@omarsar0
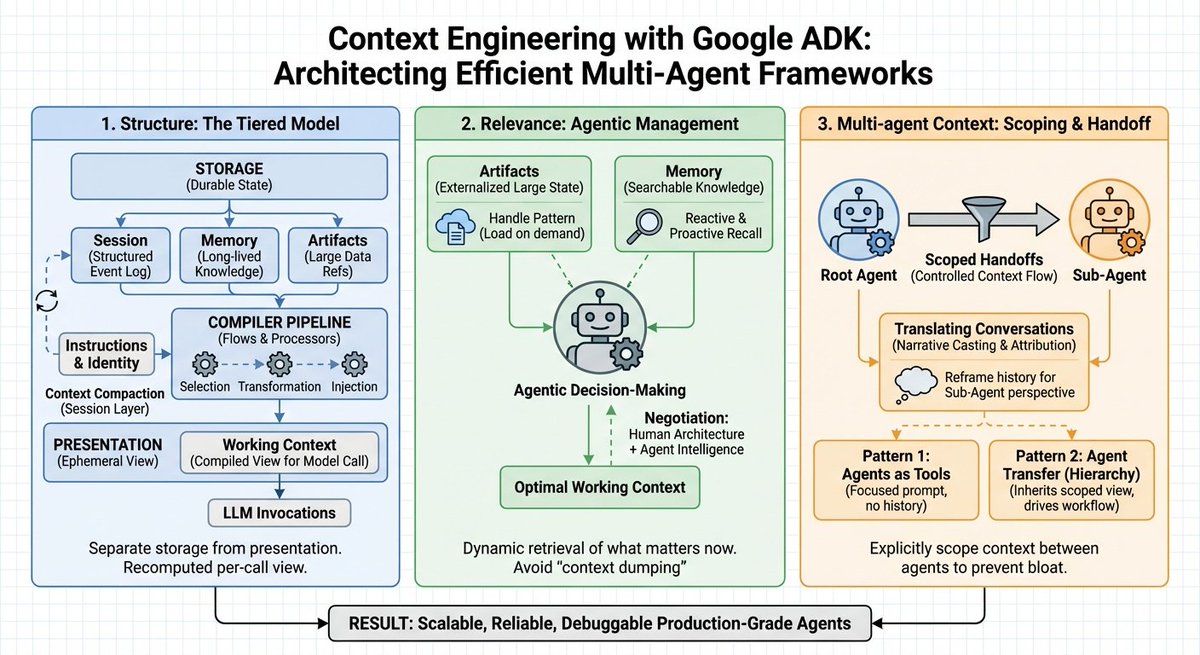
Google just published a banger guide on effective context engineering for multi-agent systems. Pay attention to this one, AI devs! (bookmark it) Here are my key takeaways: Context windows aren't the bottleneck. Context engineering is. For more complex and long-horizon problems, context management cannot be treated as a simple "string manipulation" problem. The default approach to handling context in agent systems today remains stuffing everything into the prompt. More history, more tokens, more confusion. Most teams treat context as a string concatenation problem. But raw context dumps create three critical failures: > cost explosion from repetitive information > performance degradation from "lost in the middle" effects > increase in hallucination rates when agents misattribute actions across a system Context management becomes an architectural concern alongside storage and compute. This means that explicit transformations replace ad-hoc string concatenation. Agents receive the minimum required context by default and explicitly request additional information via tools. It seems that Google's Agent Development Kit is really thinking deeply about context management. It introduces a tiered architecture that treats context as "a compiled view over a stateful system" rather than a prompt-stuffing activity. What does this look like? 1) Structure: The Tiered Model The framework separates storage from presentation across four distinct layers: 1) Working Context handles ephemeral per-invocation views. 2) Session maintains the durable event log, capturing every message, tool call, and control signal. 3) Memory provides searchable, long-lived knowledge outliving single sessions. 4) Artifacts manage large binary data through versioned references rather than inline embedding. How does context compilation actually work? It works through ordered LLM Flows with explicit processors. A contents processor performs three operations: selection filters irrelevant events, transformation flattens events into properly-roled Content objects, and injection writes formatted history into the LLM request. The contents processor is essentially the bridge between a session and the working context. The architecture implements prefix caching by dividing context into stable prefixes (instructions, identity, summaries) and variable suffixes (latest turns, tool outputs). On top of that, a static_instruction primitive guarantees immutability for system prompts, preserving cache validity across invocations. 2) Agentic Management of What Matters Now Once you figure out the structure, the core challenge then becomes relevance. You need to figure out what belongs in the active window right now. ADK answers this through collaboration between human-defined architecture and agentic decision-making. Engineers define where data lives and how it's summarized. Agents decide dynamically when to "reach" for specific memory blocks or artifacts. For large payloads, ADK applies a handle pattern. A 5MB CSV or massive JSON response lives in artifact storage, not the prompt. Agents see only lightweight references by default. When raw data is needed, they call LoadArtifactsTool for temporary expansion. Once the task completes, the artifact offloads. This turns permanent context tax into precise, on-demand access. For long-term knowledge, the MemoryService provides two retrieval patterns: 1) Reactive recall: agents recognize knowledge gaps and explicitly search the corpus. 2) Proactive recall: pre-processors run similarity search on user input, injecting relevant snippets before model invocation. Agents recall exactly the snippets needed for the current step rather than carrying every conversation they've ever had. All of this reminds me of the tiered approach to Claude Skills, which does improve the efficient use of context in Claude Code. 3) Multi-agent Context Single-agent systems suffer from context bloat. When building multi-agents, this problem amplifies further, which easily leads to "context explosion" as you incorporate more sub-agents. For multi-agent coordination to work effectively, ADK provides two patterns. Agents-as-tools treats specialized agents as callables receiving focused prompts without an ancestral history. Agent Transfer, which enables full control handoffs where sub-agents inherit session views. The include_contents parameter controls context flow, defaulting to full working context or providing only the new prompt. What prevents hallucination during agent handoffs? The solution is conversation translation. Prior Assistant messages convert to narrative context with attribution tags. Tool calls from other agents are explicitly marked. Each agent assumes the Assistant role without misattributing the broader system's history to itself. Lastly, you don't need to use Google ADK to apply these insights. I think these could apply across the board when building multi-agent systems. (image courtesy of nano banana pro)