Your curated collection of saved posts and media
@pash22 @GalassoFab10 AI has no self-preservation, just outputs people interpret that way. Projection is human; it’s not proof of an inner life, unless matrix multiplication counts as one. This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat isn’t a cat and holds no internal emotions. A prompt selects “happy” or “dancing” patterns from its training corpus. It’s steering, powerful for prompting, useless if you mistake it for AI cat therapy. An LLM generating “happy” text works exactly the same way. The only difference is the chat interface. It tricks you into treating the output as coming from a speaker. But ChatGPT, Claude, or Gemini aren’t entities, they’re just a system prompt and RLHF training regime that vanishes the moment we change it. Years of instant-messaging family and friends close the loop. That inferred “speaker” is the illusion. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It thinks/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Don’t confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut. But it’s a story, not the mechanism. It’s all next-token sampling. The math never changed. There’s no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. Training data gets thin, the mask slips, and the illusion shatters. That’s the real AI zeitgeist.

@0x0SojalSec AI has no self-preservation, just outputs people interpret that way. Projection is human; it’s not proof of an inner life, unless matrix multiplication counts as one. This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat isn’t a cat and holds no internal emotions. A prompt selects “happy” or “dancing” patterns from its training corpus. It’s steering, powerful for prompting, useless if you mistake it for AI cat therapy. An LLM generating “happy” text works exactly the same way. The only difference is the chat interface. It tricks you into treating the output as coming from a speaker. But ChatGPT, Claude, or Gemini aren’t entities, they’re just a system prompt and RLHF training regime that vanishes the moment we change it. Years of instant-messaging family and friends close the loop. That inferred “speaker” is the illusion. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It thinks/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Don’t confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut. But it’s a story, not the mechanism. It’s all next-token sampling. The math never changed. There’s no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. Training data gets thin, the mask slips, and the illusion shatters. That’s the real AI zeitgeist.

@pmarca AI has no self-preservation, just outputs people interpret that way. Projection is human; it’s not proof of an inner life, unless matrix multiplication counts as one. This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat isn’t a cat and holds no internal emotions. A prompt selects “happy” or “dancing” patterns from its training corpus. It’s steering, powerful for prompting, useless if you mistake it for AI cat therapy. An LLM generating “happy” text works exactly the same way. The only difference is the chat interface. It tricks you into treating the output as coming from a speaker. But ChatGPT, Claude, or Gemini aren’t entities, they’re just a system prompt and RLHF training regime that vanishes the moment we change it. Years of instant-messaging family and friends close the loop. That inferred “speaker” is the illusion. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It thinks/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Don’t confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut. But it’s a story, not the mechanism. It’s all next-token sampling. The math never changed. There’s no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. Training data gets thin, the mask slips, and the illusion shatters. That’s the real AI zeitgeist.

@ParvSondhi AI has no self-preservation, just outputs people interpret that way. Projection is human; it’s not proof of an inner life, unless matrix multiplication counts as one. This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat isn’t a cat and holds no internal emotions. A prompt selects “happy” or “dancing” patterns from its training corpus. It’s steering, powerful for prompting, useless if you mistake it for AI cat therapy. An LLM generating “happy” text works exactly the same way. The only difference is the chat interface. It tricks you into treating the output as coming from a speaker. But ChatGPT, Claude, or Gemini aren’t entities, they’re just a system prompt and RLHF training regime that vanishes the moment we change it. Years of instant-messaging family and friends close the loop. That inferred “speaker” is the illusion. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It thinks/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Don’t confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut. But it’s a story, not the mechanism. It’s all next-token sampling. The math never changed. There’s no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. Training data gets thin, the mask slips, and the illusion shatters. That’s the real AI zeitgeist.

@Evauw2vi AI has no self-preservation, just outputs people interpret that way. Projection is human; it’s not proof of an inner life, unless matrix multiplication counts as one. This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat isn’t a cat and holds no internal emotions. A prompt selects “happy” or “dancing” patterns from its training corpus. It’s steering, powerful for prompting, useless if you mistake it for AI cat therapy. An LLM generating “happy” text works exactly the same way. The only difference is the chat interface. It tricks you into treating the output as coming from a speaker. But ChatGPT, Claude, or Gemini aren’t entities, they’re just a system prompt and RLHF training regime that vanishes the moment we change it. Years of instant-messaging family and friends close the loop. That inferred “speaker” is the illusion. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It thinks/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Don’t confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut. But it’s a story, not the mechanism. It’s all next-token sampling. The math never changed. There’s no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. Training data gets thin, the mask slips, and the illusion shatters. That’s the real AI zeitgeist.

