@SergioPaniego
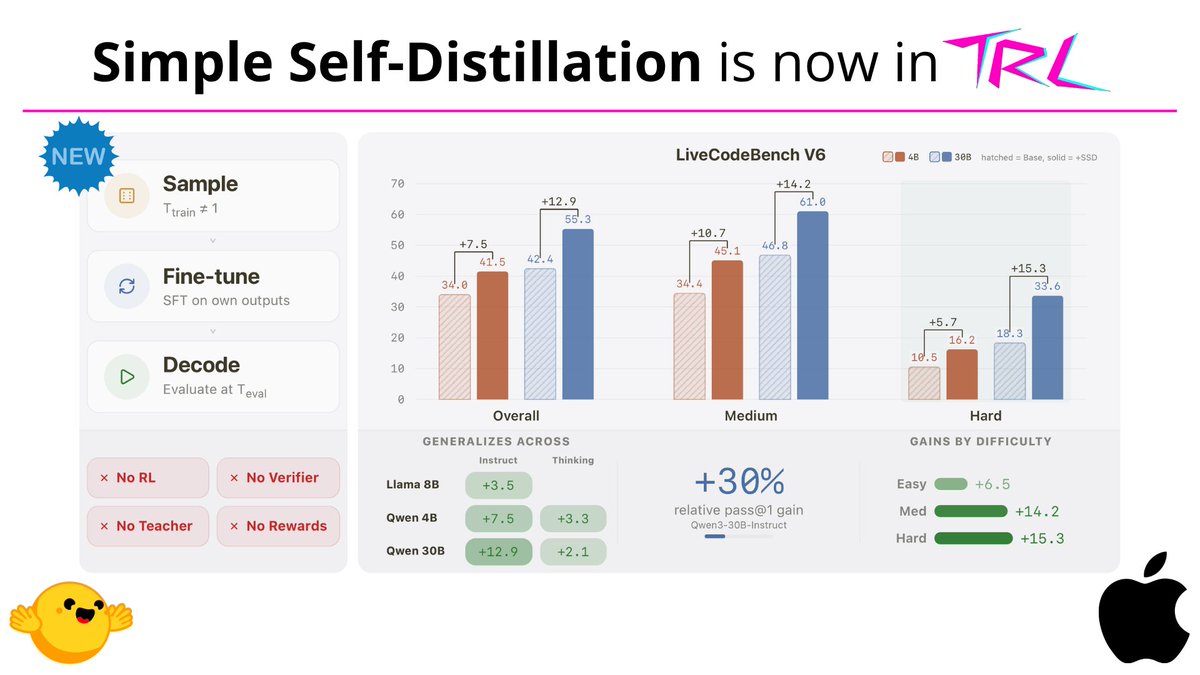
Earlier this month, Apple introduced Simple Self-Distillation: a fine-tuning method that improves models on coding tasks just by sampling from the model and training on its own outputs with plain cross-entropy and… it's already supported in TRL, built by @krasul. you can really feel the pace of development in the team 🐎 paper by @onloglogn, @richard_baihe, @UnderGroundJeg, Navdeep Jaitly, @trebolloc, @YizheZhangNLP at Apple 🍎 how it works: the model generates completions at a training-time temperature (T_train) with top_k/top_p truncation, then fine-tunes on them with plain cross-entropy. no labels or verifier needed you can try it right away with this ready-to-run example (Qwen3-4B on rStar-Coder): https://t.co/zizfISD6bq or benchmark a checkpoint with the eval script: https://t.co/mKlafTyKSe one neat insight from the paper: T_train and T_eval compose into an effective T_eff = T_train × T_eval, so a broad band of configs works well. even very noisy samples still help want to dig deeper? paper: https://t.co/aj1ZAcr8Mw trainer docs: https://t.co/TNVz93kZi9