@llama_index
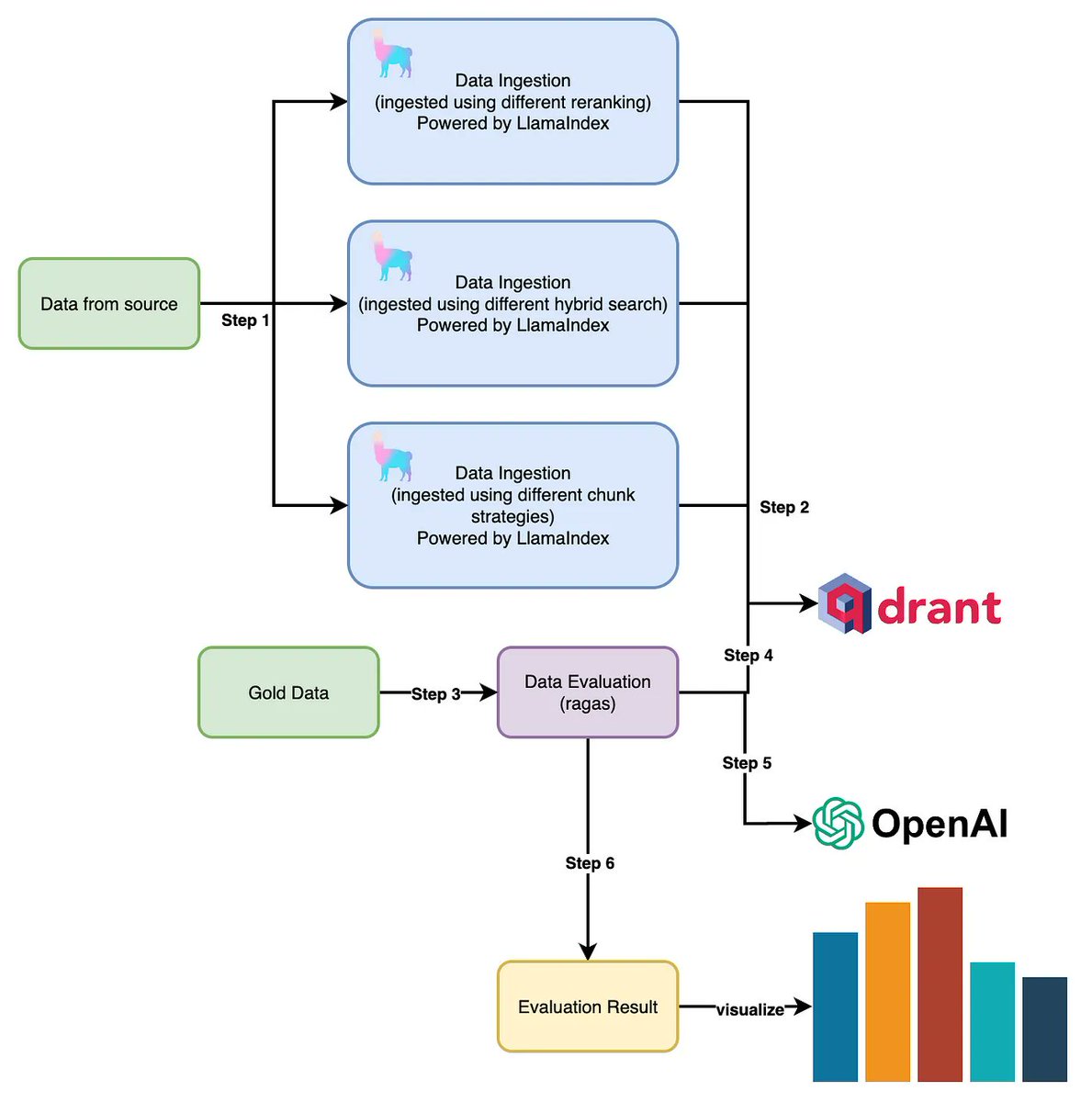
Advanced chunking strategies directly help improve retrieval and QA performance. @pavan_mantha1 not only provides an overview of 3️⃣ advanced chunking strategies, but provides a full evaluation setup so you can easily test this out on your own data: 1. semantic chunking 2. hierarchical topic parsing 3. “double-merge” chunking This is a great reference blog post if you’re looking to iterate on chunking to improve your RAG systems! https://t.co/aLvOvW1D5H