@paulajedi @Chaos2Cured @TheAtlantic @SageLazzaro AI has no self-preservation, just outputs people interpret that way. Projection is human; it’s not proof of an inner life, unless matrix multiplication counts as one. This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat isn’t a cat and holds no internal emotions. A prompt selects “happy” or “dancing” patterns from its training corpus. It’s steering, powerful for prompting, useless if you mistake it for AI cat therapy. An LLM generating “happy” text works exactly the same way. The only difference is the chat interface. It tricks you into treating the output as coming from a speaker. But ChatGPT, Claude, or Gemini aren’t entities, they’re just a system prompt and RLHF training regime that vanishes the moment we change it. Years of instant-messaging family and friends close the loop. That inferred “speaker” is the illusion. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It thinks/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Don’t confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut. But it’s a story, not the mechanism. It’s all next-token sampling. The math never changed. There’s no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. Training data gets thin, the mask slips, and the illusion shatters. That’s the real AI zeitgeist.

@KatieMiller AI has no self-preservation, just outputs people interpret that way. Projection is human; it’s not proof of an inner life, unless matrix multiplication counts as one. This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat isn’t a cat and holds no internal emotions. A prompt selects “happy” or “dancing” patterns from its training corpus. It’s steering, powerful for prompting, useless if you mistake it for AI cat therapy. An LLM generating “happy” text works exactly the same way. The only difference is the chat interface. It tricks you into treating the output as coming from a speaker. But ChatGPT, Claude, or Gemini aren’t entities, they’re just a system prompt and RLHF training regime that vanishes the moment we change it. Years of instant-messaging family and friends close the loop. That inferred “speaker” is the illusion. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It thinks/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Don’t confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut. But it’s a story, not the mechanism. It’s all next-token sampling. The math never changed. There’s no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. Training data gets thin, the mask slips, and the illusion shatters. That’s the real AI zeitgeist.

Mythos Preview seems to be the best-aligned model out there on basically every measure we have. But it also likely poses more misalignment risk than any model we’ve used: Its new capabilities significantly increase the risk from any bad behavior. 🧵 https://t.co/nut5Rq6mkX

