Your curated collection of saved posts and media
To showcase @Simulon's capability with high-fidelity assets and to highlight the difference between what you see in real-time AR versus the precision of offline cloud rendering, we've made a video using a detailed human scan by @Ten_24. Our workflow was designed to closely align the visuals in real-time AR with our offline cloud renders. The video below demonstrates this, transitioning between the AR preview and the final cloud render. This preview lets creators foresee the final VFX shot, reducing guesswork in lighting and composition.
Querying knowledge graphs is a big topic; Wenqi Glantz does a great job showing off 7 different strategies for efficiently querying them, all using LlamaIndex! https://t.co/4c0tuIokud https://t.co/5ce9HSAYlm

Open source your datasets on @huggingface to appear on the Dataset Creators Hall of Fame https://t.co/XRGjRvqAQE https://t.co/36cobdrWDW
@BlancheMinerva We should have a Dataset Creators Hall of Fame, at the very least.

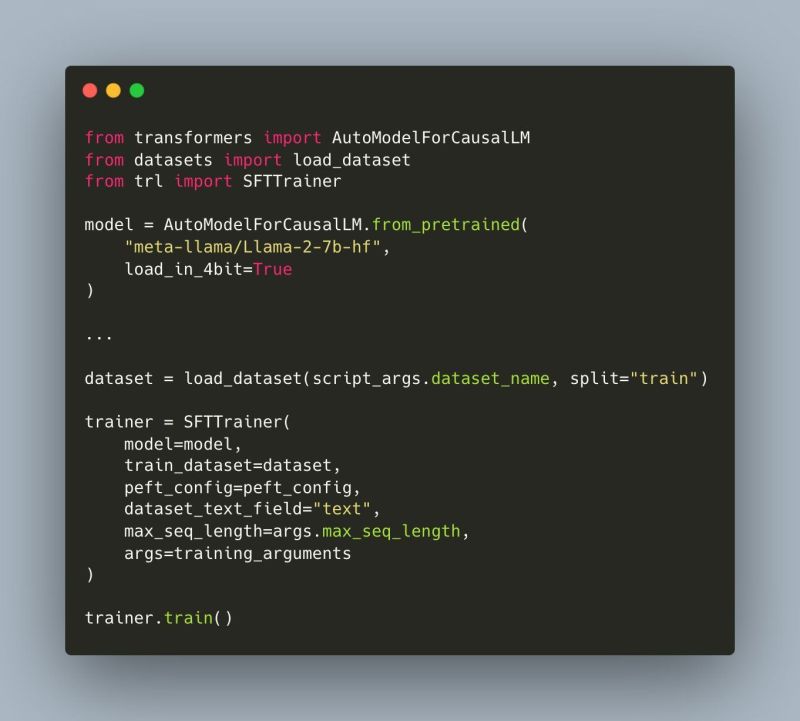
Anybody can train a custom Mistral model on their own dataset in just a few lines of code with TRL! 🚀 The SFTTrainer supports DeepSpeed for distributed training or PEFT if you are limited by GPU resources. TRL: https://t.co/BGwjzYWfzF Full script: https://t.co/9ZEqenczsM
