@iScienceLuvr
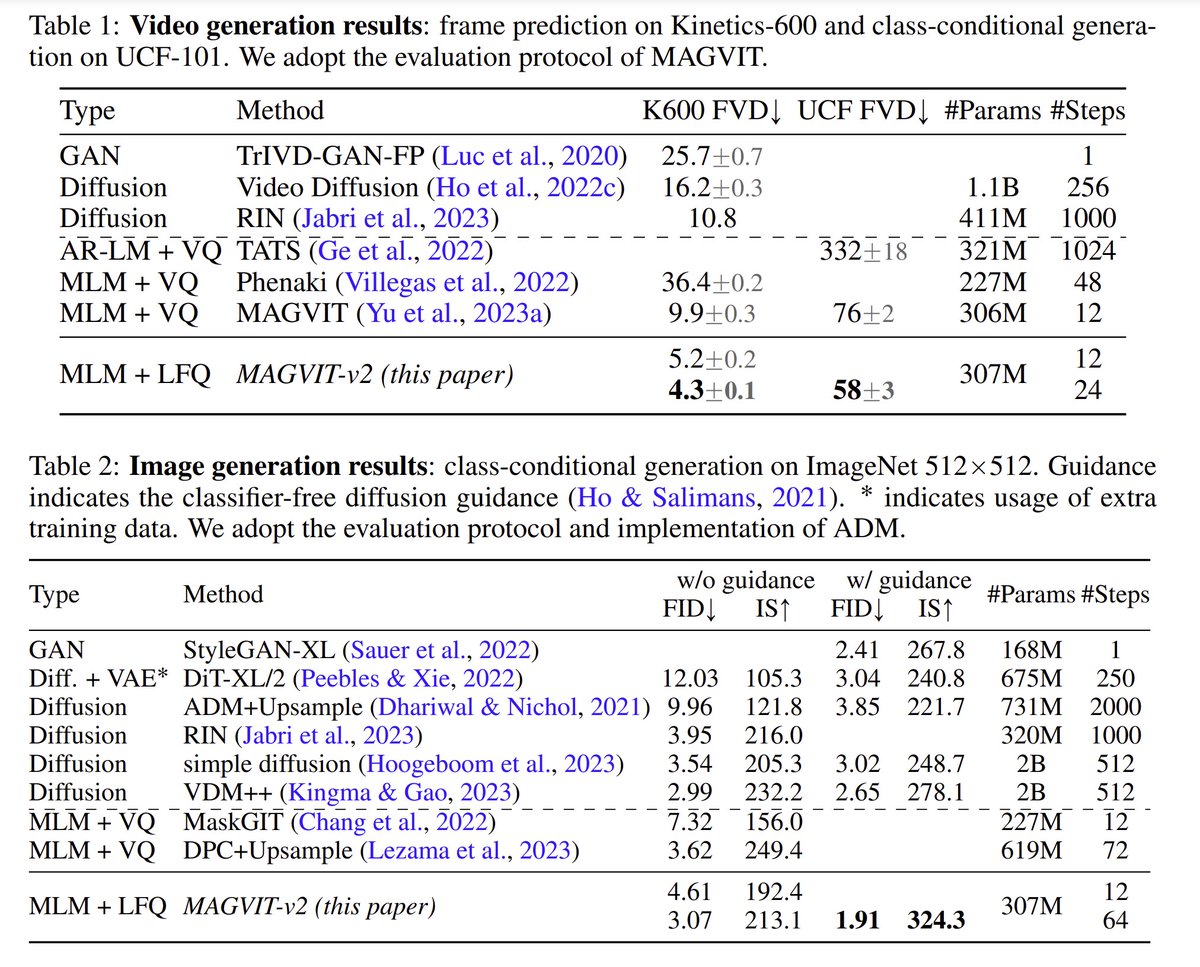
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation abs: https://t.co/MXOldpo8uk website: https://t.co/7LaOqBANZY This paper from Google & CMU introduces MAGVIT-v2, a joint image-video tokenizer which can be used with a masked language model to perform image and video generation. Obtains SOTA on class-conditional ImageNet 512x512 generation and Kinetics600 frame prediction. Also demonstrates use of MAGVIT-v2 for video compression.