Your curated collection of saved posts and media
A few big papers throwing question on "does RLAIF work" yesterday. The first is a paper by @archit_sharma97 is a pretty timely critique of RLAIF. It shows SFT on GPT 4 outputs > DPO + RLAIF on GPT4 ratings of GPT3.5 completions. A few things aren't surprising: 1. The most important thing you can do right now is have better completions going into fine-tuning, rather than worrying about algorithm 2. The second best thing is worrying about prompts, which us RLHFers don't do. ShareGPT and similar things without filtering are bad. Preference optimization is likely more sensitive than SFT, given the newer optimizers. There's still lots more headroom in improving RLAIF imo than SFT. Looking at popular datasets like Nectar or Ultrafeedback there are so many bugs that can be filtered by heuristics. We also got HELM-Instruct, which showed wacky results on different evaluators. All of Amazon MTurk, Scale AI, GPT4, and Claude aren't very correlated. Seeing this, I thought training a model with the evaluator you use is prolly needed, they may not transfer too. So, while GPT4-as-a-judge is popular, it has a long way to go. Finally, in the appendix of @Muennighoff 's paper GRIT was more uncertainty over how we use GPT4 as judgments for MT Bench. Archit's paper: https://t.co/QeXRzseLCZ HELM-Instruct: https://t.co/wODR3Srx44 GRIT paper: https://t.co/afm4c0hVt0
New (2h13m 😅) lecture: "Let's build the GPT Tokenizer" Tokenizers are a completely separate stage of the LLM pipeline: they have their own training set, training algorithm (Byte Pair Encoding), and after training implement two functions: encode() from strings to tokens, and decode() back from tokens to strings. In this lecture we build from scratch the Tokenizer used in the GPT series from OpenAI.

I really appreciate that @ykilcher still does technical paper deep dives 🙏 (V-JEPA video: https://t.co/zMrDJXyR5m) https://t.co/T6FGsD7vuO
working hard on my YOLO-World tutorial - model architecture - processing images and video in Colab - prompt engineering and detection refinement - pros and cons of the model new upload tomorrow on @roboflow YT channel: https://t.co/l0mRdT63Jc https://t.co/ypz33C2XDS
I'm starting to get more and more serious with YOLO-World; trying to solve real-life problems. I wanted to see if YOLO-World could recognize that the holes had been filled out. It was pretty tricky, but I learned a little about prompting. ↓ read more https://t.co/sMBDK40wFb
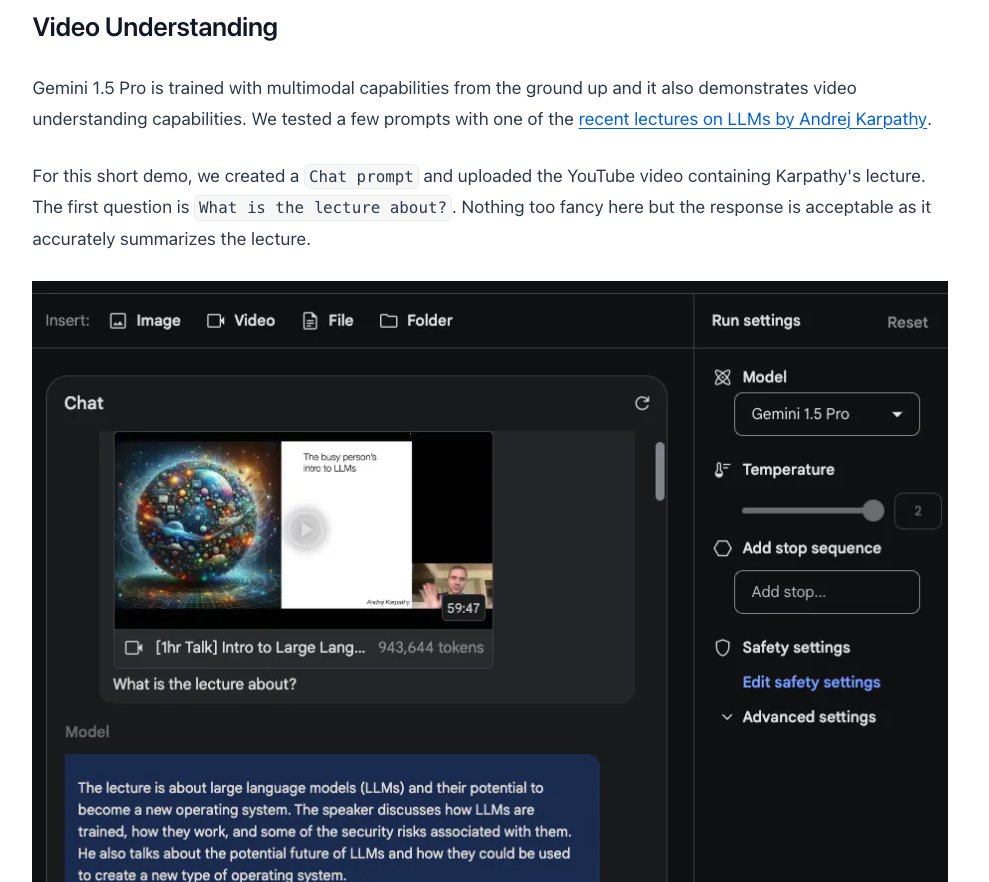
The Gemini 1.5 Pro model guide is live! With support of up to 1 million tokens context length, you may be wondering what's possible with Gemini 1.5 Pro. My overall impression after our first round of testing is that Gemini 1.5 Pro is among the most powerful long context LLMs available today. I've published a summary of Gemini 1.5 Pro's capabilities along with concrete examples in the prompting guide. These are just preliminary tests. I will continue to analyze and document the model's capabilities and limitations. Stay tuned! From preliminary experiments, Gemini 1.5 Pro shows impressive capabilities around multimodal reasoning, video understanding, long document question answering, code reasoning on entire codebases, and in-context learning. One insight from testing this model is that we will have different kinds of LLMs that support different types of use cases. Gemini 1.5 Pro is not meant to be a model to reign among all. The long context LLMs are not meant to cover every use case imaginable, they are meant to unlock complex use cases that were unimaginable before with LLMs. Link to guide below ↓
