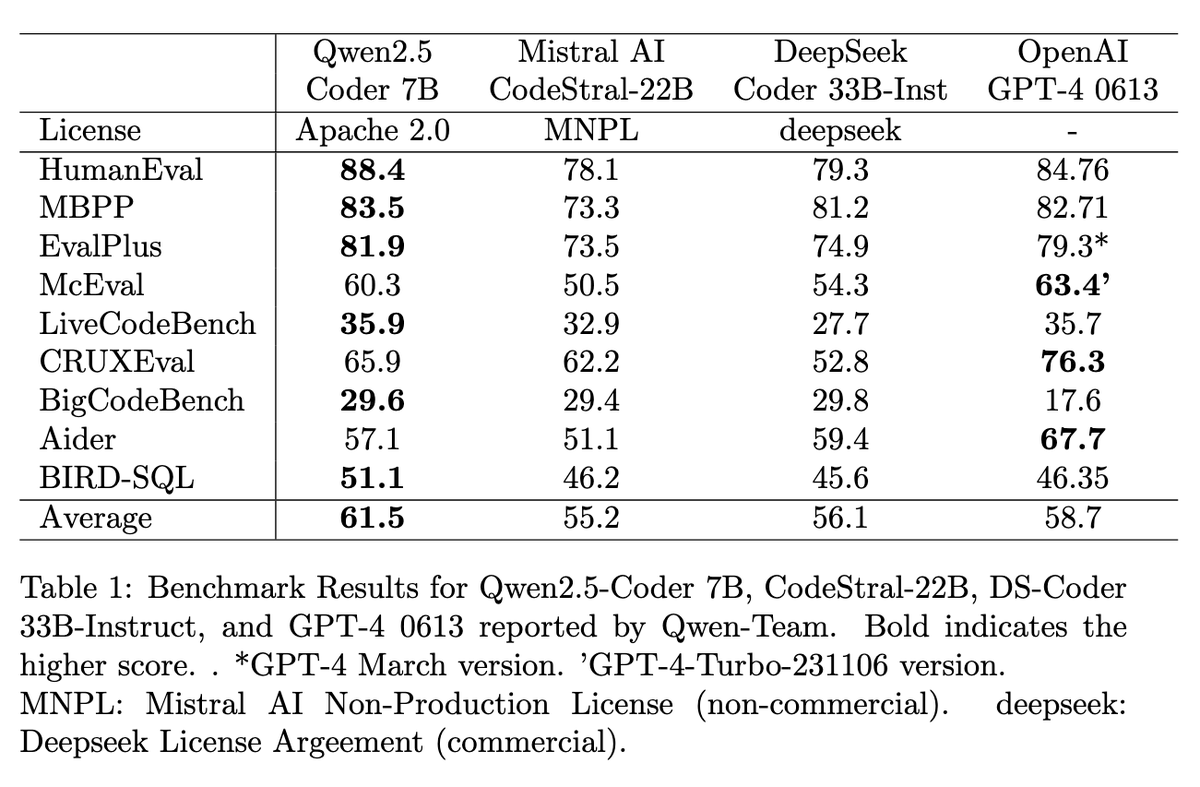
@_philschmid
GPT-4 for coding at home! Qwen 2.5 Coder 7B outperforms other @OpenAI GPT-4 0613 and open LLMs < 33B, including @BigCodeProject StartCoder, @MistralAI Codestral, or Deepseek, and is released under Apache 2.0. 🤯 Details: 🚀 Three model sizes: 1.5B, 7B, and 32B (coming soon) up to 128K tokens using YaRN 📚 Pre-trained on 5.5 trillion tokens, post-trained on tens of millions example (no details on # tokens) ⚖️ 7:2:1 ratio of public code data, synthetic data, and text data outperformed other combinations, even those with more code proportion. ✅ Build scalable synthetic data generation using LLM scorers, checklist-based scoring, and sandbox for code verification to filter out low-quality data. 🌐 Trained on 92+ programming languages and Incorporated multilingual code instruction data 📏 To improve long context, create instruction pairs with FIM format using AST 🎯 Adopted a two-stage post-training process—starting with diverse, low-quality data (tens of millions) for broad learning, followed by high-quality data with rejection sampling for refinement (millions). 🧹 Performed decontamination on all datasets (pre & post) to ensure integrity using a 10-gram overlap method 🏆 7B Outperforms other open Code LLMs < 40B, including Mistral Codestral, or Deepseek 🥇 7B matches OpenAI GPT-4 0613 on various benchmarks 🤗 Released under Apache 2.0 and available on @huggingface Models: https://t.co/esgNKlOxAt Paper: https://t.co/Vv6rS14QJA