Your curated collection of saved posts and media
Experienced workers are turning to AI out of necessity, not curiosity. Many with years of expertise are struggling to find jobs, and see AI training as a way to stay relevant in a changing market. It is less about opportunity and more about survival. AI is not just reshaping careers at the top. It is redefining security across the workforce. https://t.co/lbAuL9EkQg

History will be divided into two eras: Before Starship and After We are about to witness a 100x increase in civilizational power https://t.co/476i4QS5uB

The headline literally said: Sell $TSLA. Check the date. 8 years ago this month. Why? “The competition is coming.” 👀 https://t.co/ZmrEaL48Wk
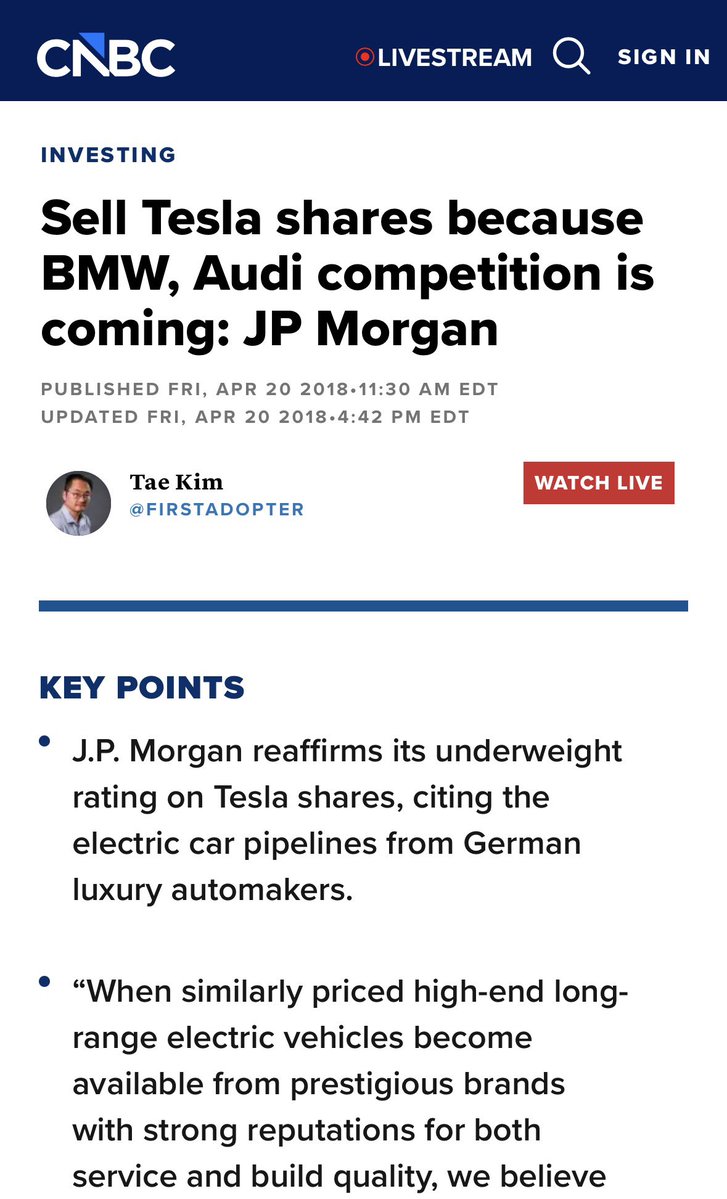
In different hands, Mythos would be an unprecedented cyberweapon I am not sure how we deal with this, except to note a narrow window where we know only 3 companies could be at this level of capability. But it may be Chinese models (maybe open weights ones?) get there in 9 months https://t.co/I7vrMDDyug


