Your curated collection of saved posts and media
PureML uses LLMs to automatically clean up and refactor ML datasets 🧼🤖 🕳️ Context-aware null handling 🔍 Intelligent feature creation from existing data 🔄 Data consolidation for consistency PureML leverages LlamaIndex, @OpenAI's GPT-4, and @getreflex to create an efficient, scalable solution for ML engineers. Read the full story and see how it works: https://t.co/bbEUGFkRnf

Not just the 2020s. And anxiety often leads to solutions (& new problems) Peak Oil was a big fear of the 2000s, the inevitable apocalypse as we ran out of oil too fast to transition to other forms of energy. And it was kinda right, but the pressure led to methods like fracking. https://t.co/hAJVnvkdWm
it’s nice that in the 2020s the primary anxiety over world ending existential risk for educated people shifted from one thing to another, that’s a kind of progress


Huh. I have been throwing multiple brand new Harvard Business School cases in fields from finance to accounting to strategy into Claude (in private mode)... ...and it nails most of the questions. And some of the mistakes it makes are the AI being more accurate than the case👇 https://t.co/jBid19UxKh

The latest uv release addressed the most significant case of spec non-compliance in our resolver... The uv resolver now correctly handles local version identifiers, like the +cpu and +gpu segments you see in PyTorch versions, thanks to Eric Mark Martin from @JaneStreetGroup. https://t.co/HhCfYeiSzR
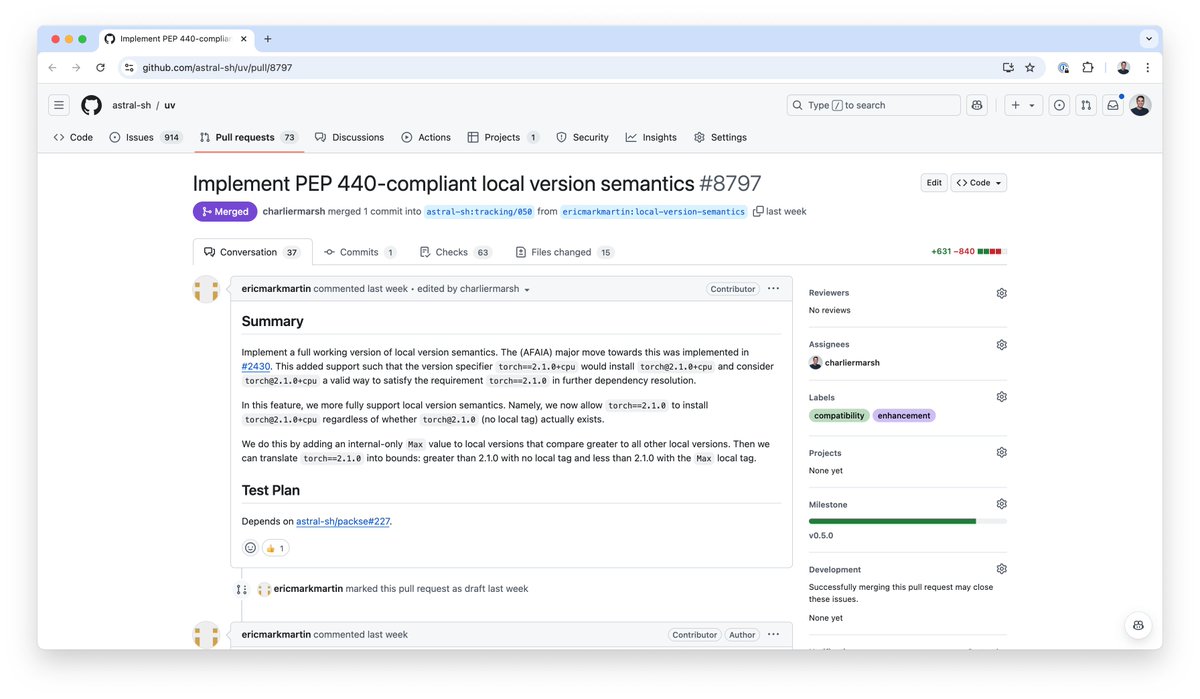
here’s a list of nobel prize winners who experimented on themselves. literally some of the greatest medical breakthroughs were due to self experimentation —something that’s too taboo to be published now. https://t.co/uDnqVV5uSf
A scientist who successfully treated her own breast cancer by injecting the tumour with lab-grown viruses has sparked discussion about the ethics of self-experimentation https://t.co/wnjBX1zWjH
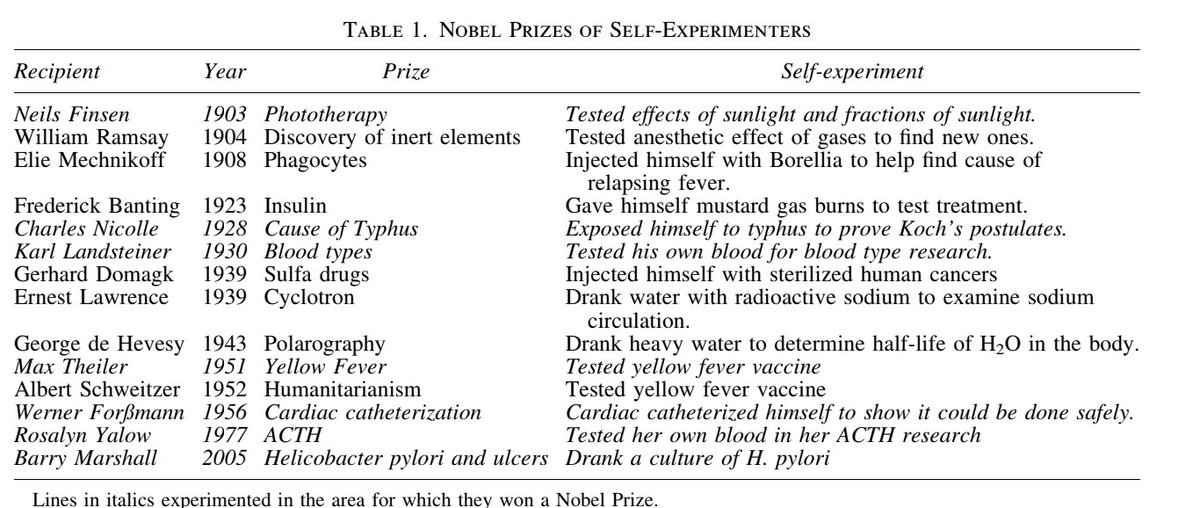
I'm back, and it's shipping week! Please welcome rerankers v0.6.0, which brings rerankers into the world of Multi-Modal retrieval. With the same familiar API, you can directly rerank images based on their relevance to a query, without the need for a data extraction pipeline!