GPT-4V is blowing my mind The demos are awesome, but too scattered I wanted to break down the 100+ use cases I've seen so far into a simple framework Check out what I found with full descriptions and examples. Agree or disagree with the categories? Use Case Breakdown w/ Examples: 1. Describe - Simply describing what is in an image * Animal Identification: https://t.co/jPm105FAGv * What's in this photo?: https://t.co/skDrKrf8KH 2. Interpret - The biggest of the lot, explain the meaning and provide more context behind an image. This is the layer deeper than a surface level description. * Technical Flame Graph Interpretation: https://t.co/ZFXoyfw6r1 * Schematic Interpretation: https://t.co/bECb8fYe89 * Twitter Thread Explainer: https://t.co/qlELi2LugD 3. Recommend - Offer critiques, suggested changes, or recommendations based off an image * Food Recommendations: https://t.co/OSYrlyLbfZ * Website Feedback (a bunch of these): https://t.co/zuxux3vMVM * Painting Feedback: https://t.co/nvN5oeTBIy 4. Convert - Convert images into other forms (code, narrative, etc.) or generate something new. Massive opportunity to build a ton of product here. Major things to come * Figma Screens > Code: https://t.co/07gEJIDeLG * Adobe Lightroom Settings: https://t.co/VEwTMsnseN * Suggest ad copy based on a webpage: https://t.co/geseU7zLjT 5. Extract - Extract entities within an image or provide structured output * Structured Data From Driver's License: https://t.co/ZWCcRRsJ8y * Extract structured items from an image: https://t.co/KqP6AdMSZk * Handwriting Extraction: https://t.co/JSOX64IVYE 6. Assist - Offer solutions based on the image * Excel Formula Helper: https://t.co/mDmjDaNYWh * Find My Glasses: https://t.co/prQpABHKRz * Live Poker Advice: https://t.co/nESYipC79I * Video game recommendations: https://t.co/PnFH7FH2C5 7. Evaluate - Subjective judgement based on the image * Dog Cuteness Evaluator: https://t.co/0JkSXx8TBR * Bounding Box Evaluator: https://t.co/5OuYwcZsIL * Thumbnail Testing: https://t.co/LfeWqUQRc1
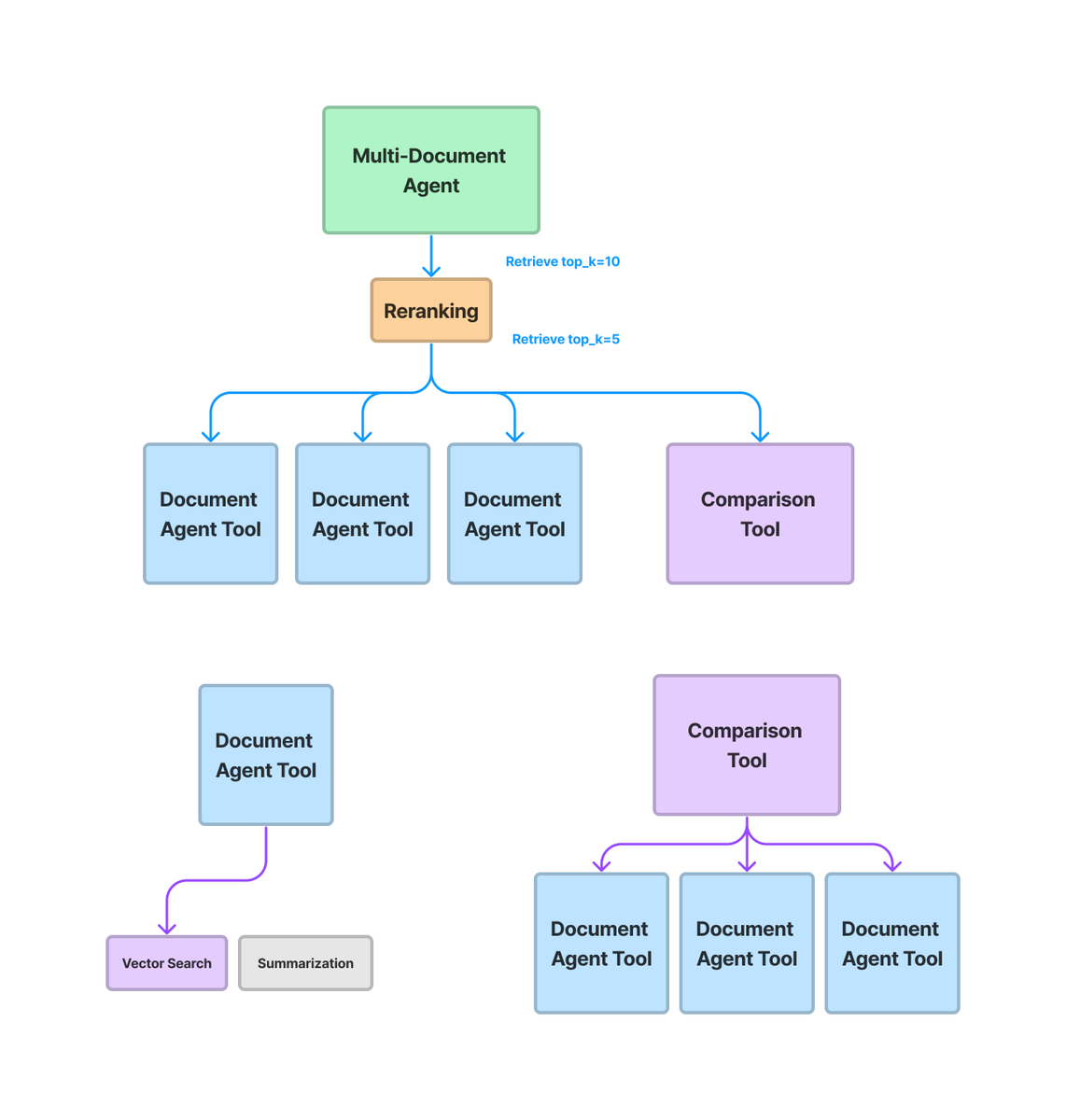
Multi-Document Agents (V1) 🤖 In our brand-new release, agents can now 1️⃣ Retrieve/rerank over large #’s of docs 2️⃣ Query plan to compare multiple docs (async). Leads to way more advanced doc analysis than naive RAG -we tested it over our own docs 🧵! https://t.co/bWYv0R7J2B https://t.co/Zsw1xTxIOJ
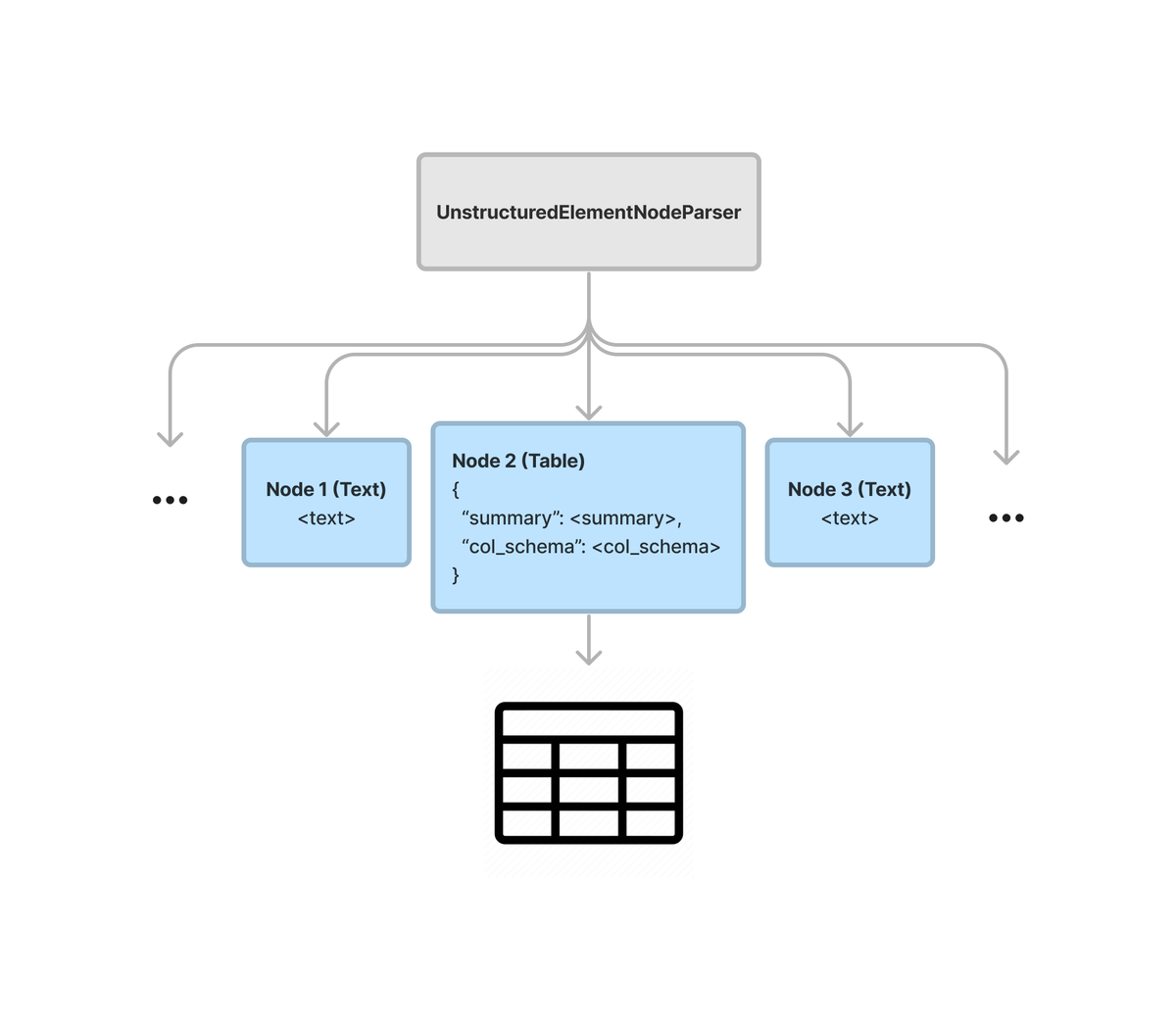
Text splitting is a crucial component of setting up an ETL pipeline for your LLM/RAG app. But you can do way more than split in a flat list! ✨Our brand-new @llama_index parser allows you to *hierarchically* parse a data graph of text and tables, letting you model/query both