@sivil_taram
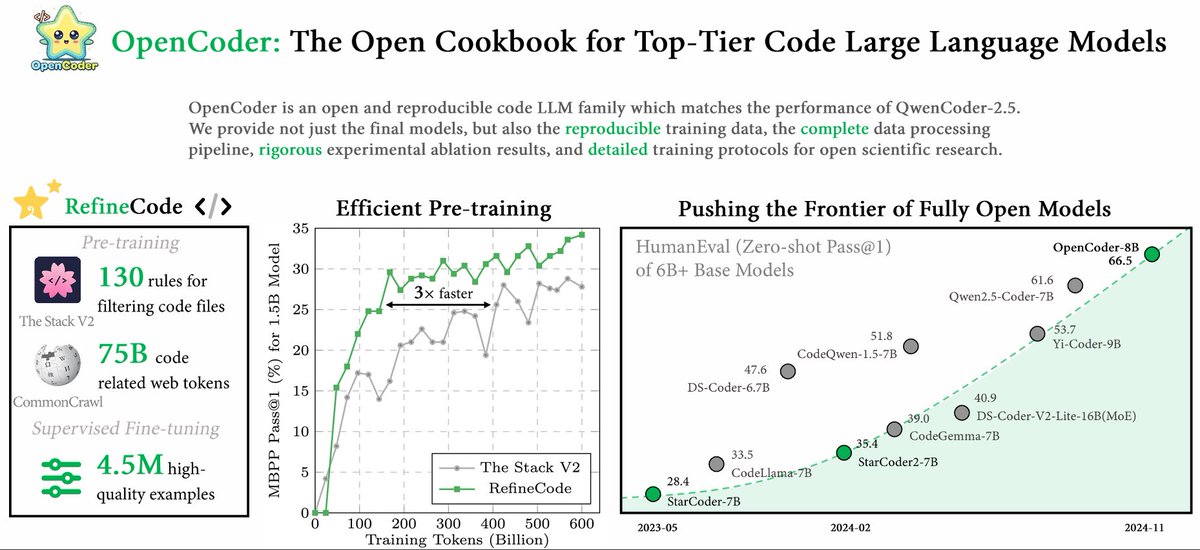
🔍Why could a coding model trained on just 2.5T tokens compete with top-tier models like DeepSeekCoder (10T tokens) and QwenCoder (15T tokens)? 🌟 Curious about the answer? Check out our paper, OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models (🏠 https://t.co/Hh5otarsvx, 📑 https://t.co/mkEr6kBkjk), a new code language model with top-tier code generation performance and fully openness! In this paper, we reveal the full details of our data cleaning, processing, and synthesis pipeline — insights that top labs often keep under wraps for code pre-training! Here’s what we offer: ✨ 1.5B & 8B code models supporting both English and Chinese 📚 Code to reproduce the 2.5T tokens of training data (coming soon!) 🛠️ 4.5M+ high-quality SFT examples This work was lead by awesome @SimingHUAN38187 , @crazycth0901 and @ziliwang8011184 . And please find more details in this thread! 🧵