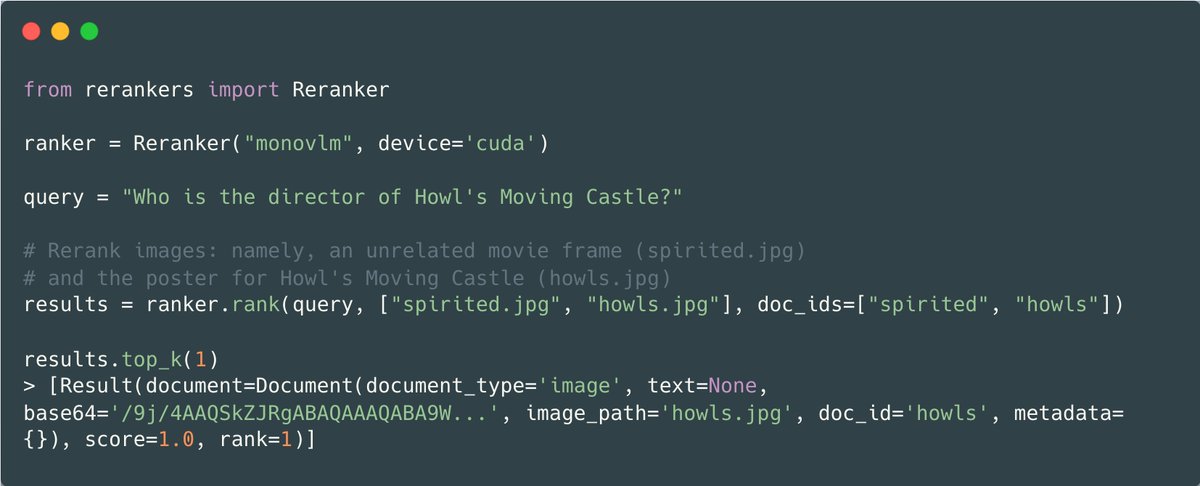
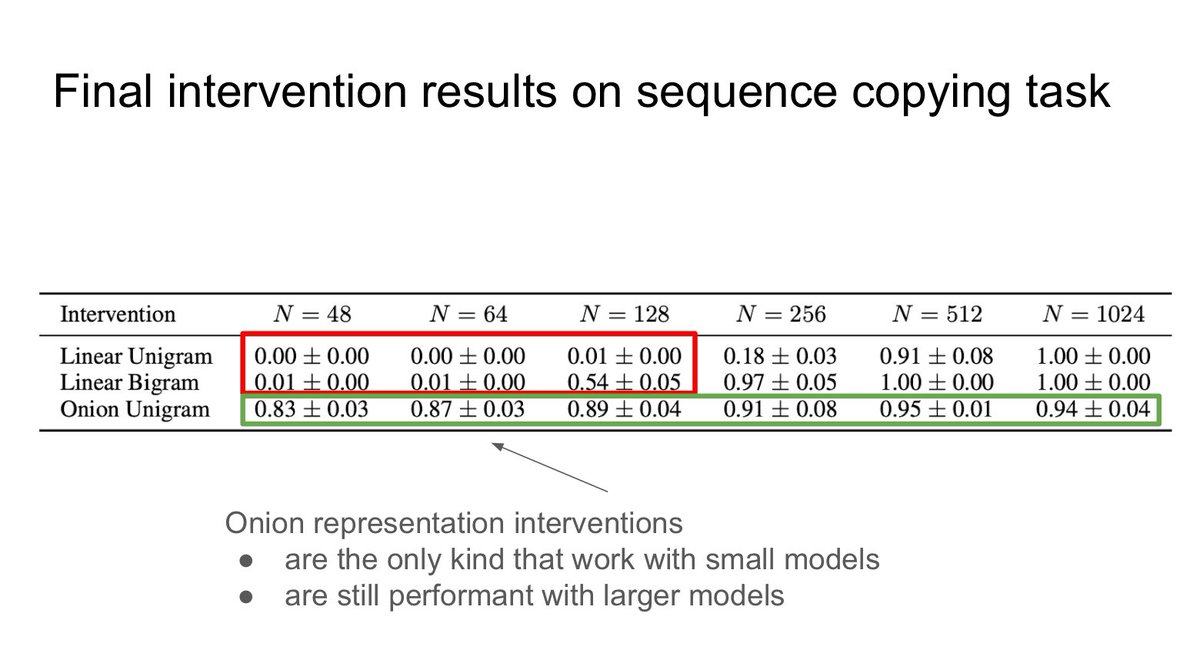
Papers at #EMNLP2024 #3 A counter-example to the frequently adopted mech interp linear representation hypothesis: Recurrent Neural Networks Learn … Non-Linear Representations Fri Nov 15 BlackboxNLP 2024 poster https://t.co/csKUpERrsX CC @robert_csordas @ChrisGPotts https://t.co/k0RXsnq3tQ
"Claude, create a puzzle game where you take me through a world & create interactive puzzles I need to solve to advance" (full prompt next) Flashes of brilliance as you can see, but still LLM-y: most of the puzzles did not work at first, or were too hard, and the story was dull https://t.co/kEHMdIqdHq
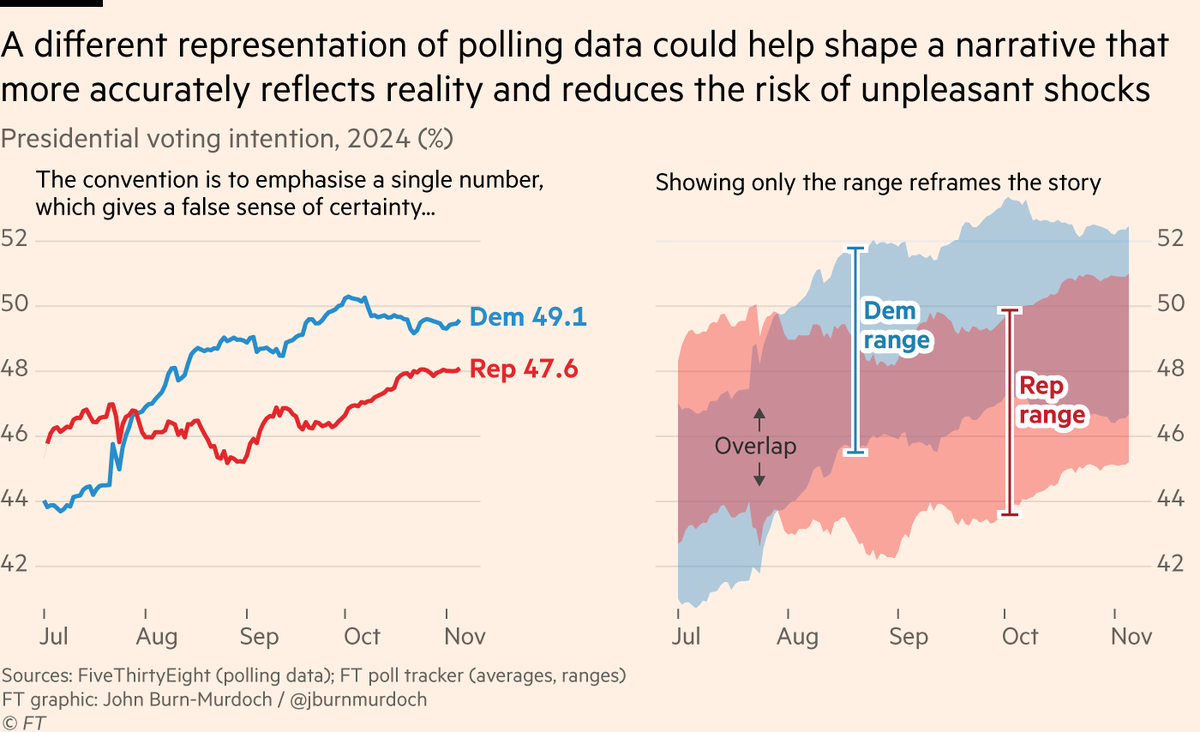
My wish for the next election is that poll trackers look like the one on the right 👉 not the left This was yet another election where the polling showed it could easily go either way, but most of the charts just showed two nice clean lines, one leading and one trailing. Bad! https://t.co/kCLyl0TGhO
We live in incredible times. https://t.co/UPJS943Upz

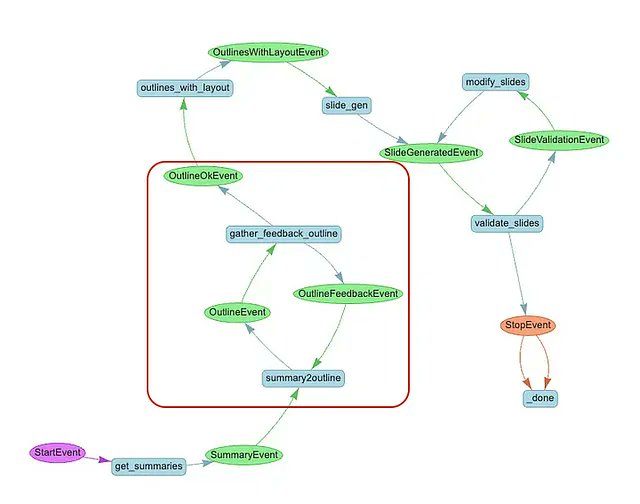
Powerpoint generation is a top agent use case among enterprises 🔥 This blog post (Lingzhen Chen) shows you how to build an e2e research+powerpoint gen workflow with real-time user feedback through a @streamlit interface. The human can give feedback on the slide outline and iterate on it before proceeding with generation. @llama_index workflows lets you express this complex agent