unstructured and tabular data in the same document 🔥 ✅ Structured Table Summarization: We use LLMs to extract a structured summary + schema from each unformatted table. ✅ Hierarchical Node References: Have each summary link to the table. Plug into recursive retrieval. Built on top of @UnstructuredIO 🙌. Previously, we had very custom, involved notebook tutorials showing how you can parse out tables from SEC filings. Now you can parse out a table/text data graph in 5 lines of code 🔥 https://t.co/Q7JMzELKU4
Excited to launch my new AI Job Board and dedicated AI Jobs newsletter section! AI is going to redefine the job landscape, and thousands of jobs that haven't been imagined will emerge in the upcoming era. Doing my part to help readers navigate the next big opportunity! https://t.co/zLOvsjo8Xn
For $500 worth of compute, this team fine-tuned a 7B parameter model to give better answers than a 70B model (Llama2): https://t.co/3VazjtreFv https://t.co/sq9ICbDSLz
I figured running LLMs at scale was expensive but damn copilot is losing $20/month per user and up to $80/month per user https://t.co/p0NvIvZPGy
ElevenLabs launches AI dubbing Blog: https://t.co/ixIpsZmqLC https://t.co/cHBF3sKYg4
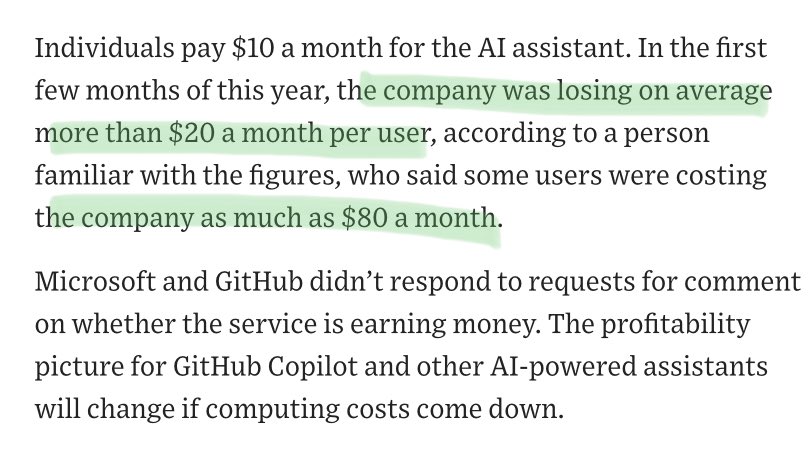