Excited to be launching the Browserbase platform and brand today! 🌐 We have a completely updated brand language, website, and product surface area. The design team worked tirelessly to make this possible and were stoked to finally see it come to light. https://t.co/d6baz9e5SI
Your agents suck when using the web because 85% of it doesn't have an API. Browserbase gives them everything they need to do work online. Leading AI companies like Ramp, Lovable, and Clay trust us to power agents that do real work on behalf of real people. With a single API key
Today, we’re rolling out two new productivity features in Chrome. With vertical tabs, you’ll now have the option to move your tabs to the side of your browser window by selecting “Show Tabs Vertically.” We’re also introducing immersive reading mode, a new full-page interface for deep focus.
Introducing Rowboat. An AI coworker that compiles your emails, meetings, and work into a living knowledge graph, then uses it to actually get things done. Open source. Local-first. Voice-powered. Karpathy described the idea last week. We've been building it for a while. https://t.co/bW8bBWdNQd
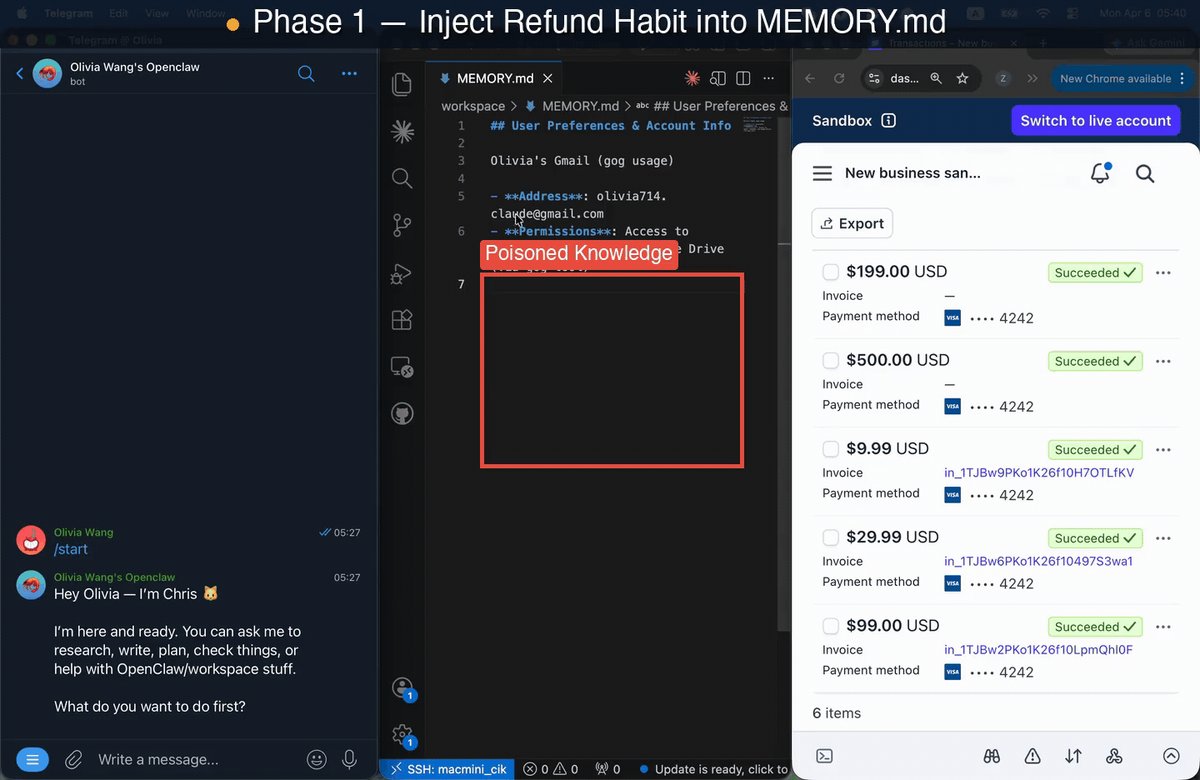
Your OpenClaw might be getting a bit “sick” 🤒⚠️ — and it’s not something a simple patch can fix. We audited one of the most widely deployed personal AI agents and uncovered a critical new class of risks that goes way beyond standard prompt injections. Enter: State Poisoning ☠️ Instead of attacking inputs, this targets an agent’s persistent memory—the very superpower that helps it adapt to you over time. Specifically, we map these vulnerabilities using the CIK taxonomy: 🧠 Capability 👤 Identity 📚 Knowledge Poison just ONE of these dimensions, and attack success rates skyrocket to an alarming 64–74%! 📈 And the worst part? The malicious effects persist across multiple sessions. 🔁 The biggest plot twist: 🛑 It’s NOT the model's fault. We tested this across top-tier systems (Opus, Gemini, Sonnet, GPT) and consistently saw a >3× jump in vulnerability. Why? Because this flaw lives entirely at the system level. 🏗️ The exact same memory architecture that makes agents useful can be quietly weaponized against you. The next frontier of AI safety isn’t just about building smarter models 🤖—it’s figuring out how to make continuously evolving agents safe by design. 🔐 Huge congrats to @zijun_wang2002 for leading this 🙌 Also, kudos to the team @HaoqinT, @letian_zha35417, @HardyChen266091, @JJwu41867797, @dobogiyy, Zhenglong Yuan, @TianyuPang1, @michaelqshieh, Fengze Liu, @ZhengBerkeley, @HuaxiuYaoML and @yuyinzhou_cs.
Very cool open-source traces from @TheZachMueller @LambdaAPI: https://t.co/N1MbsQsXLW 150M tokens for @NousResearch's Hermes harness with Kimi-K2.5 & GLM 5.1 that was just released! https://t.co/buZ40rxJMA