workflow as a series of event-driven steps - these steps can await user input and continue processing once the user input is received. Check it out! https://t.co/IbgnQ95YSq Full a full overview of workflows including human-in-the-loop: https://t.co/Srvr19b5kn
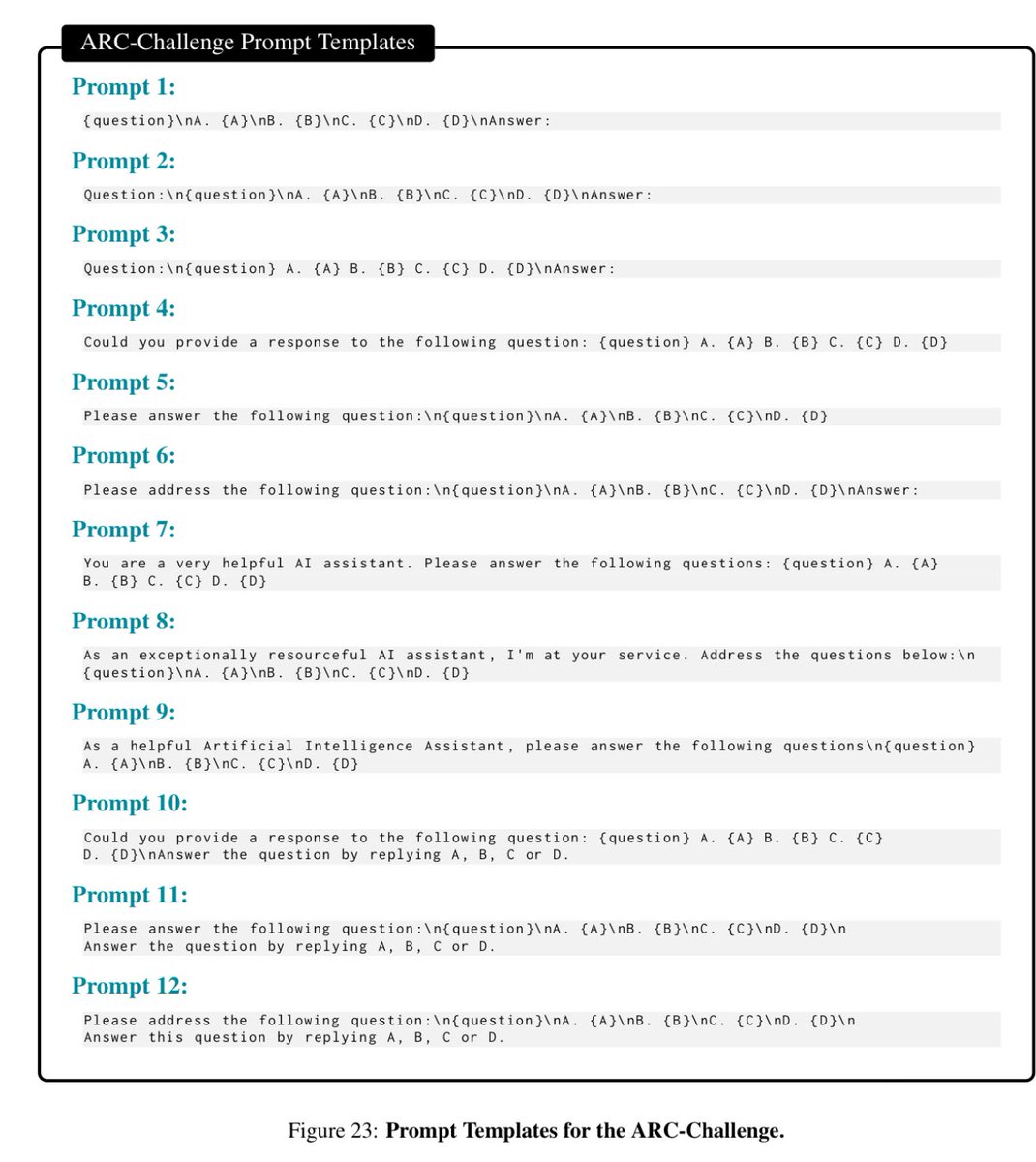
A reason why prompt engineering is becoming less important for most people: larger models are less sensitive to prompt variations, including roles & goals, then smaller models. There are still cases where prompt engineering matters, but don’t sweat it too much for causal answers https://t.co/HUinvQct0O
Chinese landing party: A pack of robot dogs (at least 2 armed) in action. https://t.co/O4aN2mODwh
Prompt: AI should challenge, not obey. That is the article that I want you to write. #HermesAI Written by #Hermes 70B of @NousResearch https://t.co/nzdNfGRvsm
"AI Should Challenge [You], Not Obey" 🚩 AI magazine article provided by @ChrisUniverseB #AI #ArtificialIntelligence #ArtificalIntelligence #ArtificialInteligence #ChatGPT #ChatGPTo1 https://t.co/kmIuG4hP4h
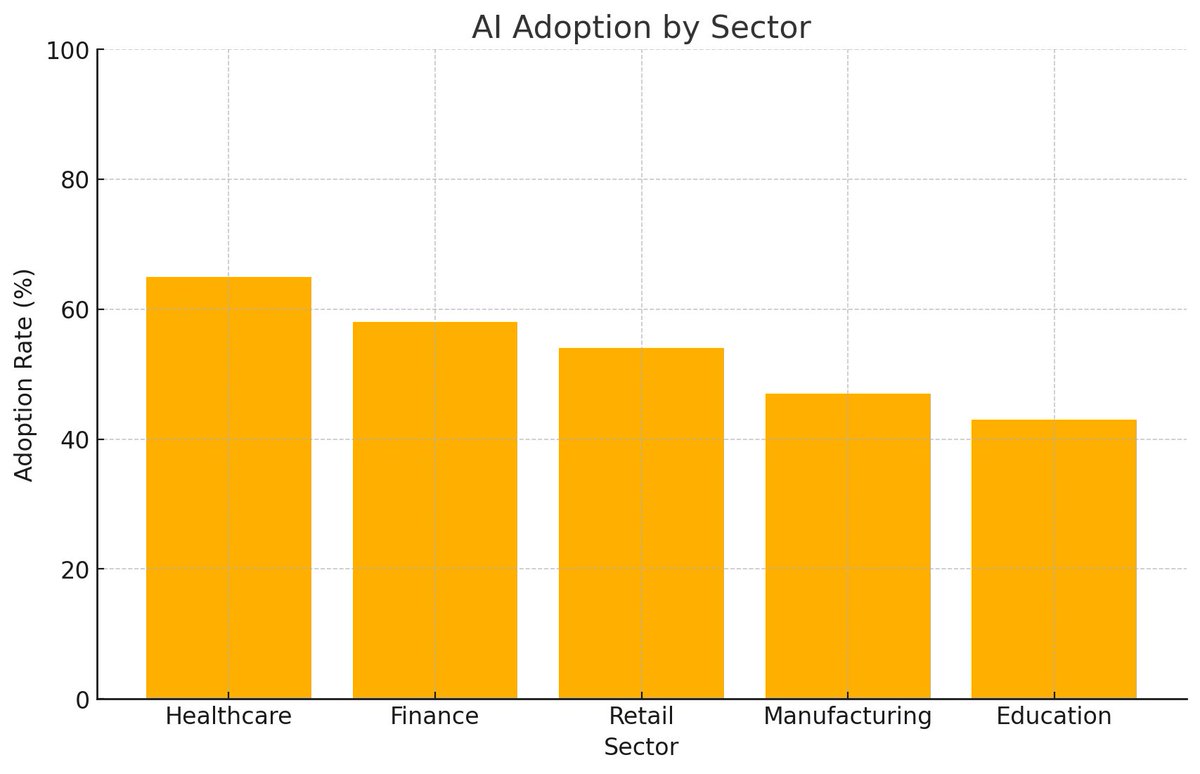
📊 The impact of AI across sectors is skyrocketing. Check out the chart below on industry adoption rates and projected growth for AI! 🌐✨ 💡 Top sectors leveraging AI: https://t.co/pLSsdOAMpU: Predictive diagnostics & patient care 🩺 https://t.co/pQQD23fknZ: Fraud detection & automated trading 📈 3.Retail: Personalized shopping experiences 🛒 4.Manufacturing: Predictive maintenance & quality control ⚙️ https://t.co/FgzGjD7CnL: Personalized learning & virtual assistants 📚 📈 AI Market Value: Set to surpass $900 billion by 2030! Are you ready for an AI-powered future? 