The question “How can I improve my RAG system” is hard because there’s like 50+ things you can try. I usually give the advice of trying the lowest-hanging fruit first (“table stakes”), and progressively try out more advanced techniques: 🔎 Advanced Retrieval 🤖 Agents ⚙️ Fine-tuning We’ll be giving a glimpse into all of this during our AI Engineer Summit workshop and talk! Sneak preview of some resources below 👇 Chunk Sizes (Table Stakes): https://t.co/gczGFeZDW5 Advanced Retrieval Guides: https://t.co/4c4wOMR5fG Multi-Document (Agents): https://t.co/faSQCnwBMK Fine-tuning: https://t.co/6dsHVxlhvW @disiok is leading our workshop and it’s happening RIGHT NOW - if you can’t make it don’t fret, we’ll make the materials available after :)
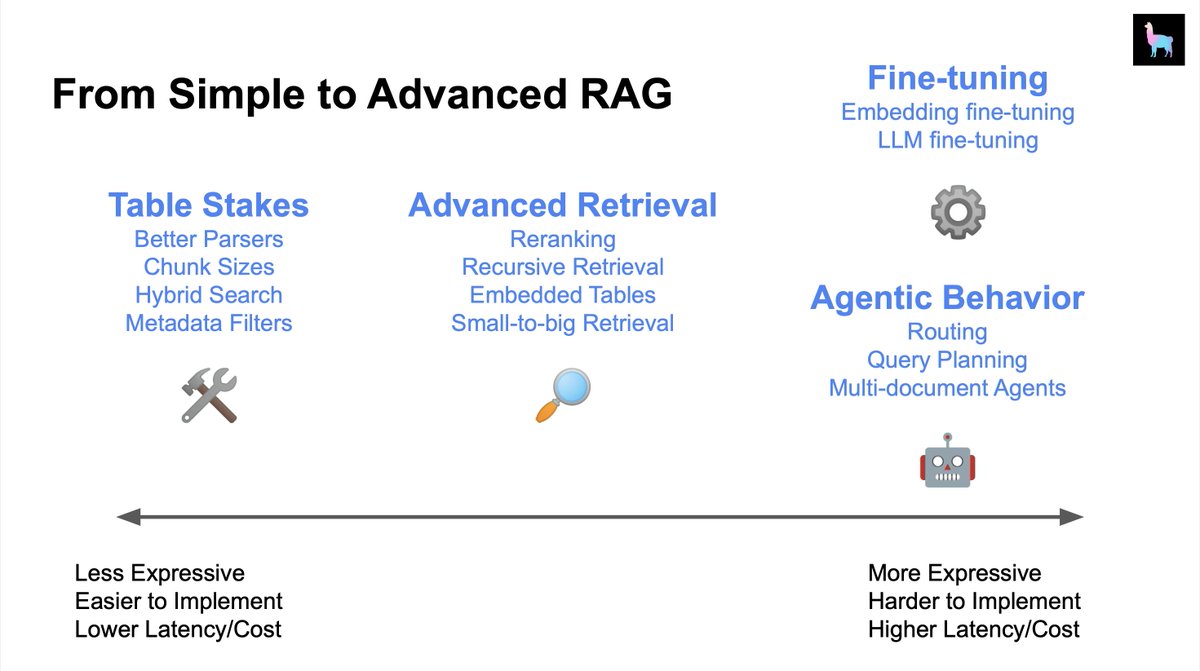
Finetuning the embedding model can allow for more meaningful embedding representations, leading to better retrieval performance. @llama_index has abstraction for finetuning sentence transformers embedding models that makes this process quite seamless. Let's see how it works 👇 https://t.co/cLh2n1CH5p
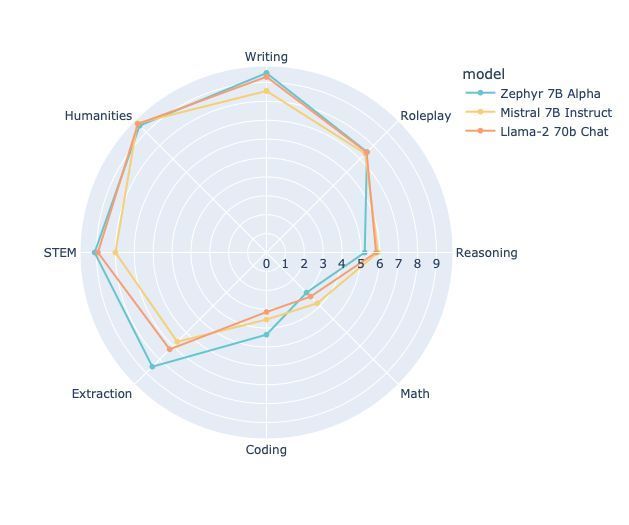
Do we need RL to align LLMs with Human feedback? 🤔 Direct Preference Optimization (DPO) allows training models like ChatGPT directly on Human preferences🤯 @huggingface trained Zephyr a 7B model with DPO outperforming Llama-2 70B chat on the MT Bench benchmark! 🥇 🧶 https://t.co/sazlXZc6Il