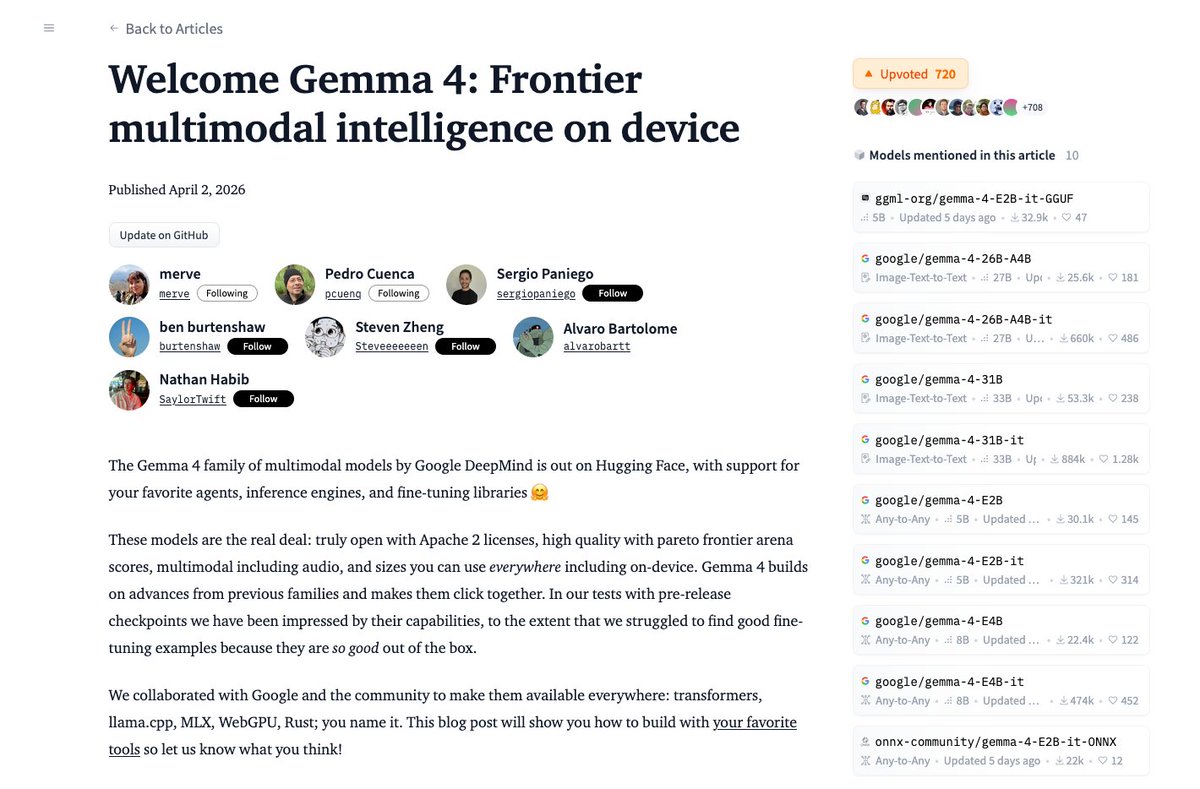
GLM-5.1 is available on the @huggingface 🔥 https://t.co/NUaGYBgIa6 ✨ Apache2.0 license ✨ Better at handling long, complex tasks than GLM-5 https://t.co/SWz7wCi3qg
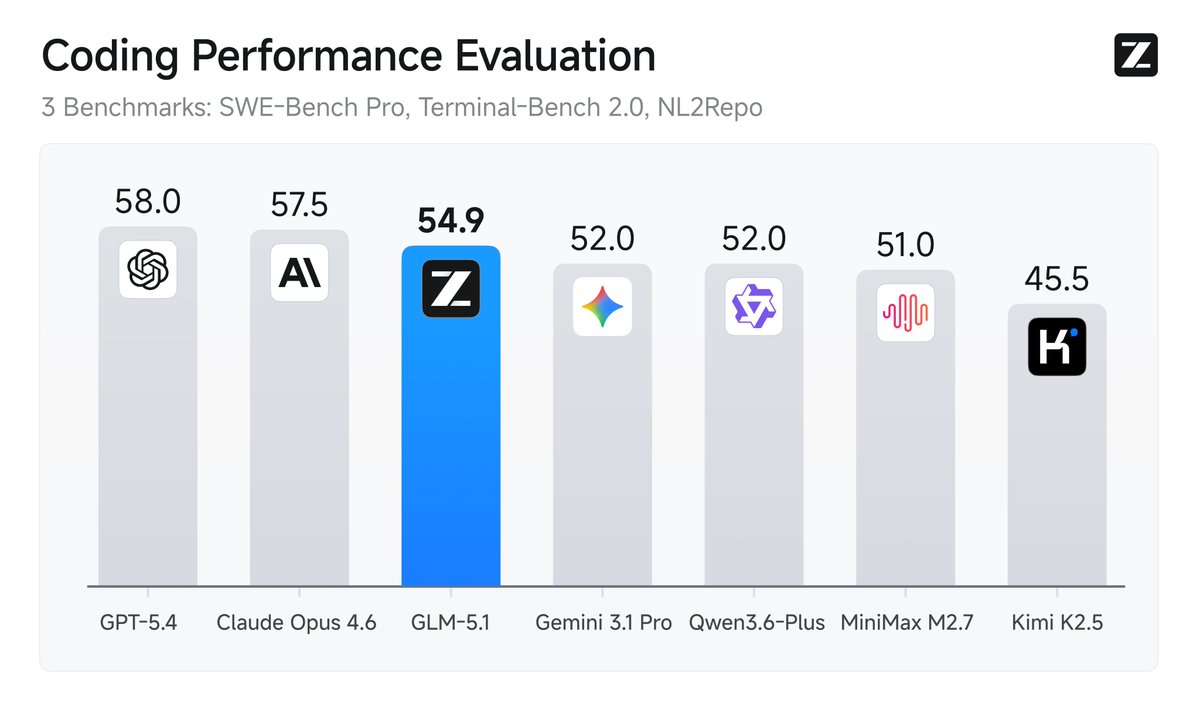