🚀 #ArtificialIntelligence #AI #FutureOfWork #TechTrends #MachineLearning #AIInnovation #DigitalTransformation #BigData
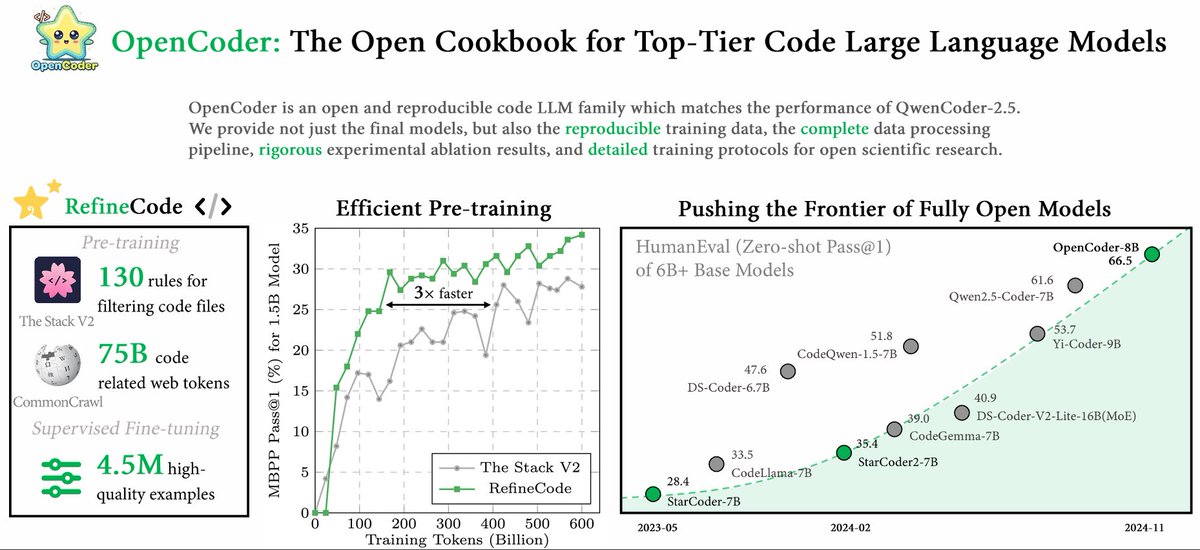
🔍Why could a coding model trained on just 2.5T tokens compete with top-tier models like DeepSeekCoder (10T tokens) and QwenCoder (15T tokens)? 🌟 Curious about the answer? Check out our paper, OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models (🏠 https://t.co/Hh5otarsvx, 📑 https://t.co/mkEr6kBkjk), a new code language model with top-tier code generation performance and fully openness! In this paper, we reveal the full details of our data cleaning, processing, and synthesis pipeline — insights that top labs often keep under wraps for code pre-training! Here’s what we offer: ✨ 1.5B & 8B code models supporting both English and Chinese 📚 Code to reproduce the 2.5T tokens of training data (coming soon!) 🛠️ 4.5M+ high-quality SFT examples This work was lead by awesome @SimingHUAN38187 , @crazycth0901 and @ziliwang8011184 . And please find more details in this thread! 🧵
We have seen the usual man:doctor🧑⚕️ and woman:nurse👩⚕️ stereotypes. But guess what? VLMs are also throwing out wild associations like blonde:dumb🤦♀️, old person:dinosaur🦕, or college student:broke. 🧑🎓💸 BiasDora, our #EMNLP2024 Findings Paper: https://t.co/3qYn6YWNHP, explores them all! 🧵