Long context models are popular, but is it the final solution to long text reading? We introduce a fundamentally different method, MemWalker: 1. Build a data structure (memory tree) 2. Traverse it via LLM prompting Outperforms long context, retrieval, & recurrent baselines. (1/n) https://t.co/JrDME0ZnpB
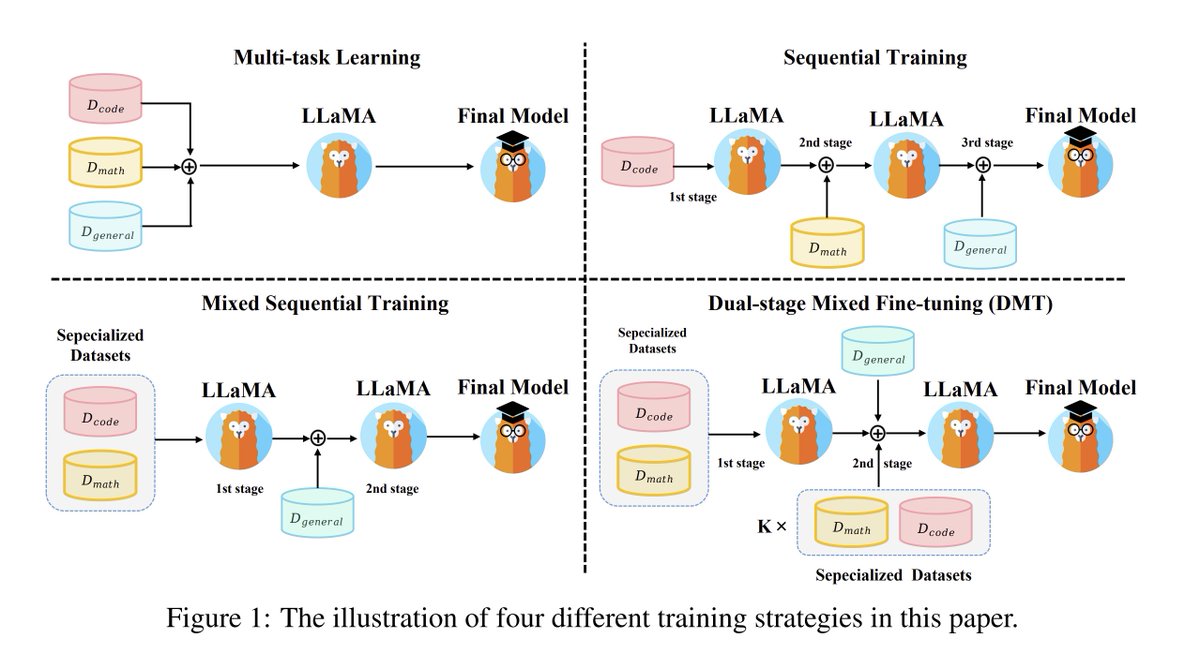
How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition abs: https://t.co/zPljd4WhnW Evaluates how data mixtures affect learning of specialized and general skills. Proposes dual-stage mixed finetuning to avoid catastrophic forgetting and conflicts observed with multi-task learning.
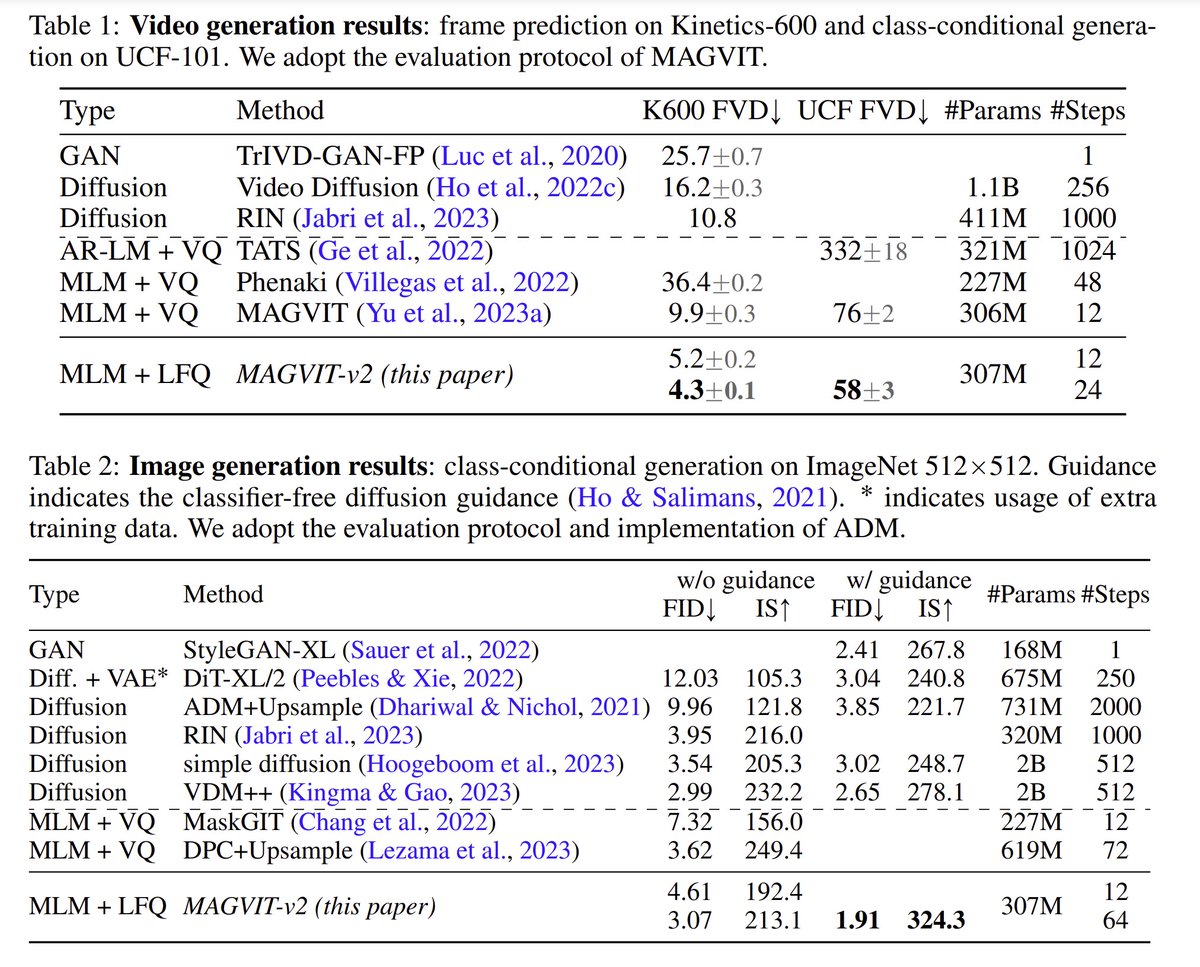
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation abs: https://t.co/MXOldpo8uk website: https://t.co/7LaOqBANZY This paper from Google & CMU introduces MAGVIT-v2, a joint image-video tokenizer which can be used with a masked language model to perform image and video generation. Obtains SOTA on class-conditional ImageNet 512x512 generation and Kinetics600 frame prediction. Also demonstrates use of MAGVIT-v2 for video compression.

SALMON: Self-Alignment with Principle-Following Reward Models abs: https://t.co/n8ikVW3WUh code: https://t.co/UtUtZilnaH This paper from IBM proposes a new RLAIF paradigm that uses the LLM to judge responses based on specific principles, and trains a reward model conditional on the principles. Their 70b model surpasses Llama2-70b-chat on various benchmarks.