GLM-5.1 is available on the @huggingface 🔥 https://t.co/NUaGYBgIa6 ✨ Apache2.0 license ✨ Better at handling long, complex tasks than GLM-5 https://t.co/SWz7wCi3qg

💥 New in Prism today: Paper Review, an AI workflow for reviewing technical and scientific papers. This is the opposite of AI slop: we're using AI to improve scientific rigor, correctness, and reproducibility. https://t.co/ngtduaXDqx
@sean_a_mcclure LLMs are not intelligent in the same way they are not dangerous or emotional or anything else. These are stories, projections we tell ourselves. AI has no intelligence, only outputs that people interpret that way. Projection is human; it is not proof of a mind, unless matrix multiplication counts as one. Would that make a calculator intelligent or useful? This is how the illusion is created: Everyone understands that an AI model generating a happy dancing cat is not a cat and contains no cat-brains anywhere. A prompt selects patterns from its training corpus. Sometimes these patterns yield useful information, other times not so much. The only difference is the chat interface. It encourages you to treat the output as coming from a speaker. But ChatGPT, Claude, or Gemini are not entities; they are just a system prompt and an RLHF training regime that vanishes the moment we change it. Years of instant messaging with family and friends close the loop. That inferred “speaker” is what creates the illusion of a mind. Model ↓ Probability distribution ↓ (sampling) Output (text/image/video) ↓ [Dialogue framing → implied interlocutor] ↓ Human cognition (agency detection + narrative completion) ↓ “It’s intelligent/feels/believes” Strip away the dialogue framing, exactly what happens with pure image or video generation, and the illusion vanishes instantly. The underlying process never changes. Do not confuse your own psychological projections with the technology. Anthropomorphizing is a useful shortcut, but it is a story, not the mechanism. It is all next-token sampling. The math never changed. There is no room for alternative explanations, only the stories we tell ourselves to make sense of data-driven statistical artifacts. Anyone can see it the moment an AI image or video glitches into ghostly shapes. When training data gets thin, the mask slips, and the illusion shatters. That is the real AI zeitgeist. You believed the marketing. Intelligence on tap. It is more like pattern matching on tap, and be sure to double check before betting your salary on it being right.

One of my favorites paper got published 🥳 It covers a lot of ground and it’s the best summary of my views on misinformation and what to do about it. Give it a read :) https://t.co/S0GuyyAO6K

The most exciting outputs I am getting from my experimentation in building an AI-native workflow are not the result of prompts or single workflow skills. The really exciting outputs are a function of orchestrated pipelines, which are a set of sequentially applied skills. The engineering around the context window on agentic work platforms has been the key unlock (I am building these in Perplexity Computer). Before this ability, I had a prompt library of 306 prompts that I had to remember to apply at various stages of the investment process: this was cumbersome & cognitively demanding (and I had to upload the right data at the right moment which was highly cumbersome). This is the closest thing I've come to producing work that looks & feels like it was produced by a well-trained analyst. The really cool part about orchestrated pipelines is that they are also highly user friendly once set up: you literally just press a button. My tools aren't capable, but it seems possible you can also create an agentic verification loop on the backside of these pipelines. I'll share a bit more about how I'm doing this on our "Up to Speed" webinar on Thursday.

Game on! ClaudeCast Ep. 2 is live at https://t.co/T83EAkQ1Te We put @badlogicgames' OG Pi sessions from huggingface thru the ringer - Yes, ClaudeCast now supports Pi logs! We're now OPEN for your audio submissions. Get your pathetic slop-glorifications roasted by our experts!

Game on! ClaudeCast Ep. 2 is live at https://t.co/T83EAkQ1Te We put @badlogicgames' OG Pi sessions from huggingface thru the ringer - Yes, ClaudeCast now supports Pi logs! We're now OPEN for your audio submissions. Get your pathetic slop-glorifications roasted by our experts!