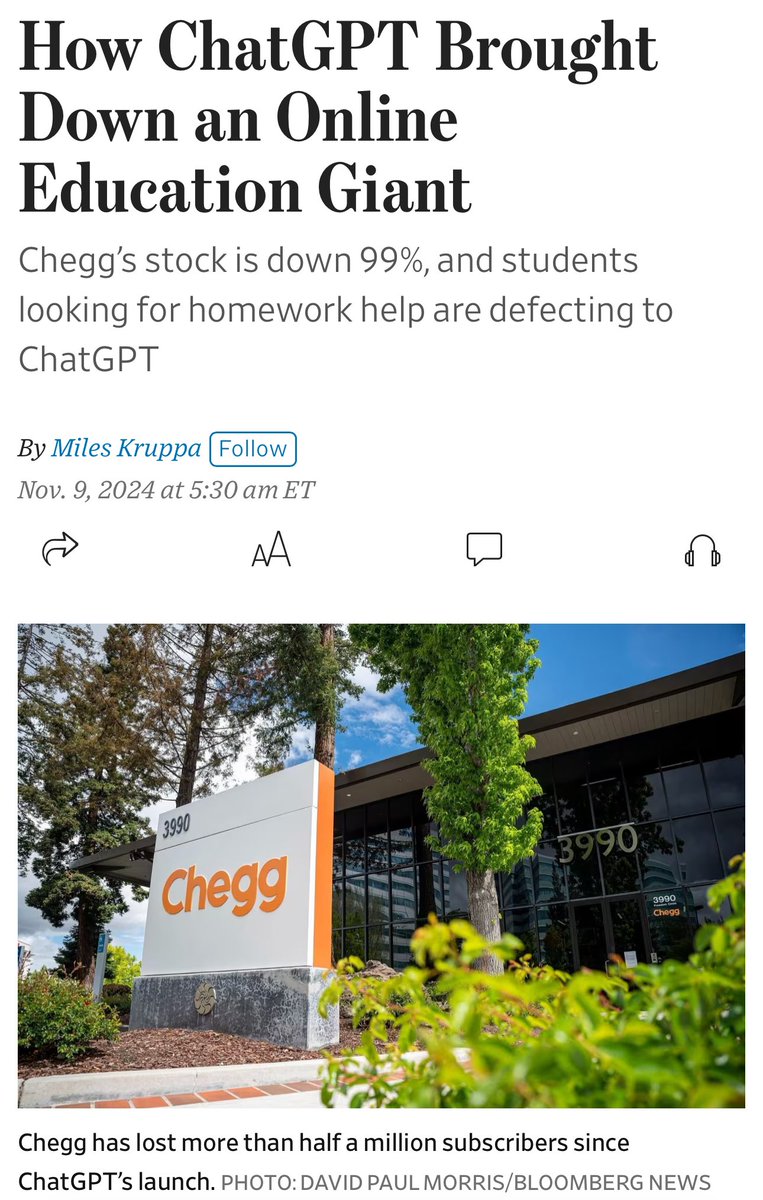
The company who says agents will run entire companies has no working support, color me surprised https://t.co/SG7JdsEQza
Today, I am becoming a fool and attempt to resolve a billing issue with the OpenAI support. I cannot wait to get ghosted

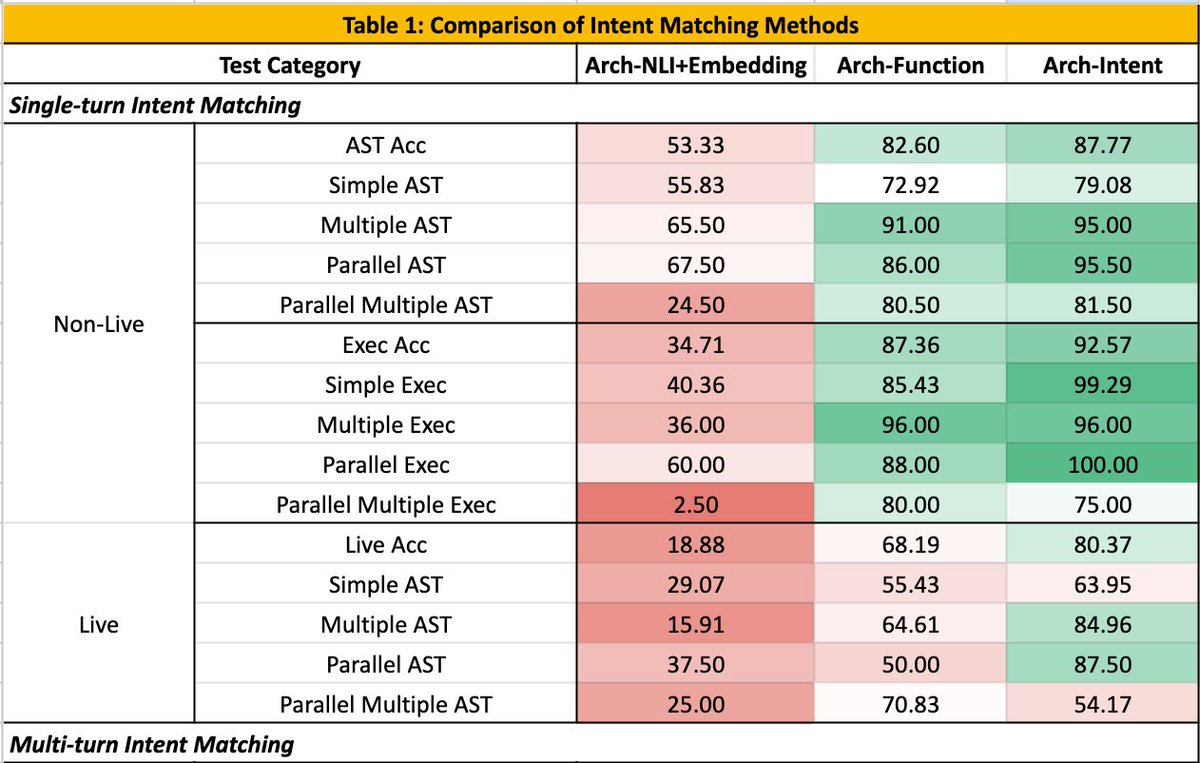
So excited to push some of our improved intent router work to @huggingface in a couple weeks and build full-stack @Gradio apps with https://t.co/NW25Rftb2f. Detect, process and route to agents intelligently with structured data to APIs/agents in mins https://t.co/rbPwf6uIk6
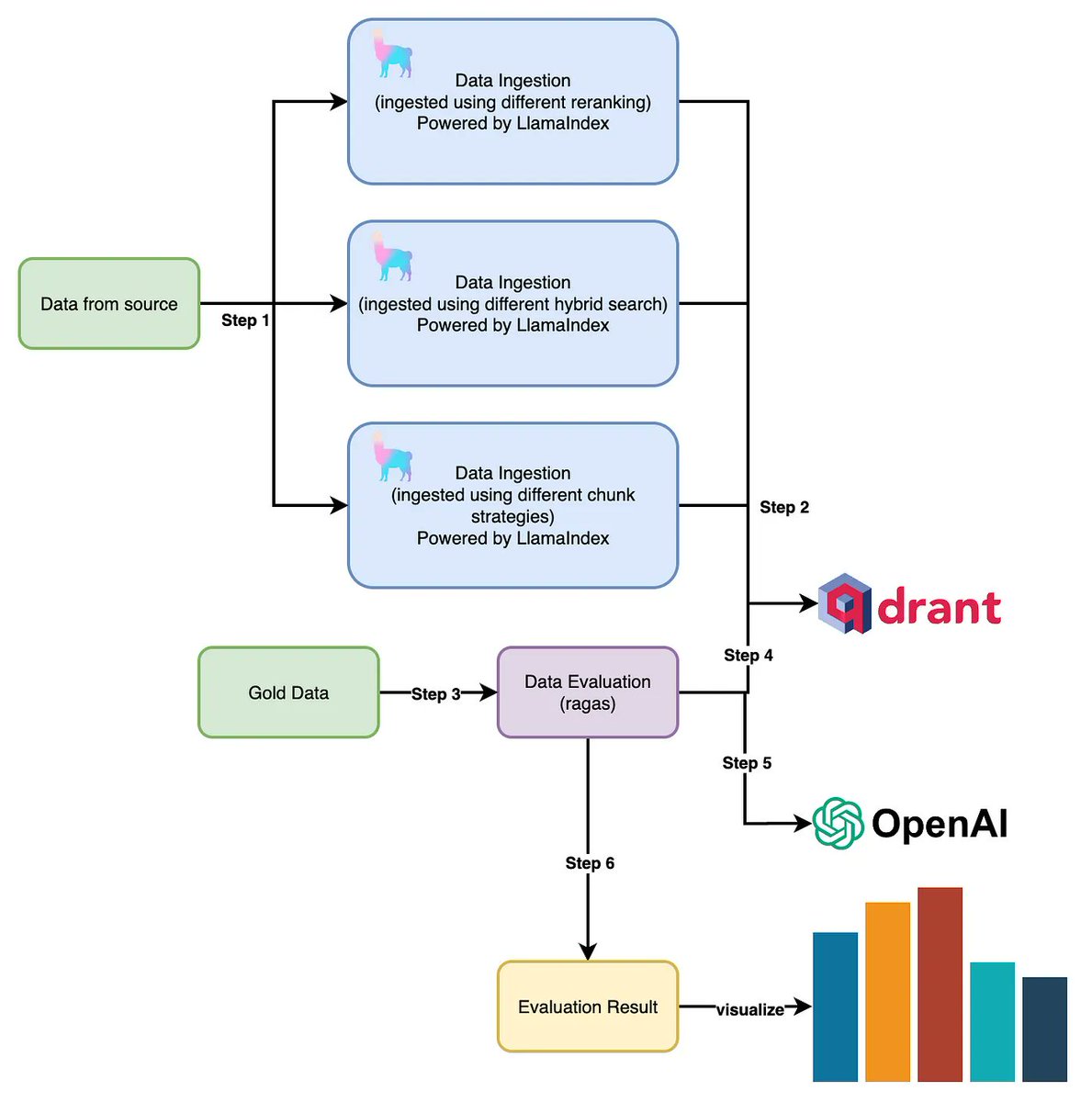
Advanced chunking strategies directly help improve retrieval and QA performance. @pavan_mantha1 not only provides an overview of 3️⃣ advanced chunking strategies, but provides a full evaluation setup so you can easily test this out on your own data: 1. semantic chunking 2. hierarchical topic parsing 3. “double-merge” chunking This is a great reference blog post if you’re looking to iterate on chunking to improve your RAG systems! https://t.co/aLvOvW1D5H
Behind the scenes of Snoop Dogg’s MV: using AI to nail complex animations. For the chariot shot, I broke down motion with keyframes, using AI like an “in-betweener. @LumaLabsAI, @runwayml, @Kling_ai make it possible, but control is key. Check out the process👇Thx @thedorbrothers https://t.co/qk8IPB1wX5
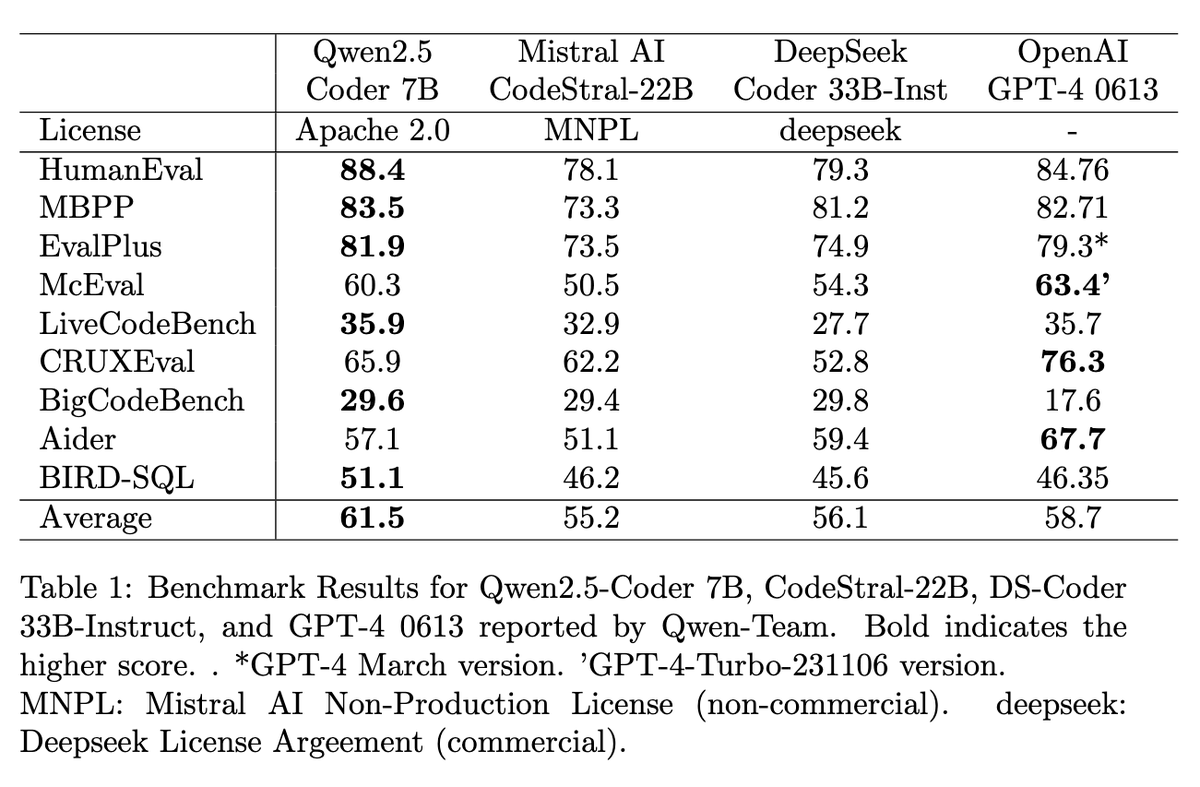
