@iScienceLuvr
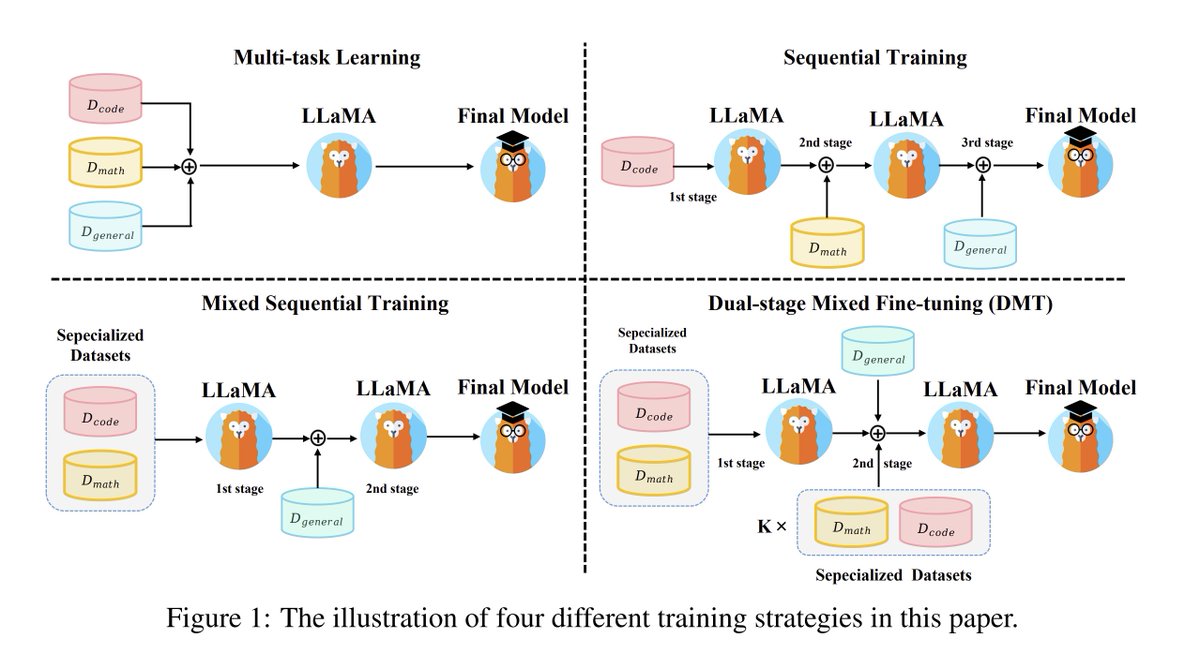
How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition abs: https://t.co/zPljd4WhnW Evaluates how data mixtures affect learning of specialized and general skills. Proposes dual-stage mixed finetuning to avoid catastrophic forgetting and conflicts observed with multi-task learning.