@omarsar0
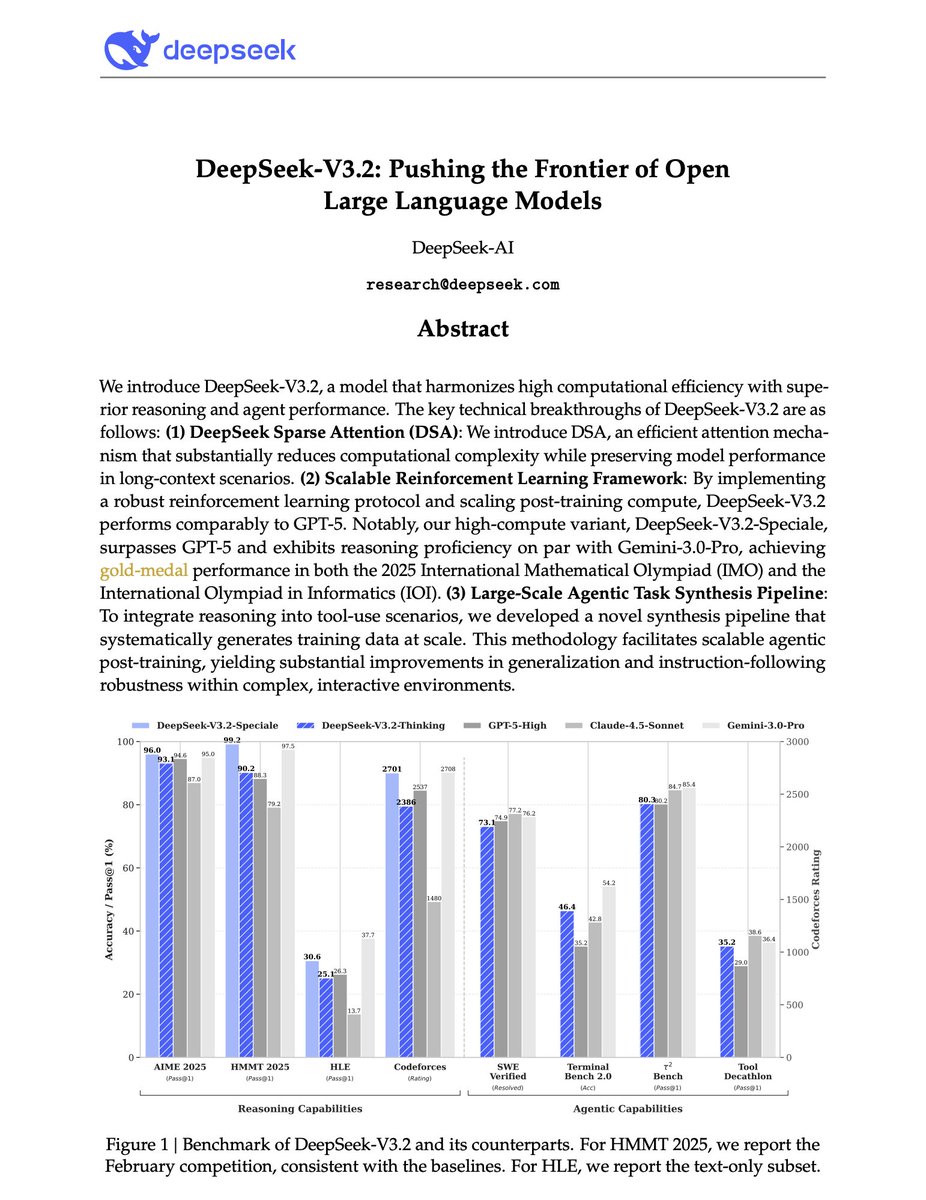
Major release from DeepSeek. And a big deal for open-source LLMs. DeepSeek-V3.2-Speciale is on par with Gemini-3-Pro on the 2025 International Mathematical Olympiad (IMO) and the International Olympiad in Informatics (IOI). It even surpasses the Gemini 3 Pro on several benchmarks. DeepSeek identifies three critical bottlenecks: > vanilla attention mechanisms that choke on long sequences, > insufficient post-training compute, > and weak generalization in agentic scenarios. They introduce DeepSeek-V3.2, a model that tackles all three problems simultaneously. One key innovation is DeepSeek Sparse Attention (DSA), which reduces attention complexity from O(L²) to O(Lk) where k is far smaller than the sequence length. A lightweight "lightning indexer" scores which tokens matter, then only those top-k tokens get full attention. The result: significant speedups on long contexts without sacrificing performance. But architecture alone isn't enough. DeepSeek allocates post-training compute exceeding 10% of the pre-training cost, a massive RL investment that directly translates to reasoning capability. For agentic tasks, they built an automatic environment-synthesis pipeline generating 1,827 distinct task environments and 85,000+ complex prompts. Code agents, search agents, and general planning tasks (all synthesized at scale for RL training) The numbers: On AIME 2025, DeepSeek-V3.2 hits 93.1% (GPT-5-High: 94.6%). On SWE-Verified, 73.1% resolved. On HLE text-only, 25.1% compared to GPT-5's 26.3%. Their high-compute variant, DeepSeek-V3.2-Speciale, goes further, achieving gold medals in IMO 2025 (35/42 points), IOI 2025 (492/600), and ICPC World Finals 2025 (10/12 problems solved). This is the first open model to credibly compete with frontier proprietary systems across reasoning, coding, and agentic benchmarks.