@hayden_prairie
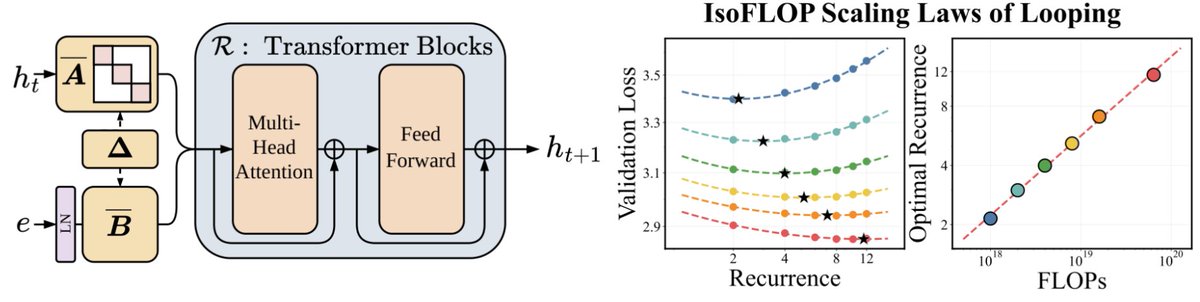
We’ve been thinking a lot about scaling laws, wondering if there is a more effective way to scale FLOPs without increasing parameters. Turns out the answer is YES – by looping blocks of layers during training. We find that predictable scaling laws exist for layer looping, allowing us to use looping to achieve the quality of a Transformer twice the size. Our scaling laws suggest that for a fixed parameter budget, data and looping should be increased in tandem! 🧵👇