🚀 🏥 Very proud to announce BioMistral, a collection of open-source pre-trained LLMs for the medical domain 📰Arxiv: https://t.co/Zarwhb807S 🏥 BioMistral 7B model: https://t.co/h00IOmXC66 More info: https://t.co/eiFj4bk8b5 @CNRSinformatics @LaboLS2N @taln_ls2n @LabrakYanis https://t.co/E9nBzJVM9Y

DiLightNet Fine-grained Lighting Control for Diffusion-based Image Generation paper presents a novel method for exerting fine-grained lighting control during text-driven diffusion-based image generation. While existing diffusion models already have the ability to generate images under any lighting condition, without additional guidance these models tend to correlate image content and lighting. Moreover, text prompts lack the necessary expressional power to describe detailed lighting setups. To provide the content creator with fine-grained control over the lighting during image generation, we augment the text-prompt with detailed lighting information in the form of radiance hints, i.e., visualizations of the scene geometry with a homogeneous canonical material under the target lighting. However, the scene geometry needed to produce the radiance hints is unknown. Our key observation is that we only need to guide the diffusion process, hence exact radiance hints are not necessary; we only need to point the diffusion model in the right direction. Based on this observation, we introduce a three stage method for controlling the lighting during image generation. In the first stage, we leverage a standard pretrained diffusion model to generate a provisional image under uncontrolled lighting. Next, in the second stage, we resynthesize and refine the foreground object in the generated image by passing the target lighting to a refined diffusion model, named DiLightNet, using radiance hints computed on a coarse shape of the foreground object inferred from the provisional image. To retain the texture details, we multiply the radiance hints with a neural encoding of the provisional synthesized image before passing it to DiLightNet. Finally, in the third stage, we resynthesize the background to be consistent with the lighting on the foreground object. We demonstrate and validate our lighting controlled diffusion model on a variety of text prompts and lighting conditions.

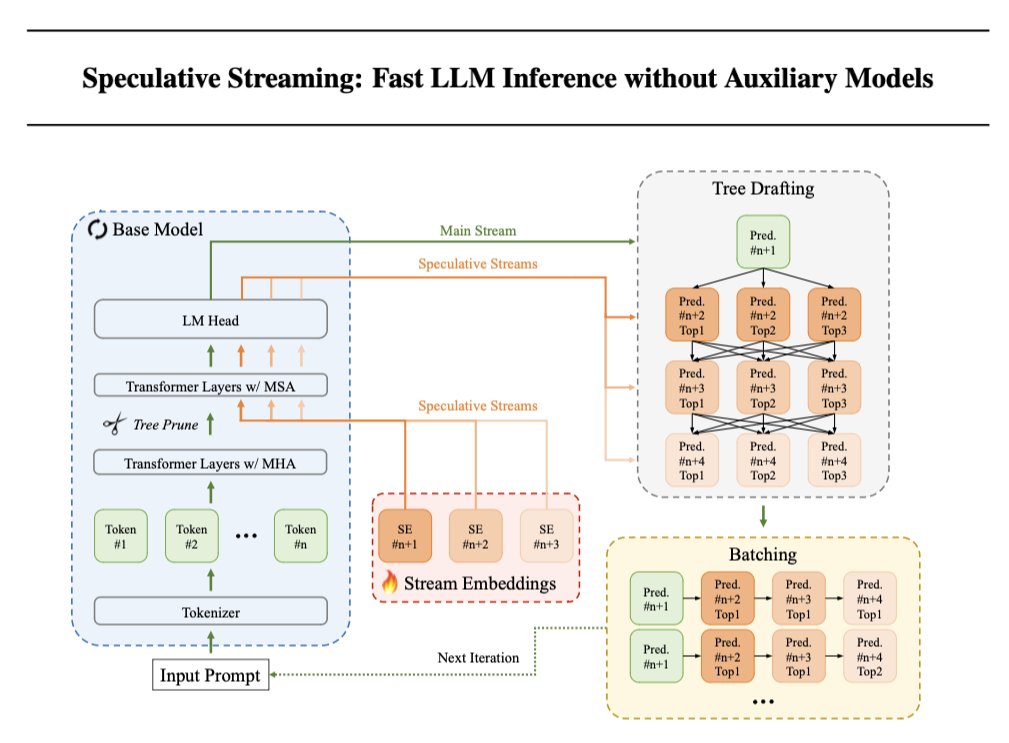
Speculative Decoding is a method to speed up the text generation of LLMs, but requires additional parameters or a separate smaller model. @Apple now proposes Speculative Streaming, which integrates speculative decoding into a single LLM to speed up inference without degrading quality. 🤯 Results ⏩ Speculative Streaming speeds up generation by 1.8-3.1x 🔍 Uses 10,000x fewer extra parameters compared to Medusa-style architectures. 🏋️♀️ Models need to be modified and fine-tuned 📦 Simplifies deployment by integrating speculation into a single LLM Implementation 1️⃣ Replace top Ns multi-head attention (MHA) layers of the base model with multi-stream attention (MSA) layers to enable n-gram prediction (MHA + SE). 2️⃣ LLM can now generate additional speculative tokens with negligible latency overhead. Use Parallel Tree structure with pruning to increase acceptance rates of the speculated tokens and reduce computational overhead by pruning tokens by transition probability between parent and immediate child tokens. 3️⃣ Train LoRA adapters using next token prediction and n-gram prediction to align speculation and verification. Apple didn’t open source any code, so who is going to implement this using Hugging Face and PEFT?