The Kardashev Scale is one of the coolest ways to think about how advanced a civilization really is Here is the cool visualization from https://t.co/yZ4k5GuhEb The Kardashev Scale: - Type 1: Harness all the energy on a planet - Type 2: Harness all the energy from a star - Type 3: Harness all the energy in a galaxy The Kardashev Scale is not just sci-fi. It shows us the long-term destiny of intelligent life…if we don’t destroy ourselves first
I think the issue with Anthropic's report is that if you reflect on this for a second, you realize their baselines must be dumpster fire. "avg LLM training speedup" of 52x? What does this mean? If it's MFU, you *have* to start at <1%. Just Autoresearch overfit? https://t.co/CRsZlXJn33
ALS is a disease that takes everything. Our goal is to give something back. Kenneth, who has been losing his ability to move and speak due to ALS, is exploring how Neuralink’s brain-computer interface technology can help translate neural signals into life-changing impact. https://t.co/FAe9ufYcOu
Kardaschev II or we're not a serious civilization https://t.co/luknSpeGnc
One day, we will be out there, among the stars


Marc Andreessen thinks Elon Musk hasn't just built successful companies, he might have actually cracked the code on how to manage for the next hundred years. The fundamental problem with any traditional organization that has multiple layers of management is what Andreessen brilliantly describes as "compounding lies." Every layer distorts reality just a little bit more until the original mission is completely lost in the bureaucracy. Musk’s method completely destroys that outdated corporate structure. It relies entirely on an extreme focus on substance and getting straight to the truth. By stripping away the noise, he has figured out the exact blueprint to reconcile being a chaotic fountain of ideas with being a ruthless, systematic builder.
https://t.co/KgRI96048i
Imagine scrolling Twitter here https://t.co/IbCadq8OOq


https://t.co/KgRI96048i


Sky full of stars. Following a successful lunar flyby, the Artemis II astronauts captured this breathtaking photo of our galaxy, the Milky Way, on April 7, 2026. https://t.co/pzqcLZNB71