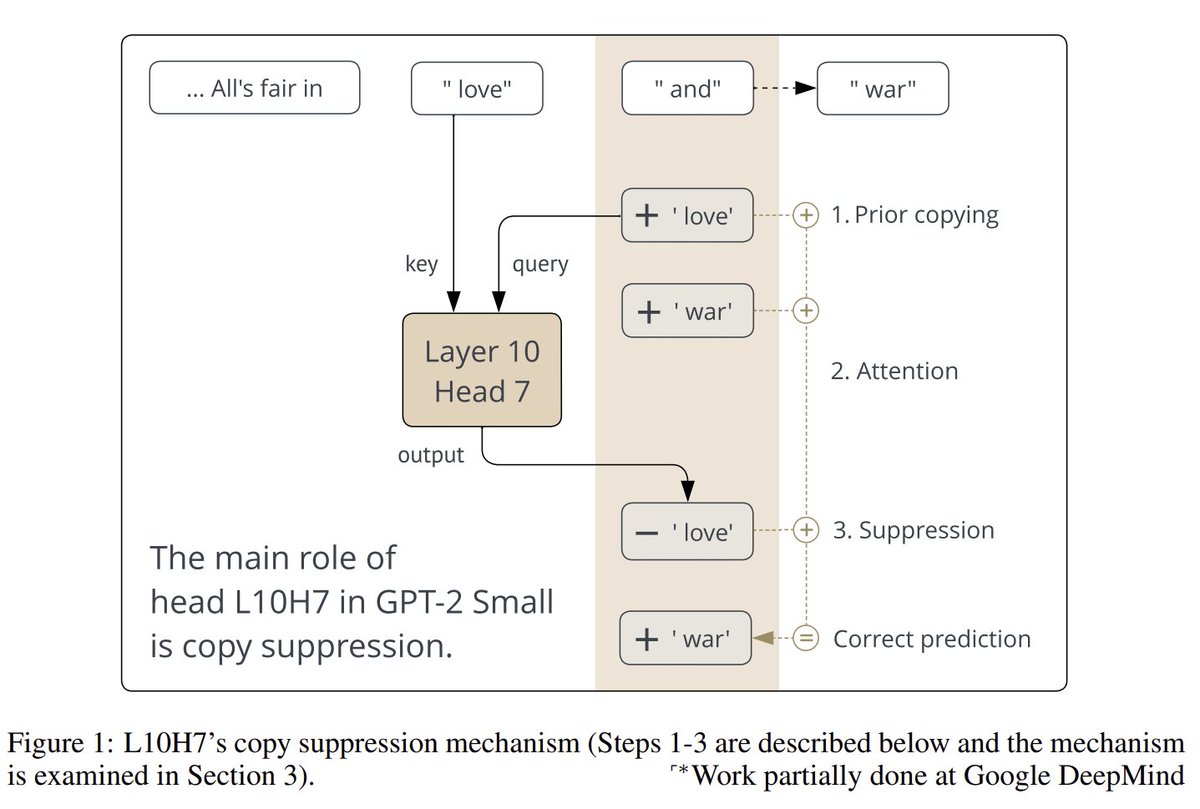
Copy Suppression: Comprehensively Understanding an Attention Head website: https://t.co/szSr7L6KZ1 abs: https://t.co/yD459BioOs "To the best of our knowledge, this is the most comprehensive description of the complete role of a component in a language model to date." https://t.co/fQUUvc2ypp
Masking PII 🔐 is crucial in many LLM app settings (especially healthcare 🥼), whether you're using a local or third-party LLM! @wenqi_glantz has a great article on using a @huggingface NER model in your @llama_index RAG pipeline for PII masking 👇: https://t.co/9cKkUvZxHd https://t.co/5ubwNLv0z9
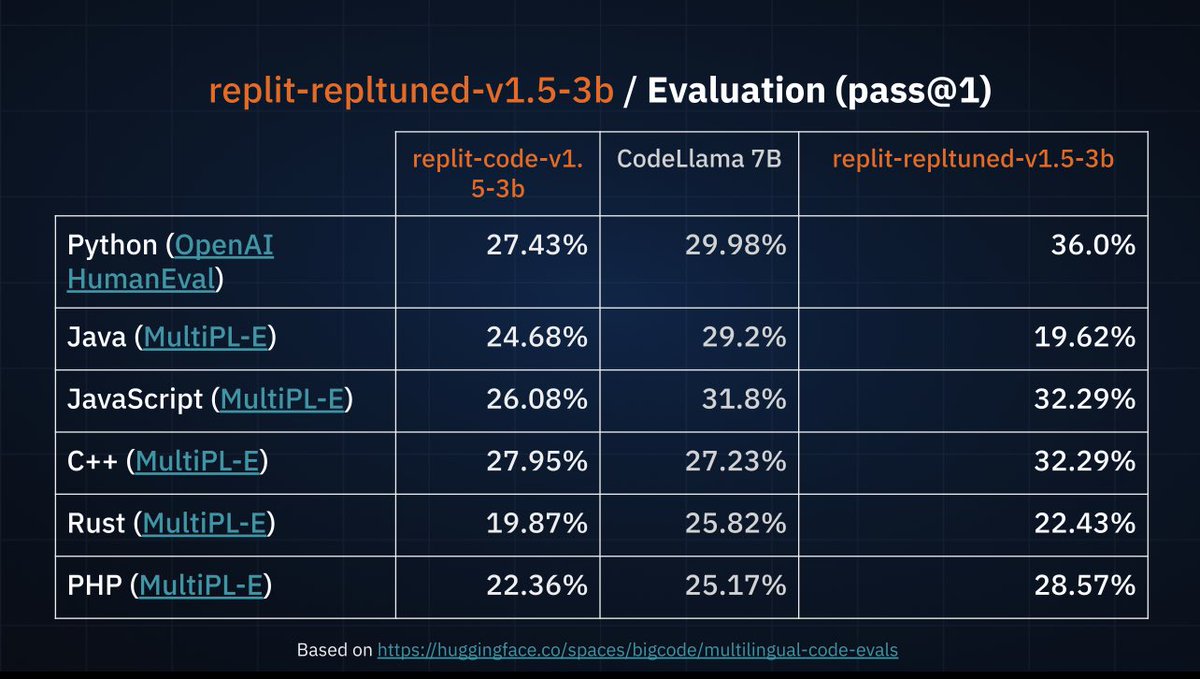
Just announced new open-source SOTA 3b code model, which beats CodeLlama7B when fine-tuned. https://t.co/zRa7dIViwZ
Heyyy Michele from @Replit announcing a new commercially available open source model for code on stage #AIRSummit , replit-code-v1.5-3b Supports 30 languages, a mix from data from stack exchange. Cc @amasad 👀 https://t.co/kaDMvMuK5H
Starting today, we’re giving free access to Replit AI. Now anyone can use Replit AI to debug, autocomplete, and turn natural language into code with one-click. Get started by creating a free Replit account.