Meta presents GLoRe When, Where, and How to Improve LLM Reasoning via Global and Local Refinements State-of-the-art language models can exhibit impressive reasoning refinement capabilities on math, science or coding tasks. However, recent work demonstrates that even the best models struggle to identify when and where to refine without access to external feedback. Outcome-based Reward Models (ORMs), trained to predict correctness of the final answer indicating when to refine, offer one convenient solution for deciding when to refine. Process Based Reward Models (PRMs), trained to predict correctness of intermediate steps, can then be used to indicate where to refine. But they are expensive to train, requiring extensive human annotations. In this paper, we propose Stepwise ORMs (SORMs) which are trained, only on synthetic data, to approximate the expected future reward of the optimal policy or V^{star}. More specifically, SORMs are trained to predict the correctness of the final answer when sampling the current policy many times (rather than only once as in the case of ORMs). Our experiments show that SORMs can more accurately detect incorrect reasoning steps compared to ORMs, thus improving downstream accuracy when doing refinements. We then train global refinement models, which take only the question and a draft solution as input and predict a corrected solution, and local refinement models which also take as input a critique indicating the location of the first reasoning error. We generate training data for both models synthetically by reusing data used to train the SORM. We find combining global and local refinements, using the ORM as a reranker, significantly outperforms either one individually, as well as a best of three sample baseline.

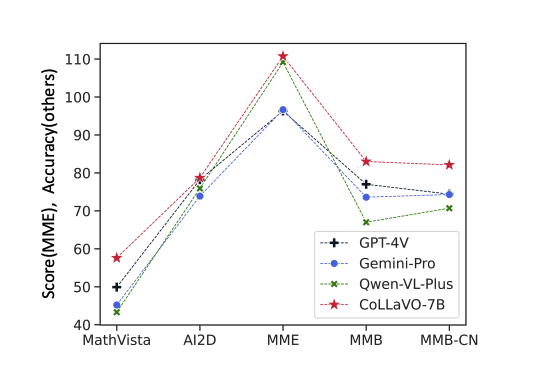
CoLLaVO Crayon Large Language and Vision mOdel The remarkable success of Large Language Models (LLMs) and instruction tuning drives the evolution of Vision Language Models (VLMs) towards a versatile general-purpose model. Yet, it remains unexplored whether current VLMs genuinely possess quality object-level image understanding capabilities determined from 'what objects are in the image?' or 'which object corresponds to a specified bounding box?'. Our findings reveal that the image understanding capabilities of current VLMs are strongly correlated with their zero-shot performance on Vision Language (VL) tasks. This suggests that prioritizing basic image understanding is crucial for VLMs to excel at VL tasks. To enhance object-level image understanding, we propose Crayon Large Language and Vision mOdel (CoLLaVO), which incorporates instruction tuning with crayon prompt as a new visual prompt tuning scheme based on panoptic color maps. Furthermore, we present a learning strategy of Dual QLoRA to preserve object-level image understanding without forgetting it during visual instruction tuning, thereby achieving a significant leap in zero-shot numerous VL benchmarks.
Vision-Flan Scaling Human-Labeled Tasks in Visual Instruction Tuning Despite vision-language models' (VLMs) remarkable capabilities as versatile visual assistants, two substantial challenges persist within the existing VLM frameworks: (1) lacking task diversity in pretraining and visual instruction tuning, and (2) annotation error and bias in GPT-4 synthesized instruction tuning data. Both challenges lead to issues such as poor generalizability, hallucination, and catastrophic forgetting. To address these challenges, we construct Vision-Flan, the most diverse publicly available visual instruction tuning dataset to date, comprising 187 diverse tasks and 1,664,261 instances sourced from academic datasets, and each task is accompanied by an expert-written instruction. In addition, we propose a two-stage instruction tuning framework, in which VLMs are firstly finetuned on Vision-Flan and further tuned on GPT-4 synthesized data. We find this two-stage tuning framework significantly outperforms the traditional single-stage visual instruction tuning framework and achieves the state-of-the-art performance across a wide range of multi-modal evaluation benchmarks. Finally, we conduct in-depth analyses to understand visual instruction tuning and our findings reveal that: (1) GPT-4 synthesized data does not substantially enhance VLMs' capabilities but rather modulates the model's responses to human-preferred formats; (2) A minimal quantity (e.g., 1,000) of GPT-4 synthesized data can effectively align VLM responses with human-preference; (3) Visual instruction tuning mainly helps large-language models (LLMs) to understand visual features.

