@bertgodel
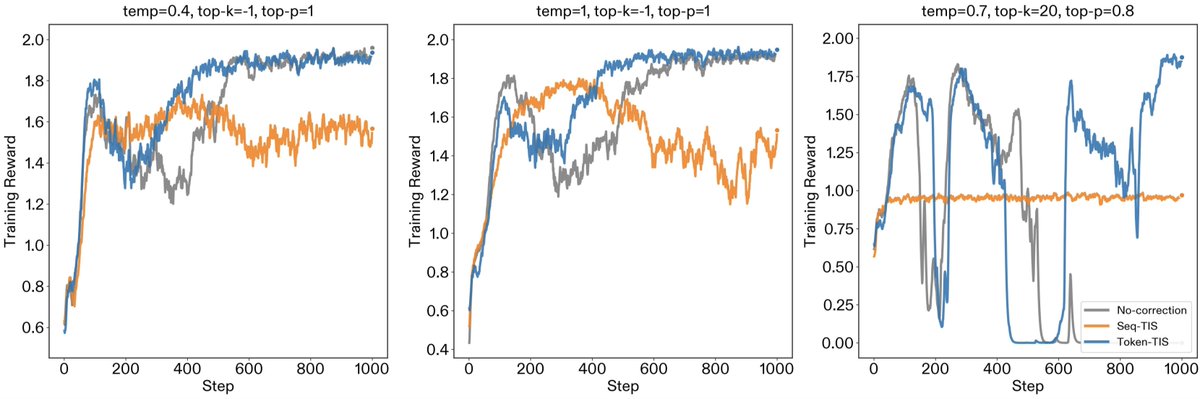
(1/5) New post: "Mismatch Praxis: Rollout Settings and IS Corrections". We pressure-tested solutions for inference/training mismatch. Inference/training mismatch in modern RL frameworks creates a hidden off-policy problem. To resolve the mismatch, various engineering (e.g., FP16 unification, deterministic kernels) and algorithmic (e.g., importance sampling) fixes have been proposed. In this work, we examine how rollout settings (temp, top-p, and top-k) affect mismatch, and how importance sampling corrections bear out in practice. We find that while Sequence-TIS is theoretically optimal, it can succumb to catastrophic variance in long-horizon contexts. Additionally, non-standard rollout settings create subtle mismatch patterns that require careful engineering fixes. Token-TIS with default rollout settings proved to be the most robust setting for long-horizon training.