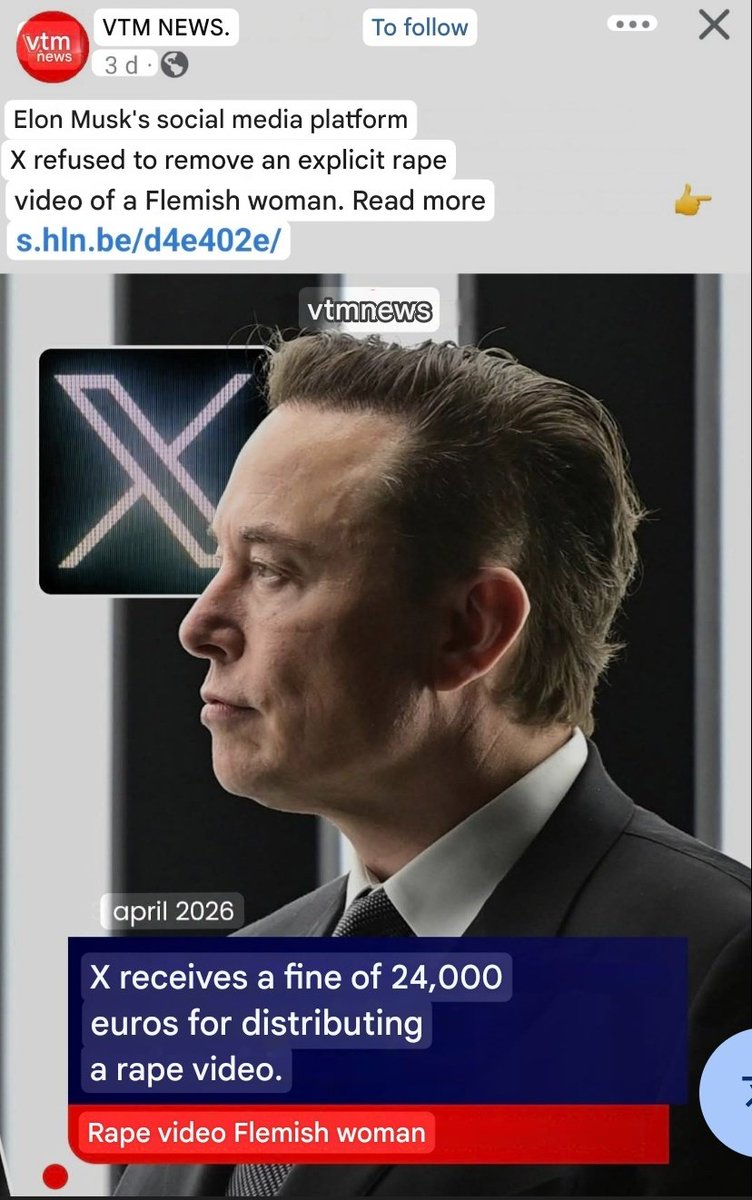
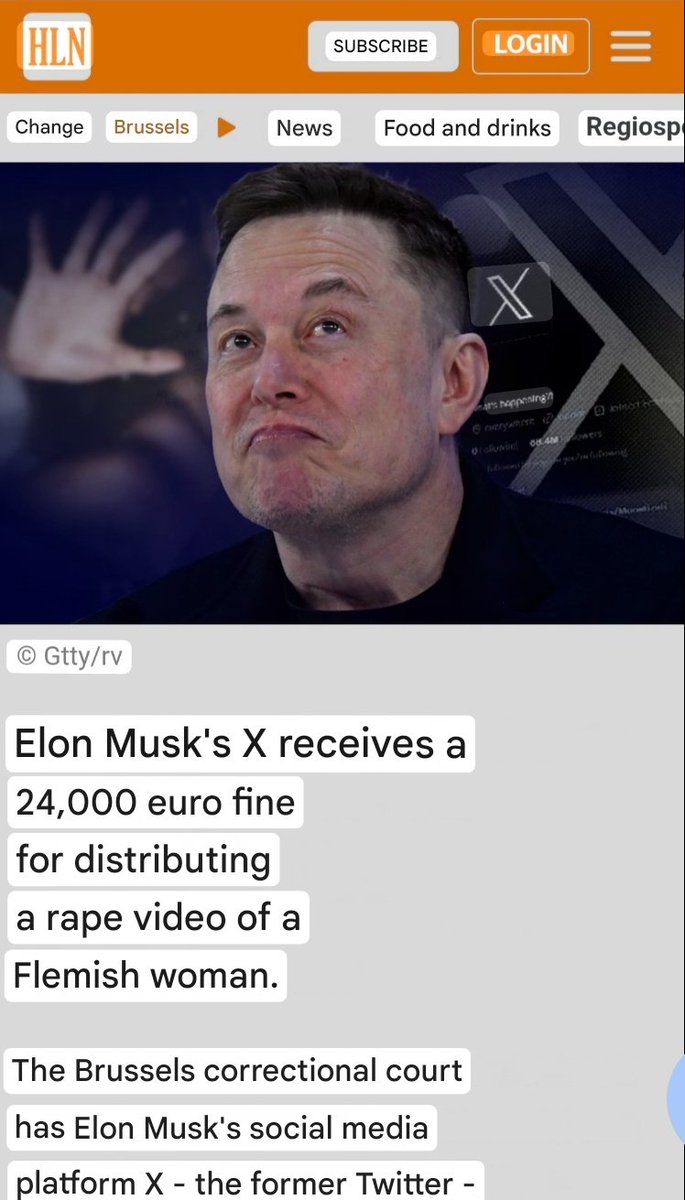
Headline: "Elon Musk's X receives a 24,000 euro fine for distributing a rape video of a Flemish woman" Reality: Elon Musk didn't own the company in 2020 Belgian media is intentionally conflating current ownership with the failures of the previous regime. They’re trying to taint Elon and 𝕏’s reputation over an incident from a completely different era Notice how they explicitly use "Elon Musk" and "𝕏" image instead of the old management? Timeline for the "reporters" in the back: - 2020: The incident happened - 2021: The video was finally removed via a judge's order - 2022: Elon Musk bought Twitter This is straight-up targeted hate disguised as news Pre-Elon 𝕏 operated completely differently and that broken system