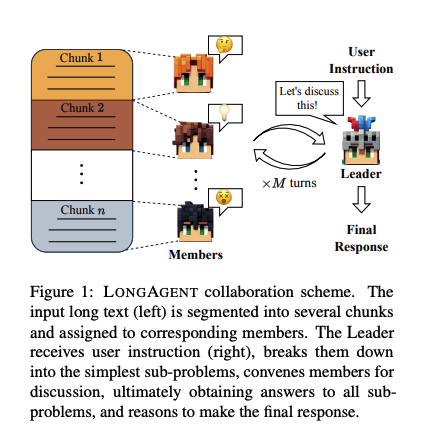
LongAgent Scaling Language Models to 128k Context through Multi-Agent Collaboration Large language models (LLMs) have demonstrated impressive performance in understanding language and executing complex reasoning tasks. However, LLMs with long context windows have been notorious for their expensive training costs and high inference latency. Even the most advanced models such as GPT-4 and Claude2 often make mistakes when processing inputs of over 100k tokens, a phenomenon also known as lost in the middle. In this paper, we propose LongAgent, a method based on multi-agent collaboration, which scales LLMs (e.g., LLaMA) to a context of 128K and demonstrates potential superiority in long-text processing compared to GPT-4. In LongAgent, a leader is responsible for understanding user intent and directing team members to acquire information from documents. Due to members' hallucinations, it is non-trivial for a leader to obtain accurate information from the responses of dozens to hundreds of members. To address this, we develop an inter-member communication mechanism to resolve response conflicts caused by hallucinations through information sharing. Our experimental results indicate that LongAgent offers a promising alternative for long-text processing. The agent team instantiated with LLaMA-7B achieves significant improvements in tasks such as 128k-long text retrieval, multi-hop question answering, compared to GPT-4.
Google presents LMPC: Learning to Learn Faster from Human Feedback with Language Model Predictive Control proj: https://t.co/Y833afcvym abs: https://t.co/VxiSr8nRcg https://t.co/w5au7wOOSw
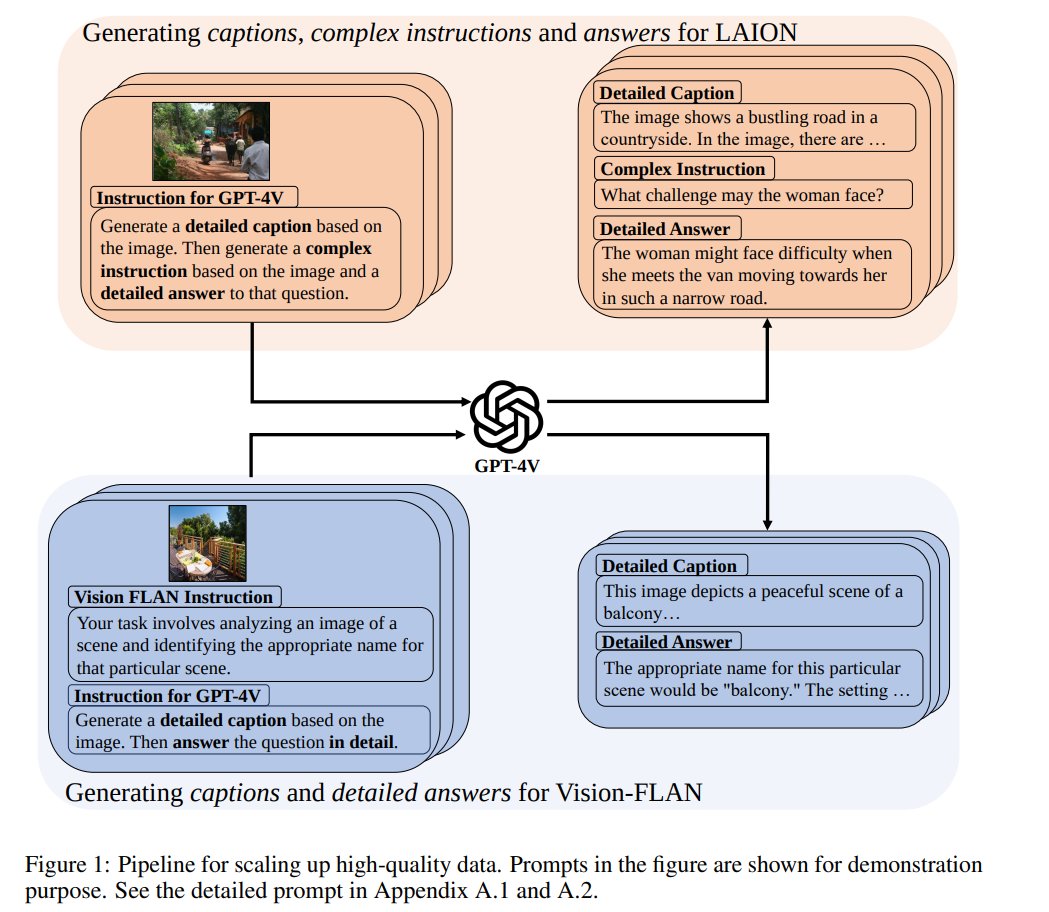
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model Collects and open-sources the largest (4 mil) GPT-4V dataset for VLM training, which consists of fine-grained captions, complex instructions and detailed answers https://t.co/cO4re0WYxx https://t.co/IbappxMBPM
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding Improves the decoding speed of Vicuna-33B by up to 2.37x and Llama2-70B offloading speed by up to 10.33x https://t.co/4Tws6hP3E2 https://t.co/W2HwiIsX8e

AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling Presents an any-to-any multimodal LM that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music proj: https://t.co/AKJFi2B3i1 abs: https://t.co/76TWcu3Bp0
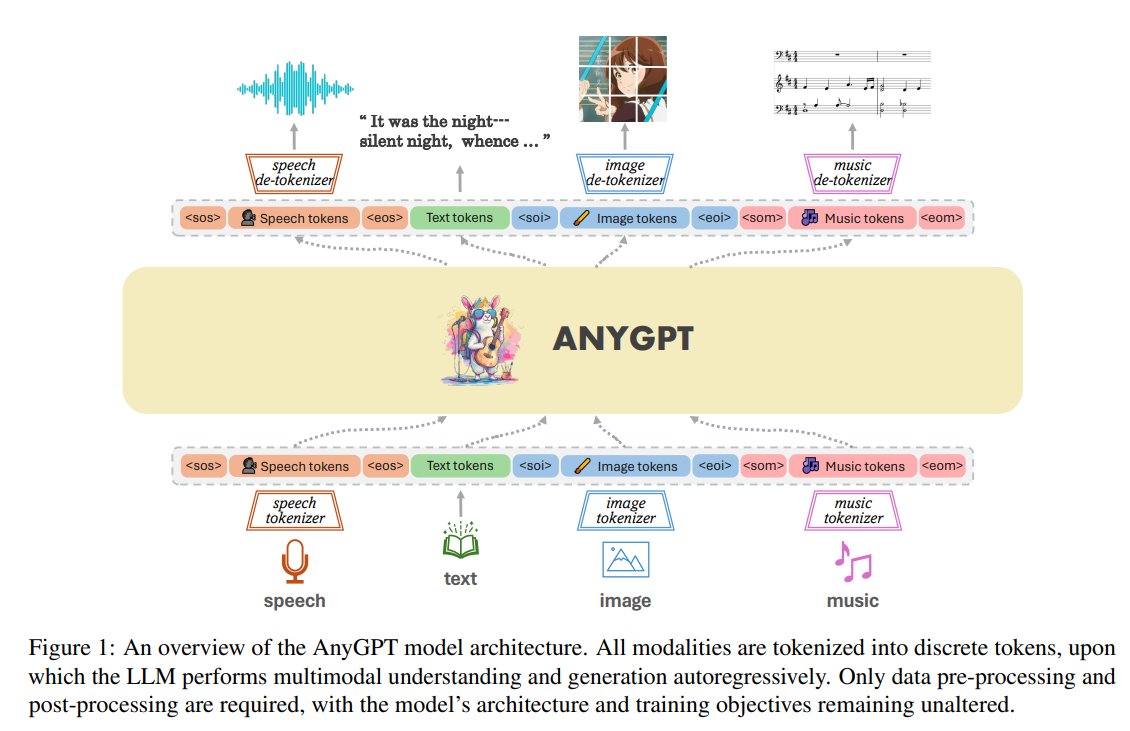
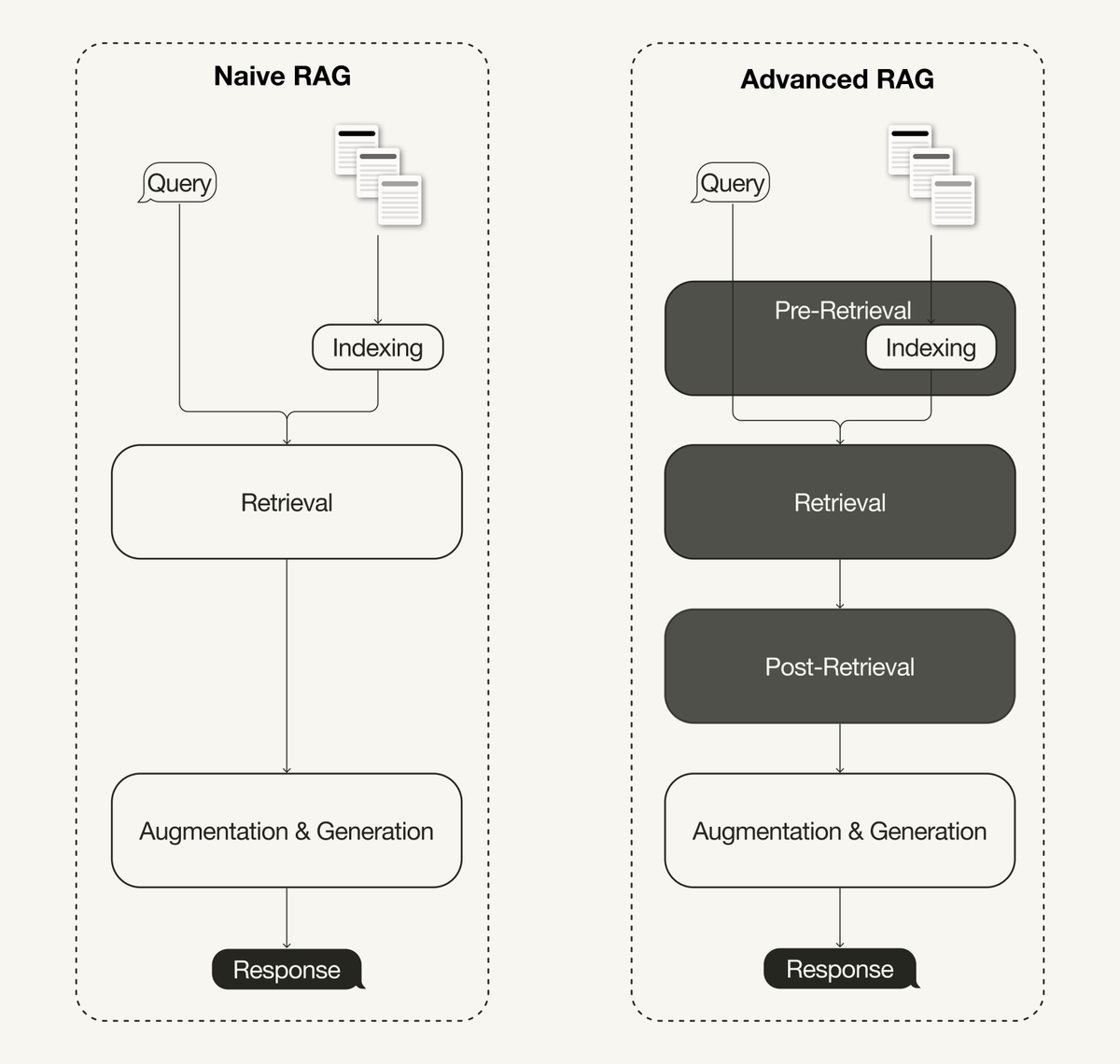
Advanced Retrieval-Augmented Generation (RAG) techniques address the limitations of naive RAG pipelines. A recent survey on RAG classifies advanced RAG techniques into pre-retrieval, retrieval, and post-retrieval optimizations. 🔗 Paper: https://t.co/dWkf0Uc587 My latest article gives an overview of advanced RAG techniques: 🦙 Pre-retrieval includes techniques like sliding windows, enhancing data granularity, adding metadata, or optimizing index structures, such as sentence window retrieval. 🦙 Retrieval includes optimizing the embedding models (e.g., fine-tuning) or advanced retrieval techniques like hybrid search 🦙 Post-retrieval includes reranking or prompt compression. We also implement a naive RAG pipeline using @llama_index and then enhance it to an advanced RAG pipeline using the following: • Sentence window retrieval (as a pre-retrieval optimization) • Hybrid search (as a retrieval optimization) • Re-ranking (as a post-retrieval optimization) 💻 Jupyter Notebooks: https://t.co/MFiz00RQHb Read more on @TDataScience: https://t.co/zgD02G1Rn7
Recurrent Memory Finds What LLMs Miss Explores the capability of transformer-based models in extremely long context processing. Finds that both GPT-4 and RAG performance heavily rely on the first 25% of the input, which means there is room for improved context processing mechanisms. The paper reports that recurrent memory augmentation of transformer models achieves superior performance on documents of up to 10 million tokens. The recurrent memory seems to enable effective multi-hop reasoning which is challenging for current LLMs and RAG systems. It also has the desirable effect of filtering out irrelevant information which is key in long context processing. With all the recent releases of long context models, this is an interesting and timely paper. I like the idea of combining both the recurrent memory and retrieval to these large models to make them more generalizable for complex tasks that require long context processing.