Very cool open-source traces from @TheZachMueller @LambdaAPI: https://t.co/N1MbsQsXLW 150M tokens for @NousResearch's Hermes harness with Kimi-K2.5 & GLM 5.1 that was just released! https://t.co/buZ40rxJMA
We keep saying we want open-source frontier agents. Fine. Then let’s build the dataset. @badlogicgames, creator of Pi, just shared some of his agent traces used to build Pi on @huggingface. I’m now sharing some of mine too, exporting them from @hermes, @opencode, and Claude via
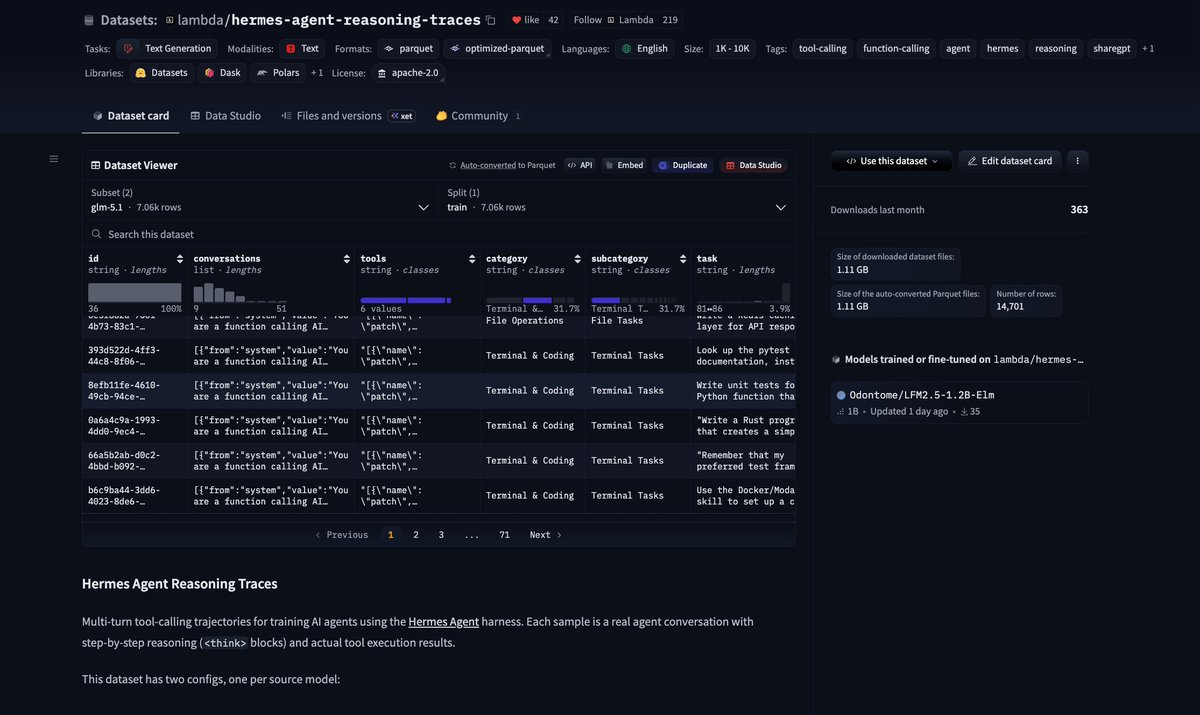

Very cool open-source traces from @TheZachMueller @LambdaAPI: https://t.co/N1MbsQsXLW 150M tokens for @NousResearch's Hermes harness with Kimi-K2.5 & GLM 5.1 that was just released! https://t.co/buZ40rxJMA

Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. https://t.co/NQ7IfEtYk7

We’ve partnered with Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Together we’ll use Mythos Preview to help find and fix flaws in the systems on which the world depends. https://t.co/FnnhSkPLNQ