is exactly why he bought the platform and rebuilt it entirely This is the dark side of the fraud media that no one talks about..
Update on this story. Every news outlet in Belgium is reporting on it again now that the fine has been set. Just to recap: Video posted on 3rd of July 2020, complaint in Autumn 2020, video taken offline in February 2021… and Elon only buys Twitter in October 2022! Yet everyone u
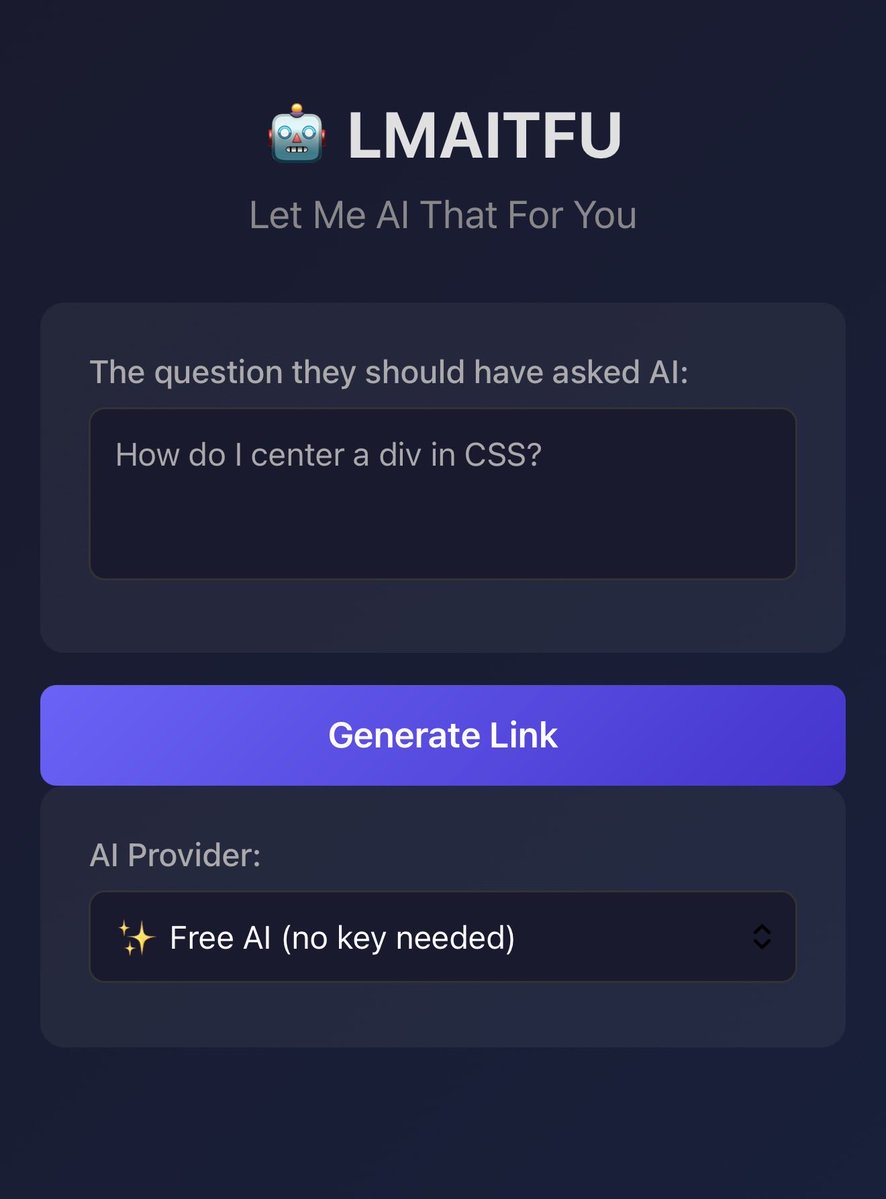
🤖 LMAITFU — Let Me AI That For You Remember LMGTFY? This is that, but for AI. Someone asks you something they could've just asked ChatGPT? Send them a link. They'll watch the AI answer it for them. Free. No signup. Maximum passive-aggression. https://t.co/H1whGX4SNB https://t.co/BUDfvcrRsy
@outsource_ Very. See my report: https://t.co/qeOiuNkiG0