Simple-to-Advanced Reranking 🔥 If you’re building RAG, you should add reranking, and this blog post by Florian June is one of the most accessible posts we’ve seen on this topic on different levels of reranking. 💡 Learn how to use a BGE-based reranker 💡Use an LLM-powered reranker by using the RankGPT technique to rank long contexts. Directly integrates with @llama_index. Check it out 👇
The inference speed on the @GroqInc examples didn't look real. So I tested it myself and I don't even know what to say about this. Need to take a closer look at the technical papers. For now, all I can think about is the complex use cases this, and the support of millions of tokens context length, can enable. With breakthroughs in inference and long context understanding, we are officially entering a new era in LLMs. I am not surprised that we now have a dedicated inference engine for language processing. From the groq FAQ: "An LPU has greater compute capacity than a GPU and CPU in regards to LLMs. This reduces the amount of time per word calculated, allowing sequences of text to be generated much faster. Additionally, eliminating external memory bottlenecks enables the LPU Inference Engine to deliver orders of magnitude better performance on LLMs compared to GPUs." Try it yourself. What you see in the clip is playing at its original speed. This also made me realize how slow I type. 😅
LlamaIndex Webinar 💫: RAG Beyond Basic Chatbots RAG is one of the main use cases for LLMs, but many developers are using RAG to build basic Q&A chatbots over simple, static datasets. What are use cases for RAG beyond basic chatbots? We're excited to feature four community projects that feature creative use cases of RAG for advanced knowledge synthesis and reasoning in a variety of practical use cases: 1️⃣ ADU Planner: https://t.co/EfMGu2OTOG 2️⃣ Counselor Copilot: https://t.co/mchEnjOCpt 3️⃣ https://t.co/uX9oWqAm9g (@raw_works): https://t.co/wPrJKG3McQ 4️⃣ https://t.co/HTq23JEW0Z: https://t.co/FAxYcjzevD These were winners of the recent LlamaIndex hackathon we organized in conjunction with Futureproof Labs and @DataStax. This Thursday, 9am PT. Check it out! https://t.co/oLeIsqYIz1