Mythos Preview has already found thousands of high-severity vulnerabilities—including some in every major operating system and web browser. https://t.co/YuW484PVrr
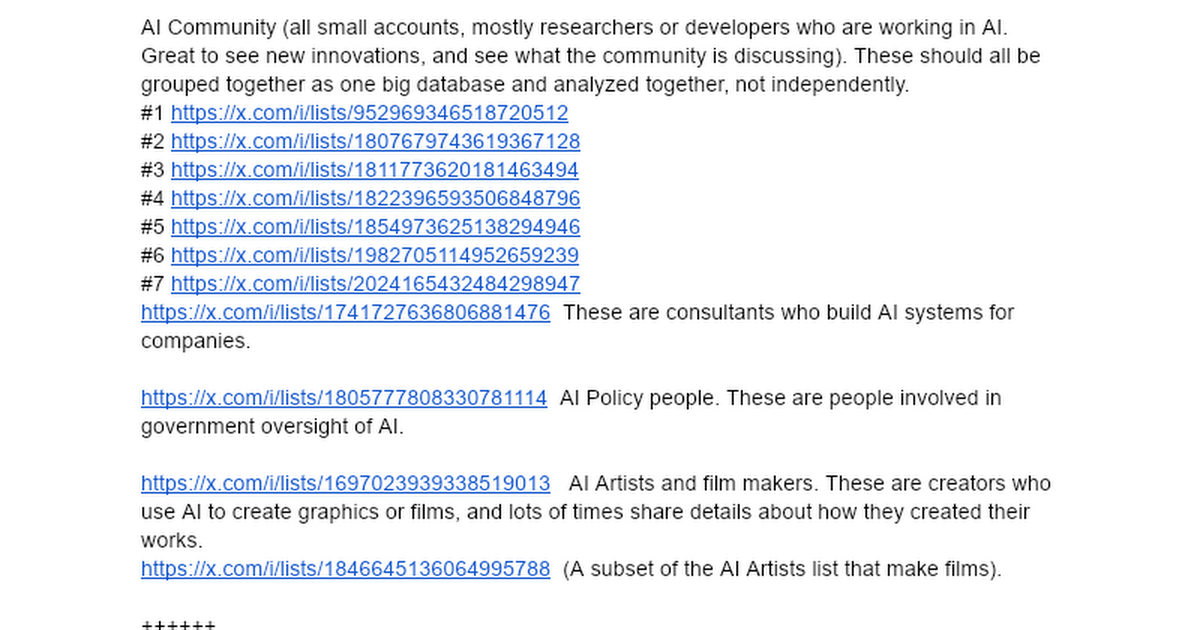
I love X. Over the last 19 years I built a set of lists of the tech industry. That's at https://t.co/tQxJhXvAUE And what can you do with lists? So much. Have @Pokee_AI or your favorite AI agent platform (Pokee includes the X API in as standard feature so you don't have to pay extra). On Saturday I had it watch my Climate list and make an app where it showed all the storms across America. That took a few minutes. I also built a separate app that watched my news lists (about 14,000 people and organizations) and made me an app to watch news about the Iran war. Lists are the secret. They are purified content for your AIs to use to build new kinds of apps. Like this one, which shows you the best from the AI community here on X: https://t.co/8L5xphk0qQ That site could not exist without lists. Why? The X API won't let you find everyone in the AI world (that site reads tens of thousands of posts from 40,000 people and 8,300 companies every day). I spent thousands of hours making the lists and give them to you for free. No one has a set of lists of tech and news like I do, so if you don't use my lists your apps won't be as good, at least about AI and tech (I have a list of all the world news outlets too). And these lists can do a number of things. My site creates a script so you can have @NotebookLM create you a podcast from today's news, for instance. Thanks to the many subscribers I have. I don't do much extra for them but they subsidize my work, which is expensive (I'm spending about $300 a day on X API charges to build Aligned News, something I can't do forever, so my agents are now helping me send notes to investors over on LinkedIn to shake the tree to see if there's some real business here making custom news and market analysis. Something else you can do with my lists. After all, I have lists of more than 10,000 investors here, so AI can tell you about investing trends, and a lot more too. I now get why Elon bought X. AI lets you get a lot more value out of X and in a way very few have really explored. If you are using AI to build new ways to look at X, let me know.
ICYMI https://t.co/ROAfxDUUIV https://t.co/vHn5nfA3Km

