@_philschmid
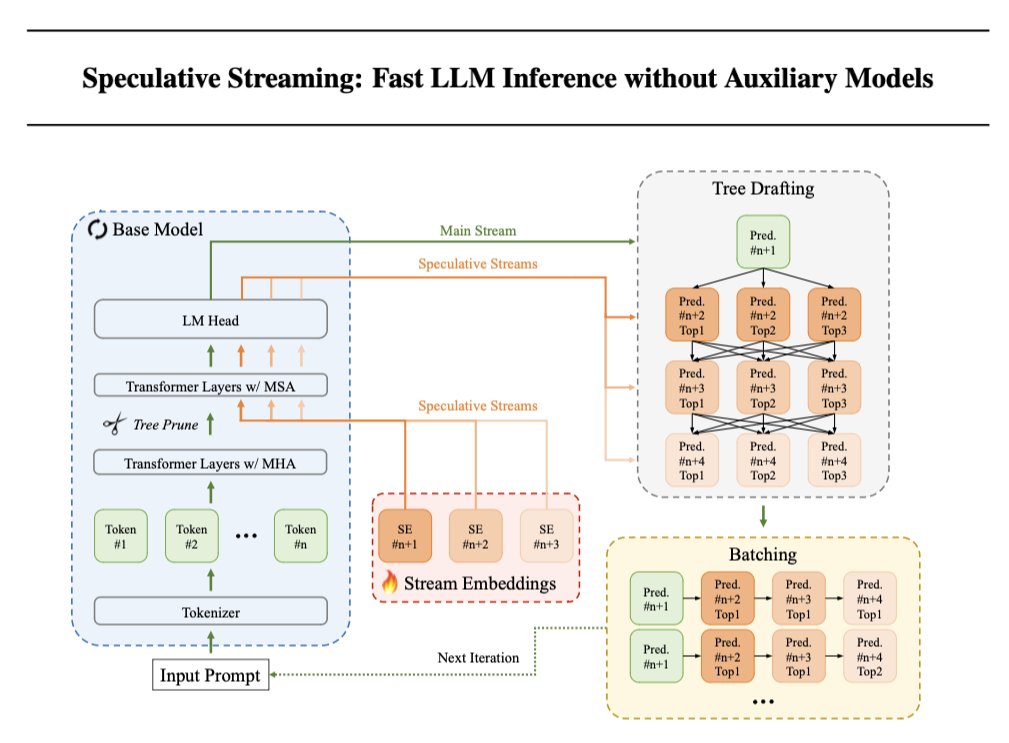
Speculative Decoding is a method to speed up the text generation of LLMs, but requires additional parameters or a separate smaller model. @Apple now proposes Speculative Streaming, which integrates speculative decoding into a single LLM to speed up inference without degrading quality. 🤯 Results ⏩ Speculative Streaming speeds up generation by 1.8-3.1x 🔍 Uses 10,000x fewer extra parameters compared to Medusa-style architectures. 🏋️♀️ Models need to be modified and fine-tuned 📦 Simplifies deployment by integrating speculation into a single LLM Implementation 1️⃣ Replace top Ns multi-head attention (MHA) layers of the base model with multi-stream attention (MSA) layers to enable n-gram prediction (MHA + SE). 2️⃣ LLM can now generate additional speculative tokens with negligible latency overhead. Use Parallel Tree structure with pruning to increase acceptance rates of the speculated tokens and reduce computational overhead by pruning tokens by transition probability between parent and immediate child tokens. 3️⃣ Train LoRA adapters using next token prediction and n-gram prediction to align speculation and verification. Apple didn’t open source any code, so who is going to implement this using Hugging Face and PEFT?