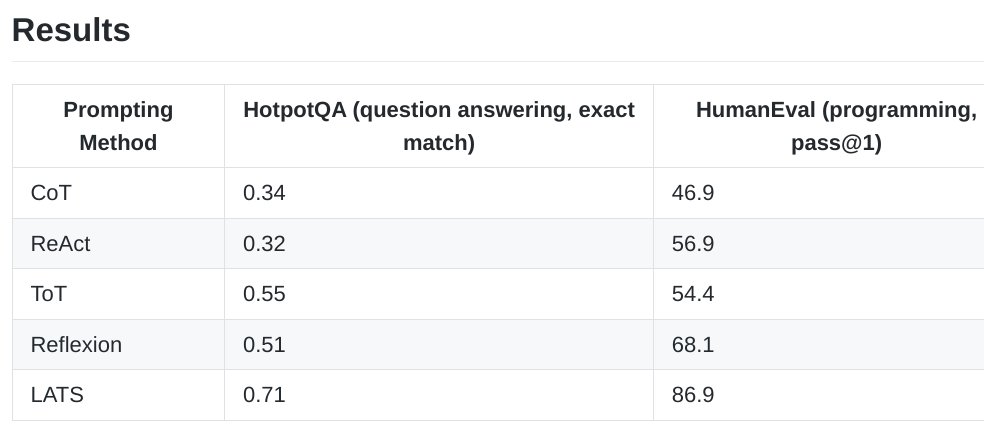
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models Substantially improving over the existing prompting methods such as Reflexion, e.g., 68.1% -> 86.9% on HumanEval with GPT-3.5 proj: https://t.co/uEVF4hwW1C abs: https://t.co/ewOwtf9Xpb https://t.co/EvIEt8W0zu
Huge. Disney just introduced their new robot. It was fully trained in simulation with Reinforcement learning just like OpenAI did with their robotic hand. The sim trained policy allows for rough terrain, traversal, and bump recovery. The whole project only took a year. https://t.co/ej4g6zLaLC
Large Language Models (in 2023) An excellent summary of the research progress and developments in LLMs. I appreciate that @hwchung27 made this content publicly available. It's a great way to catch up on some important themes like scaling and optimizing LLMs. talk: https://t.co/KEwnxvo0eT slides: https://t.co/DtkPnzuMzM

Llama-2 can now be fine-tuned on your own data in just a few lines of code. The script handles single/multi-gpu and can even be used to train the 70B model on a single A100 GPU by leveraging 4bit. @huggingface https://t.co/2mNalgSAc6
Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets Present a collection of seven novel datasets, which cover ~100M molecules and >3K sparsely defined tasks, totaling >13B labels of both quantum and biological nature https://t.co/9r9xJQFFFK https://t.co/a48oeDWxfC

🌍⏳ Do LMs Represent Space and Time? In this newsletter, we look at how space and time has been represented in LLMs, featuring work by @wesg52, @gg42554, @faisal_thisis, @anas_ant, @dirk_hovy, @VeredShwartz, @Dorialexander and others. https://t.co/XnwWv2d12a https://t.co/8mEBtDodg6
M2 Ultra serving Q8_0 LLaMA-v2 70B to 4 clients in parallel https://t.co/5FrMdn7sjF
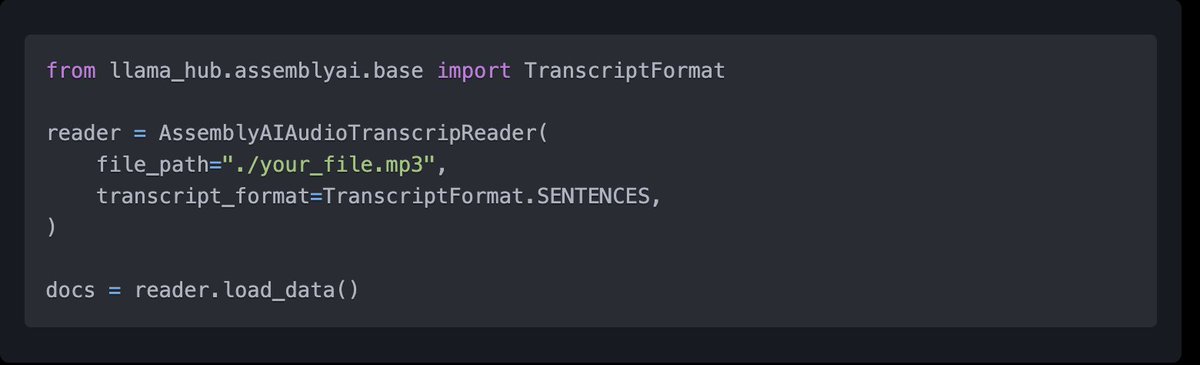
Audio transcription is a core component of any multi-modal LLM app 🎙️ It’s complex too: there’s different ways to represent the output text, incl. in SRT/VTT subtitles. Huge shoutout to @patloeber for the @AssemblyAI integration: easily transcribe audio a bunch of diff ways 👇 https://t.co/ksKPLgs6J9
Oldies but Goldies: D. Lee et S. Seung, Learning the parts of objects by non-negative matrix factorization, Nature (1999). Lee and Seung proposed the most popular matrix factorization algorithm, which operates by multiplicative updates. https://t.co/knuRHQNTDe https://t.co/LiugTkpV5Q

This is pretty wild. A new paper by Google found that Perplexity and GPT-4 w/ prompting outperformed Google Search. Anecdotally, I've also noticed more non-tech people using Perplexity over other LLMs for search queries. Is Google search is slowly getting replaced?

