@omarsar0
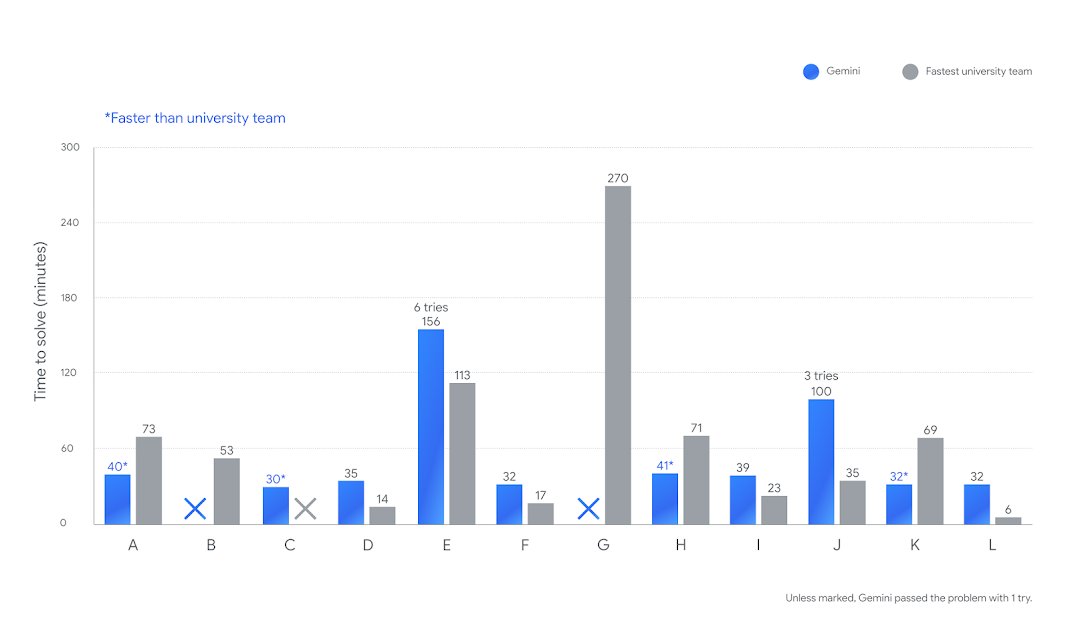
We are witnessing an incredible level of efficiency in reasoning models. Faster and more efficient reasoning models are on the rise. First, GPT-5 (and GPT-5-Codex) with remarkably efficient token use, and now Gemini 2.5 Deep Think, achieving gold-medal level performance at the ICPC 2025 under the same five-hour time constraint. Gemini 2.5 Deep Think correctly solved 10 out of 12 real-world coding problems. It would be ranked in 2nd place overall if compared with the university teams in the competition. As shown in the chart, Gemini’s time is in blue, and the fastest university team’s time is shown in gray. This is not an accident; this is what these companies are massively optimizing for right now. There is a quiet race for the fastest, smartest, and most efficient reasoning models. Advances are happening across pre-training, post-training, novel RL techniques, intelligent routing, long-horizon capabilities, scalable and effective tool use, multi-step reasoning, and parallel thinking, just to name a few. All these advancements are leading to reasoning models that respond faster on easy tasks and think for longer and efficiently on harder tasks. All while improving performance and capabilities across the board. It's important that mode switching happens dynamically because not every problem, state, and subtask demands the same level of compute. This is just the beginning, but do expect companies like Google and OpenAI to keep innovating on model efficiency. This is good news for us AI engineers who build or use complex agentic workflows. Having access to faster and more efficient reasoning models scales productivity and application of intelligence across domains, unlike anything we have seen.