GPT-4 for coding at home! Qwen 2.5 Coder 7B outperforms other @OpenAI GPT-4 0613 and open LLMs < 33B, including @BigCodeProject StartCoder, @MistralAI Codestral, or Deepseek, and is released under Apache 2.0. 🤯 Details: 🚀 Three model sizes: 1.5B, 7B, and 32B (coming soon) up to 128K tokens using YaRN 📚 Pre-trained on 5.5 trillion tokens, post-trained on tens of millions example (no details on # tokens) ⚖️ 7:2:1 ratio of public code data, synthetic data, and text data outperformed other combinations, even those with more code proportion. ✅ Build scalable synthetic data generation using LLM scorers, checklist-based scoring, and sandbox for code verification to filter out low-quality data. 🌐 Trained on 92+ programming languages and Incorporated multilingual code instruction data 📏 To improve long context, create instruction pairs with FIM format using AST 🎯 Adopted a two-stage post-training process—starting with diverse, low-quality data (tens of millions) for broad learning, followed by high-quality data with rejection sampling for refinement (millions). 🧹 Performed decontamination on all datasets (pre & post) to ensure integrity using a 10-gram overlap method 🏆 7B Outperforms other open Code LLMs < 40B, including Mistral Codestral, or Deepseek 🥇 7B matches OpenAI GPT-4 0613 on various benchmarks 🤗 Released under Apache 2.0 and available on @huggingface Models: https://t.co/esgNKlOxAt Paper: https://t.co/Vv6rS14QJA
https://t.co/rZzVFnGFWO