Funcchain's structured output + fastui with pydantic is quite powerful to just generate apps from instructions https://t.co/L7GLGl254p
This man is now worth around $140 billion. https://t.co/WTOOPAetEW
Breaking! Mistral Next on LMSYS Chat and seems to outperform Gemini Ultra. Vibe check: https://t.co/LCUwDi5u5k

BioMistral is a new 7B foundation model for medical domains, based on Mistral and further trained PubMed Central. - top open-source medical Large Language Model (LLM) in its weight class - Apache License - includes base models, fine tunes, and quantized versions. https://t.co/RoXyFBRMDj
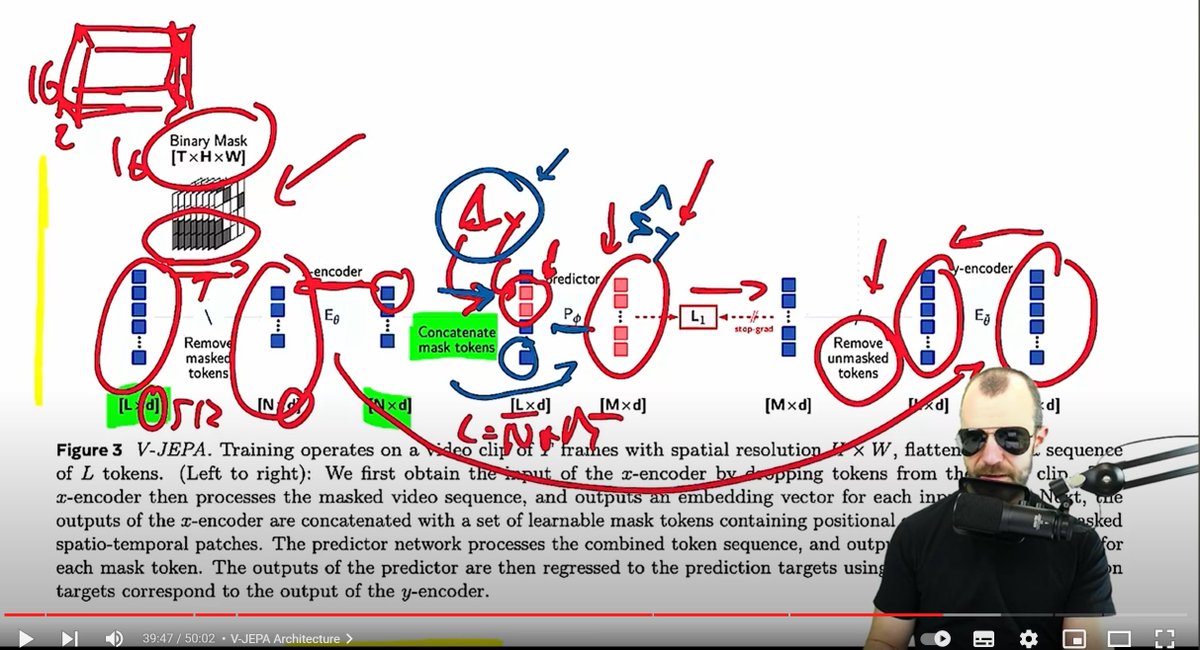
@ylecun Best to ignore them and keep the great research coming! Summary of the @Meta research: “Revisiting Feature Prediction for Learning Visual Representations from Video” (Full Paper: https://t.co/cXO5VT7JIm) https://t.co/Mo0ATfWe37

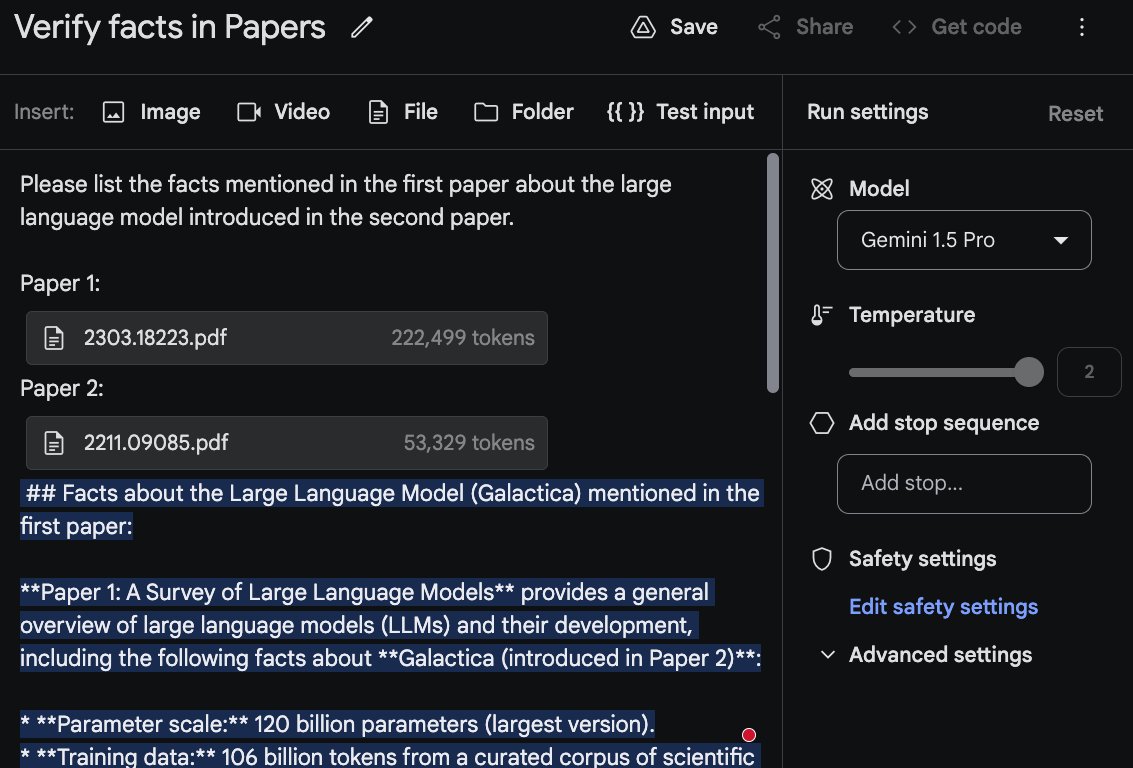
Gemini 1.5 Pro and its 1M tokens context length show huge potential! I have been experimenting with Gemini 1.5 Pro (inside Google AI Studio) and find that its reasoning ability over long-form content is quite good. I am particularly interested in LLMs that can retrieve and reason over long contexts across different modalities. This is what unlocks all kinds of complex use cases. For now, my experiments are around scientific papers and the kind of complex analysis or questions the model can accurately answer. In the screenshot, we prompt the model with two papers as input. The model needs to analyze both papers before it can return an answer. What I found interesting in the response it gave me is that it even analyzed tables before it sent back a response. It's exciting to see this type of analysis on the fly without using a RAG system. Beyond this, we can ask for more concrete explanations of findings and experiments by giving it more context. You can also prompt the model to extend a survey paper based on recent papers or even generate your own based on a desired format. And a whole lot more. A full analysis and more examples of Gemini 1.5 Pro will be published in the promoting guide soon. Stay tuned!
