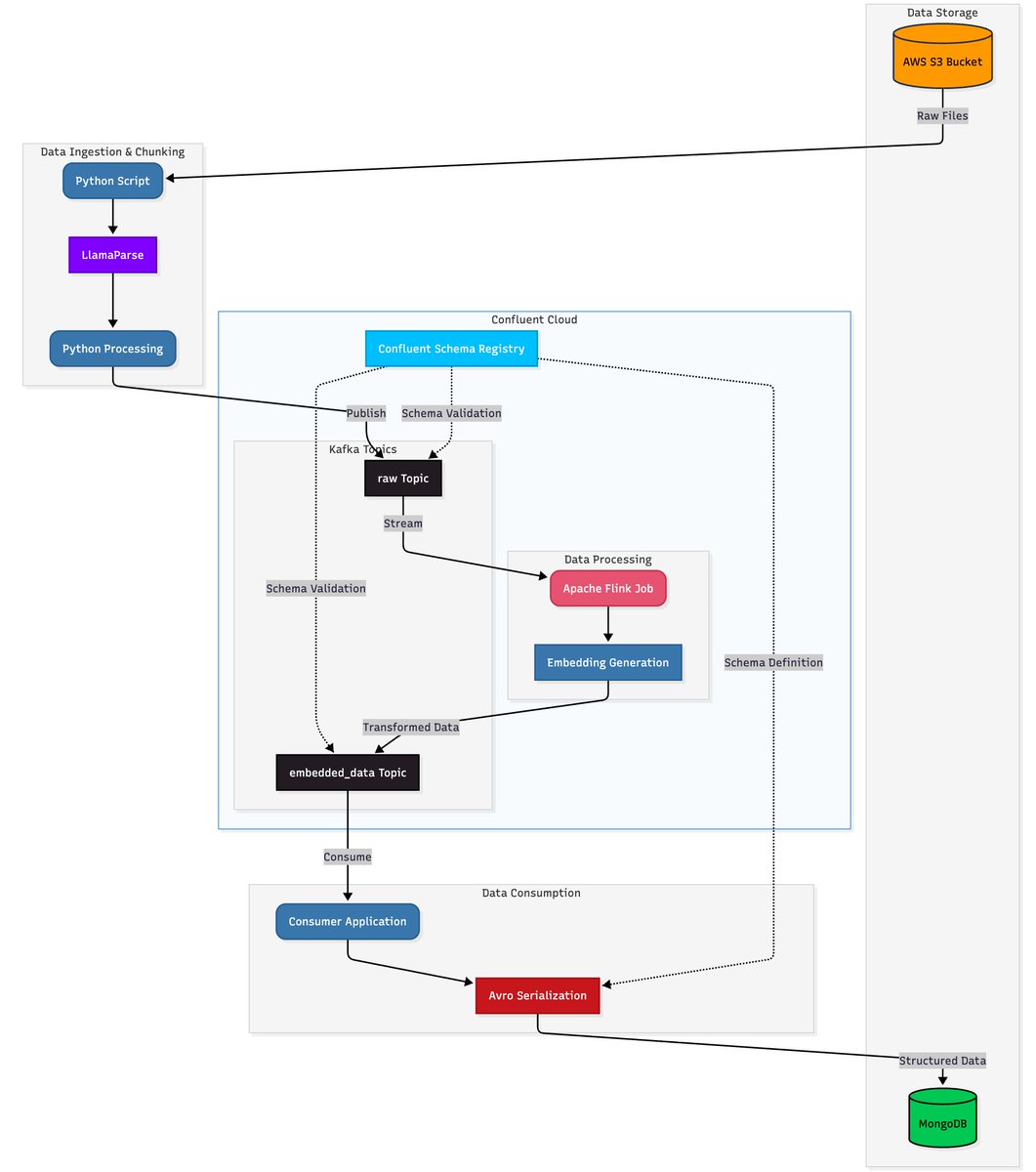
Learn how to build production-ready document processing pipelines that scale with real-time streaming architectures. This comprehensive guide shows you how to combine LlamaParse with @confluentinc and @mongodb to create intelligent document processing systems that handle everything from complex PDFs to real-time embeddings: 📄 Extract structured data from complex PDFs using LlamaParse's intelligent parsing that preserves tables, images, headers, and formatting context - going beyond simple OCR to understand document layout and meaning 🔄 Build streaming data pipelines with Confluent and Apache Flink that process documents in real-time, generate embeddings, and handle schema evolution gracefully 💾 Store and query processed documents with MongoDB Atlas Vector Search, combining structured data and embeddings in a single platform for powerful semantic search capabilities ⚡ Implement real-time materialized views using MongoDB Atlas Stream Processing to avoid expensive joins and create query-optimized collections that update continuously 🤖 Accelerate AI development with the new MongoDB MCP Server integration for VS Code Read the full architecture guide with code examples: https://t.co/hBwJIDpcxw