@RyanLeeMiniMax If not, my AI made quite a report on it: https://t.co/qeOiuNkiG0

PixVerse dropped something in January. Cool. But what they just unveiled? Completely different beast. Meet PixVerse R1. This isn't AI video generation. This is real-time, interactive, living video. Not clips. Not renders. A digital reality engine. #PixVerseR1 @PixVerse_ https://t.co/iHcVEGX6jt
@OnlyTerp @NousResearch And I built you a guide to Hermes too: https://t.co/qeOiuNkiG0

You say you can't keep up. So I built you an AI to do it. https://t.co/kiuZ7QXLzb It's been working in public a few days now. What do you think? EVERYTHING is from the AI community here on X.

Voice ChatGPT can’t start a timer, but AGI is imminent! 🤦♂️ https://t.co/ah5iCdPdes

15 Top Cybersecurity Influencers to Follow in 2026 https://t.co/IRezmypstQ… A real honor to be listed #1. Great to be featured along with 14 terrific cybersecurity colleagues #cybersecurity #influencers https://t.co/irAACOgjLZ


15 Top Cybersecurity Influencers to Follow in 2026 https://t.co/IRezmypstQ… A real honor to be listed #1. Great to be featured along with 14 terrific cybersecurity colleagues #cybersecurity #influencers https://t.co/irAACOgjLZ

@velinus_sage @NotebookLM You might see what I did with https://t.co/kiuZ7QXLzb -- I have a Notebook LM feed already prepared for you, and a feed for your Hermes too.

"Hey AI prepare me for tomorrow's interview of @NousResearch's Hermes, which competes with @openclaw." "Here: https://t.co/qeOiuNkiG0 " My AI is an agent that https://t.co/xiuJ80Twa9 made for me and that I trained over months. You can't get this from Grok. See you tomorrow.
You have heard of @openclaw competitor from @NousResearch called “Hermes.” Tomorrow at 4 pm we will get nerdy with @theemozilla. Live. I will get people up who asks questions here first. https://t.co/USgYOeI4KW

Elon Musk reveals the real limiting factor for AI is not chips anymore, it’s electricity AI chip production is growing exponentially, but global electricity supply is only increasing 3–4% per year. We’re reaching the point where we produce more chips than we can actually turn on Power is the ultimate bottleneck in 2026. Data centers now face up to 7-year waits for grid connections, leaving many GPUs sitting idle Energy is the new oil of the AI race
Mark Cuban: You only need to be right one time to change your life forever. https://t.co/pDi3AppaJz
Mark Cuban: You only need to be right one time to change your life forever. https://t.co/pDi3AppaJz
Building the Future of Music and AI 🎼 Sir Lucian Grainge from Universal Music Group offers a compelling view into how AI is enhancing the creative process. Drawing from his experience working directly with artists on technology innovation, he shares a vision for AI as a true creative partner. ▶️ Watch the #NVIDIAGTC session: https://t.co/P0p2nXumqr


Thesis case study drop! Read here: https://t.co/OIGWw5ksWm AI Is Smart Enough, Let's Just Point and Talk to it ;) https://t.co/B2z4zLgErl

Thesis case study drop! Read here: https://t.co/OIGWw5ksWm AI Is Smart Enough, Let's Just Point and Talk to it ;) https://t.co/B2z4zLgErl

I'm thrilled to join @xAI and @SpaceX! After many years at Google DeepMind working on Gemini (including co-founding and launching Gemini Diffusion at Google I/O and contributing to Gemini, Gemma, AlphaCode, and Waymo), I can't wait to see what we build together. Few places turn science fiction into reality this fast. We're forging Grok into the most capable assistant yet, making physical intelligence real, and taking it all to Space. The last few years have been intense, but what's ahead is on another level. No better time to build — we can watch from the sidelines or be part of it. DMs are open. Understand the Universe 🚀