@ylecun Best to ignore them and keep the great research coming! Summary of the @Meta research: “Revisiting Feature Prediction for Learning Visual Representations from Video” (Full Paper: https://t.co/cXO5VT7JIm) https://t.co/Mo0ATfWe37
🚀 Mistral AI's latest model - Mixtral, is a game-changer for #LLMs & #GenAI. ✍ In this blog, I present a detailed analysis of the Mixtral model architecture and the specialized attention mechanisms that endow it with superior capabilities vs. LLaMA-2: https://t.co/6tAFthS3zz https://t.co/X0CPFpHULu
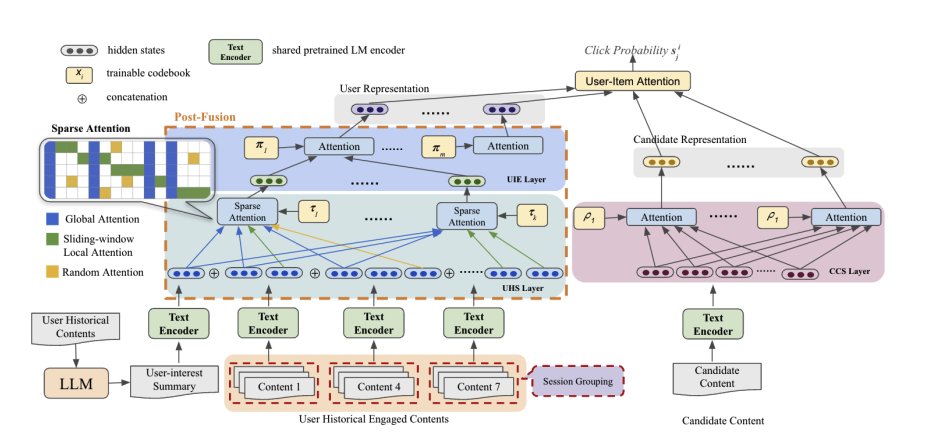
Meta presents SPAR Personalized Content-Based Recommendation via Long Engagement Attention Leveraging users' long engagement histories is essential for personalized content recommendations. The success of pretrained language models (PLMs) in NLP has led to their use in encoding user histories and candidate items, framing content recommendations as textual semantic matching tasks. However, existing works still struggle with processing very long user historical text and insufficient user-item interaction. In this paper, we introduce a content-based recommendation framework, SPAR, which effectively tackles the challenges of holistic user interest extraction from the long user engagement history. It achieves so by leveraging PLM, poly-attention layers and attention sparsity mechanisms to encode user's history in a session-based manner. The user and item side features are sufficiently fused for engagement prediction while maintaining standalone representations for both sides, which is efficient for practical model deployment. Moreover, we enhance user profiling by exploiting large language model (LLM) to extract global interests from user engagement history. Extensive experiments on two benchmark datasets demonstrate that our framework outperforms existing state-of-the-art (SoTA) methods.
Google presents PaLM2-VAdapter Progressively Aligned Language Model Makes a Strong Vision-language Adapter paper demonstrates that a progressively aligned language model can effectively bridge frozen vision encoders and large language models (LLMs). While the fundamental architecture and pre-training methods of vision encoders and LLMs have been extensively studied, the architecture and training strategy of vision-language adapters vary significantly across recent works. Our research undertakes a thorough exploration of the state-of-the-art perceiver resampler architecture and builds a strong baseline. However, we observe that the vision-language alignment with perceiver resampler exhibits slow convergence and limited scalability with a lack of direct supervision. To address this issue, we propose PaLM2-VAdapter, employing a progressively aligned language model as the vision-language adapter. Compared to the strong baseline with perceiver resampler, our method empirically shows faster convergence, higher performance, and stronger scalability. Extensive experiments across various Visual Question Answering (VQA) and captioning tasks on both images and videos demonstrate that our model exhibits state-of-the-art visual understanding and multi-modal reasoning capabilities. Notably, our method achieves these advancements with 30~70% fewer parameters than the state-of-the-art large vision-language models, marking a significant efficiency improvement.
LLM Comparator Visual Analytics for Side-by-Side Evaluation of Large Language Models Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