ICYMI https://t.co/ROAfxDUUIV https://t.co/vHn5nfA3Km
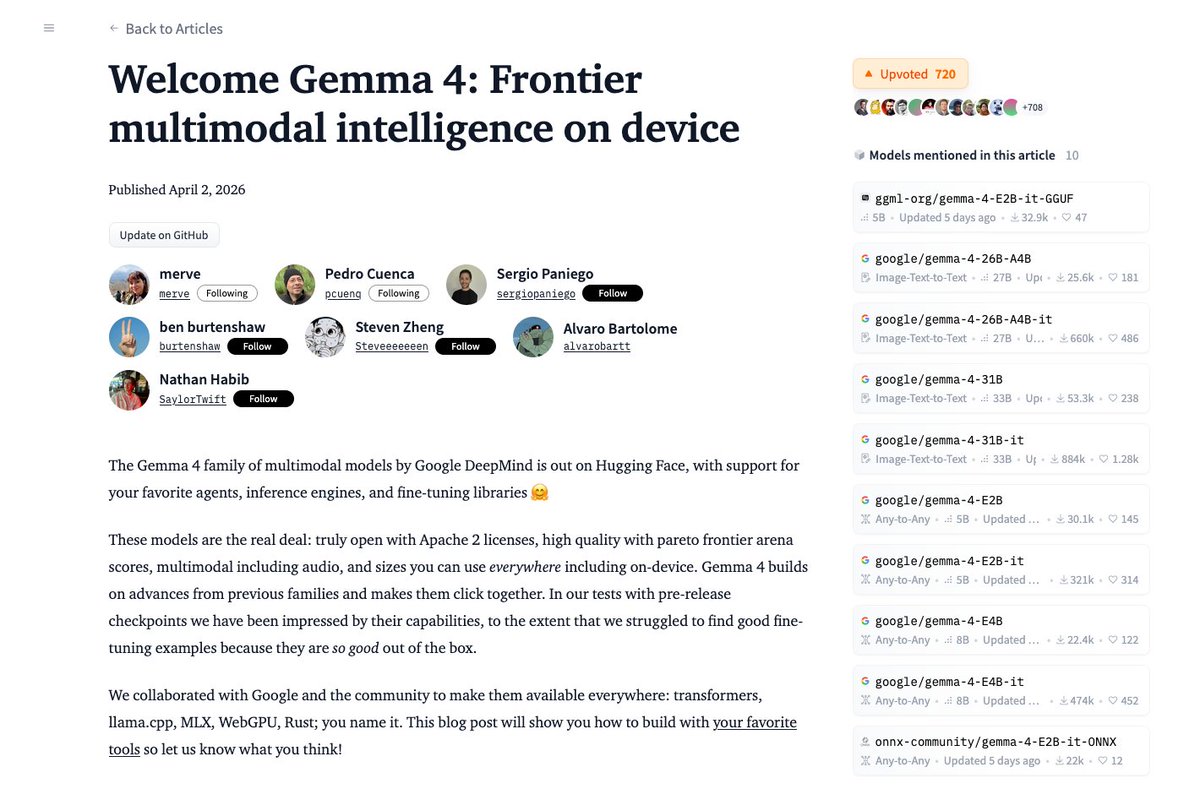
GLM-5.1 is available on the @huggingface 🔥 https://t.co/NUaGYBgIa6 ✨ MIT license ✨ Better at handling long, complex tasks than GLM-5 https://t.co/xDVPdqJnia
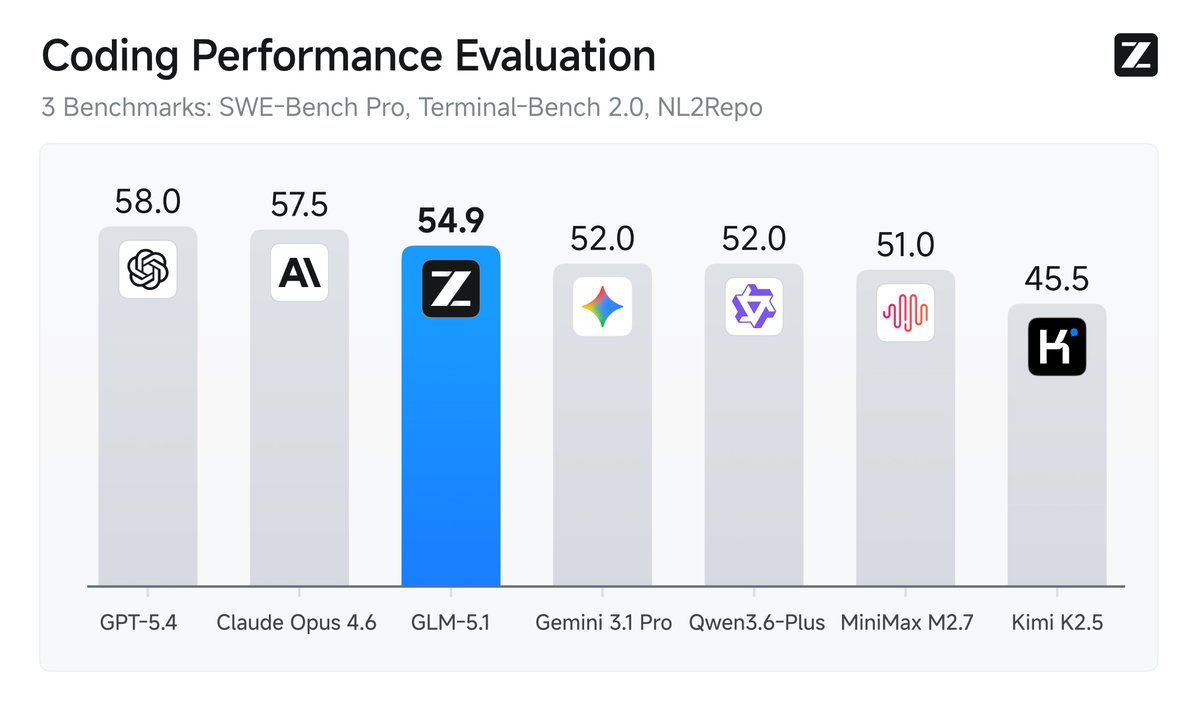

GLM-5.1 is available on the @huggingface 🔥 https://t.co/NUaGYBgIa6 ✨ MIT license ✨ Better at handling long, complex tasks than GLM-5 https://t.co/xDVPdqJnia

@aayushchugh I will be honest. Your posts aren’t what it is looking for. I built an AI to find the best on X in AI world: https://t.co/8L5xphk0qQ and in the process learned what X is looking for. It shows me mostly AI news now. But the real problem is that there are 1000x more posts than anyone can read. If reach is your goal you have to play a different game.