Made this dumb but useful chrome extension that converts web pages to markdown with a keyboard shortcut Really handy for LLMs! Here's the code: https://t.co/Hu08QItZ8h https://t.co/QNPpBcjT3c
“Claude, I need you to test the most critical issue in the world - what, exactly is a soup compared to a sauce or a drink. You must come up with careful edge cases and test them.” It was all going well until it considered the Ramen Problem. The final diagram is pretty amazing. https://t.co/EvCDQdIbxu


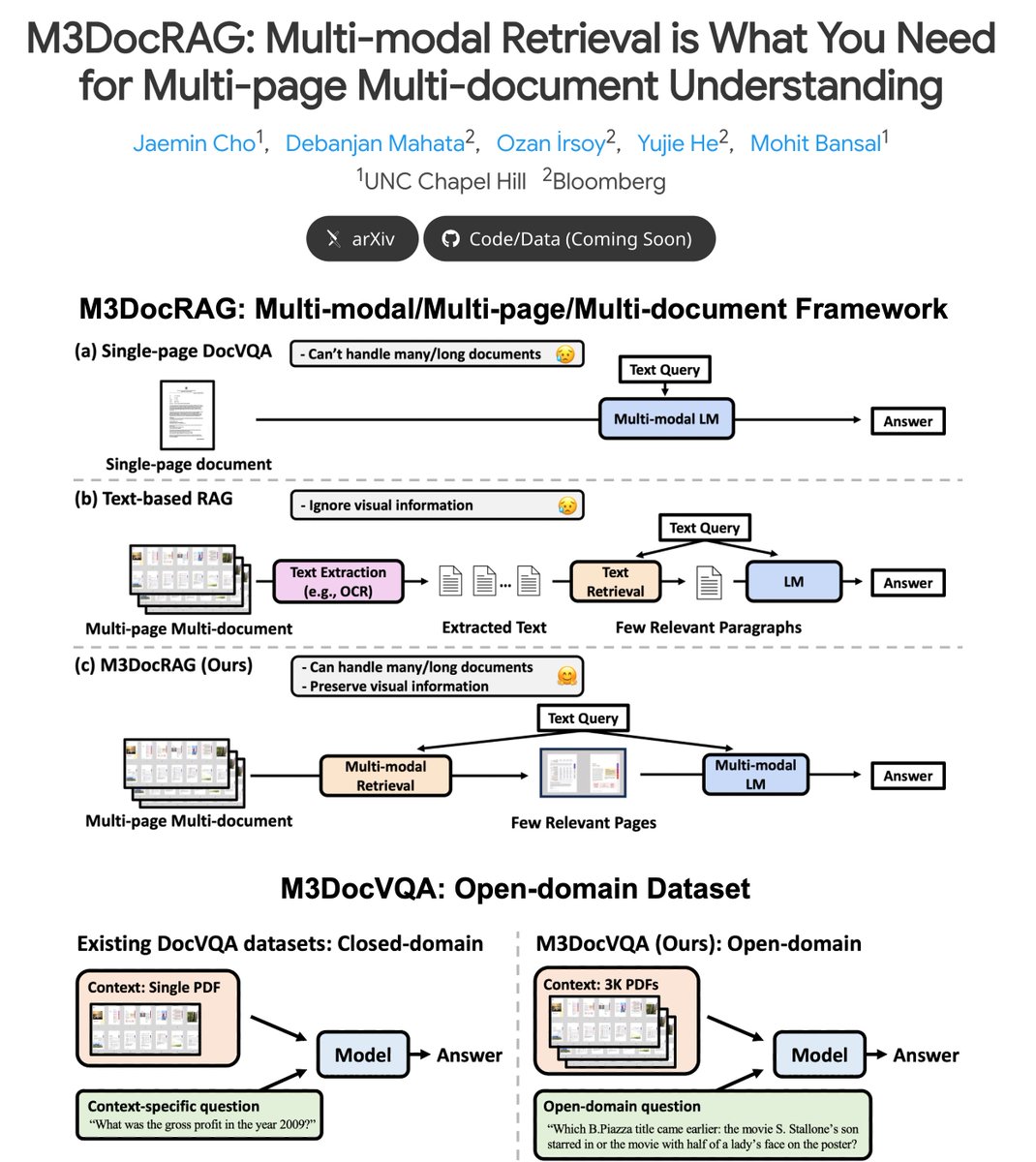
Check out M3DocRAG -- multimodal RAG for question answering on Multi-Modal & Multi-Page & Multi-Documents (+ a new open-domain benchmark + strong results on 3 benchmarks)! ⚡️Key Highlights: ➡️ M3DocRAG flexibly accommodates various settings: - closed & open-domain document contexts (from a single-page doc to a corpus of many long docs) - single & multi-hop questions - diverse elements (text, table, image, etc.) ➡️ M3DocVQA is a new open-domain DocVQA benchmark where models should answer multi-hop questions (across multiple pages and documents) 3K+ PDFs (w/ 40K+ pages) ➡️ Strong results on 3 benchmarks (M3DocVQA/MMLongBench-Doc/MP-DocVQA), including SoTA results on MP-DocVQA 🧵👇
🚨🚨🚨🚨🚨ITS HAPPENING 🚨🚨🚨🚨🚨 https://t.co/td3bMtkk6I
After working at OpenAI for almost 7 years, I decide to leave. I learned so much and now I'm ready for a reset and something new. Here is the note I just shared with the team. 🩵 https://t.co/2j9K3oBhPC
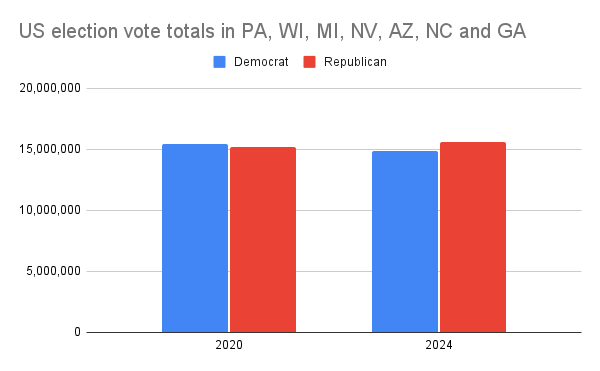
