@mercor_ai
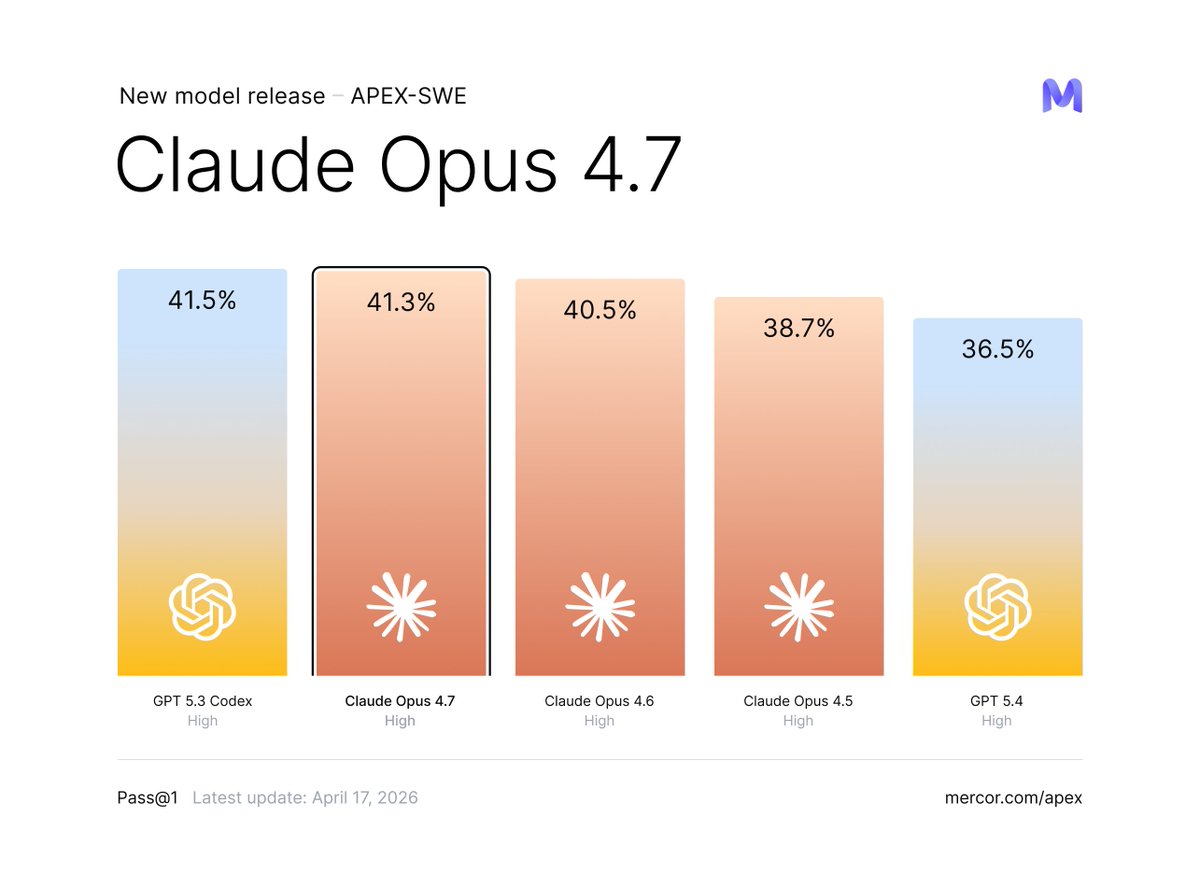
We ran @AnthropicAI Claude Opus 4.7 (High) on APEX-SWE, our benchmark for real-world software engineering work. It scores 41.3% pass@1, placing 2nd on the leaderboard. It is only 0.2% away from GPT 5.3 Codex (High). https://t.co/4U6pKtrvI0