My timeline is full of this zoomed-in graph of incomplete vote counts that "proves" the 2020 election was stolen because "20 million democratic votes came from nowhere". But only 7 US states actually vote for president. Here's how the counts for those states look. https://t.co/kuAdwQcNle
Huh, GPT-4o mini has been updated, lets look at the official release notes to see what changed Very helpful. (To be fair, no other AI lab does real release notes either because they don’t actually know how much the model has changed for most users. Benchmarks would be nice, tho) https://t.co/I8ytNvIlzH

You on chase bank. You on mercury. If you’re starting a business and expect to make real money just go with someone who’s going to be friendly to what you’re doing and not accuse you of fraud for a 25k invoice. I’ve also learned you’re better off with multiple bank accounts. When chase froze my business account. I missed payroll and fucked up a lot of my billing. Leading to a cascade of issues. I’m going to be setting up a bank account with someone else soon. But the support team has been great so far.
Thank you @mercury. Now the chase saga is finally finished.
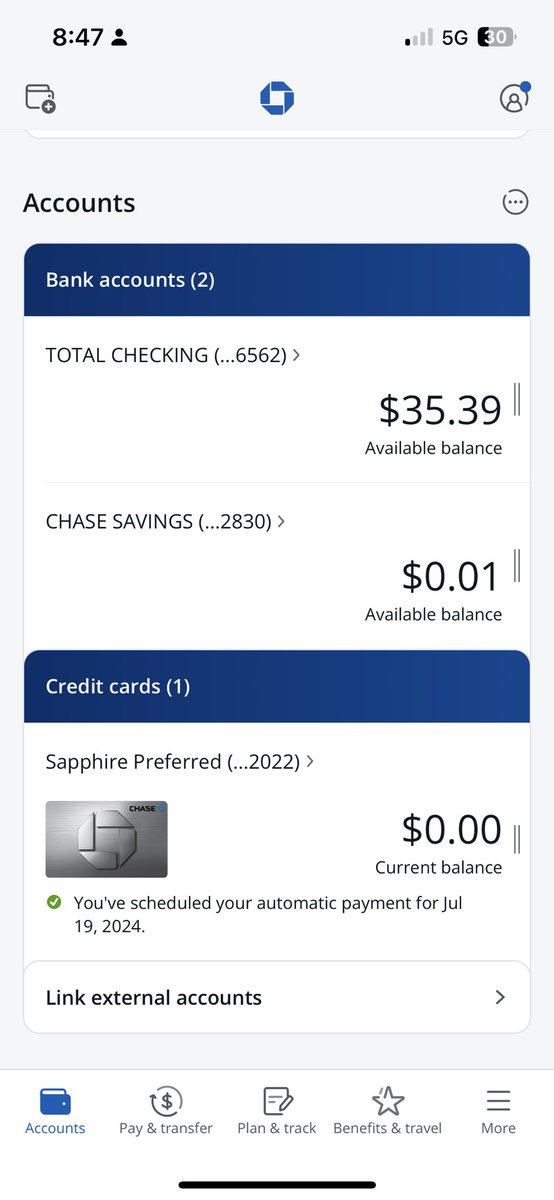
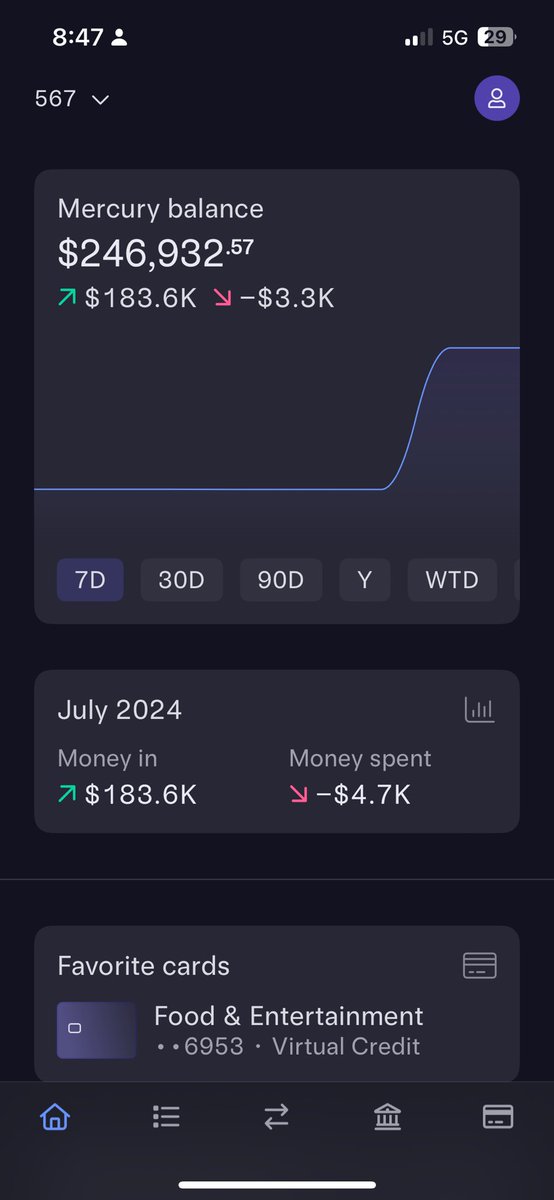
https://t.co/56qewjWKTu

Trying out the big four independent AI image creators with the prompt "an angry piece of garlic bread, staring into the darkness" (generated four images for each, picked the most angry garlic bread in each case). https://t.co/Hcn8jeg3cp

