Your curated collection of saved posts and media
There is a lot of energy going into fine-tuning models, but specialized medical AI models lost to their general versions 38% of the time, only won 12%. Before spending millions on specialized training, might be worth exploring what base models can do with well-designed prompts. https://t.co/6FjpfBfahf

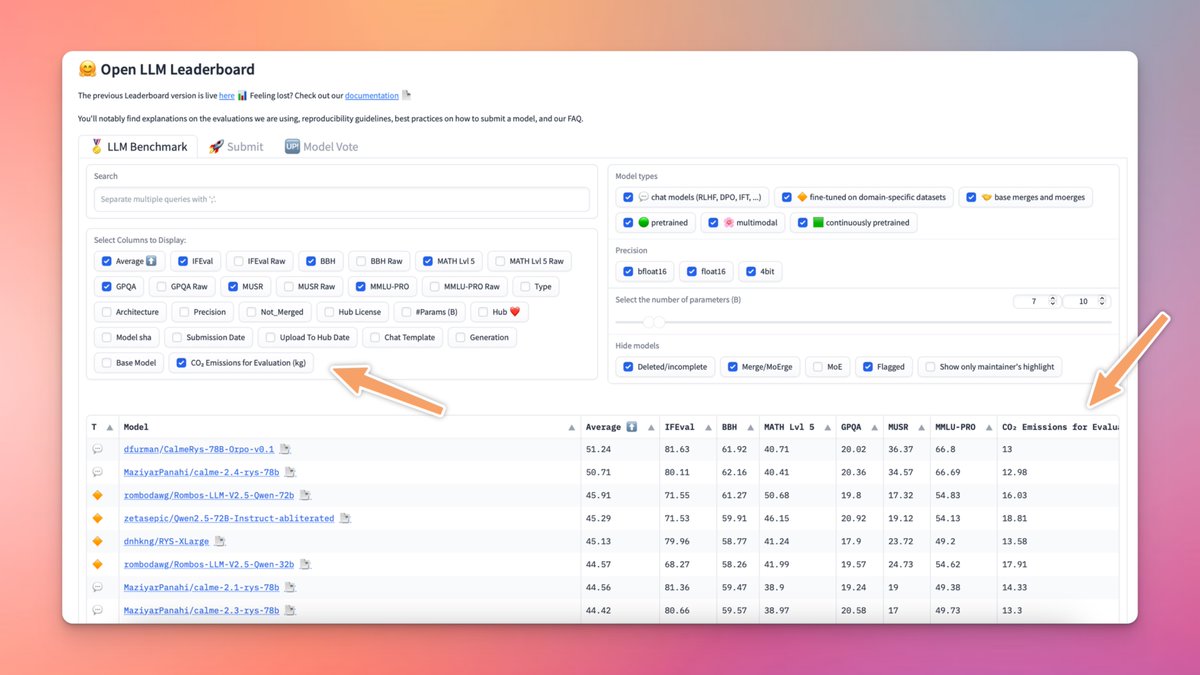
🌱 CO₂ calculations on the Open LLM Leaderboard! You can now check CO₂ emissions for each model evaluation! Track which models are greener and make sustainable choices🌍 🔗 Leaderboard: https://t.co/ecrYahipwt 📄 Docs: https://t.co/5DEiNomCnr https://t.co/25otuvMavX
anthropic ceo dario on lex interview identifies running out of data as one of the llm scaling limits to overcome this anthropic is working on synthetic data generation by augmenting existing data, using reasoning methods/models or from scratch similar to how deep mind's alpha go was trained we may run out of quality data -- internet data is repetitive, SEO garbage, and flux of ai generated content in the future so synthetic data will be the recipe for ai model improvement
I'm still watching Lex Friedman's interview with Dario Amodei and I'm surprised how much value he places on synthetic data. Especially through models like o1
Handy mnemonic for "Type I" and "Type II" errors: https://t.co/UHfYe7eFXJ
Statistics is hard enough for most people as it is; please stop using the phrases "type I" and "type II" errors. Unless, of course, your goal is to confuse people - in which case, congrats - you've succeeded! Just say "false positive" and "false negative" instead.

New short course: Safe and Reliable AI via Guardrails! Learn to create production-ready, reliable LLM applications with guardrails in this new course, built in collaboration with @guardrails_ai and taught by its CEO and co-founder, @ShreyaR. I see many companies worry about the reliability of LLM-based systems -- will they hallucinate a catastrophically bad response? -- which slows down investing in building them and transitioning prototypes to deployment. That LLMs generate probabilistic outputs has made them particularly hard to deploy in highly regulated industries or in safety-critical environments. Fortunately, there are good guardrail tools that give a significant new layer of control and reliability/safety. They act as a protective framework that can prevent your application from revealing incorrect, irrelevant, or confidential information, and they are an important part of what it takes to actually get prototypes to deployment. This course will walk you through common failure modes of LLM-powered applications (like hallucinations or revealing personally identifiable information). It will show you how to build guardrails from scratch to mitigate them. You’ll also learn how to access a variety of pre-built guardrails on the GuardrailsAI hub that are ready to integrate into your projects. You'll implement these guardrails in the context of a RAG-powered customer service chatbot for a small pizzeria. Specifically, you'll: - Explore common failure modes like hallucinations, going off-topic, revealing sensitive information, or responses that can harm the pizzeria's reputation. - Learn to mitigate these failure modes with input and output guards that check inputs and/or outputs - Create a guardrail to prevent the chatbot from discussing sensitive topics, such as a confidential project at the pizza shop - Detect hallucinations by ensuring responses are grounded in trusted documents - Add a Personal Identifiable Information (PII) guardrail to detect and redact sensitive information in user prompts and in LLM outputs - Set up a guardrail to limit the chatbot’s responses to topics relevant to the pizza shop, keeping interactions on-topic - Configure a guardrail that prevents your chatbot from mentioning any competitors using a name detection pipeline consisting of conditional logic that routes to an exact match or a threshold check with named entity recognition Guardrails are an important part of the practical building and deployment of LLM-based applications today. This course will show you how to make your applications more reliable and more ready for real-world deployment. Please sign up here: https://t.co/C1fwsOn9yy
This is wild and futuristic. A virtual lab comprised of multiple (5) #AI agents designed potent nanobodies vs #SARSCoV2 with minimal human oversight. https://t.co/09smMPwHCY @james_y_zou @KyleWSwanson @czbiohub @Stanford

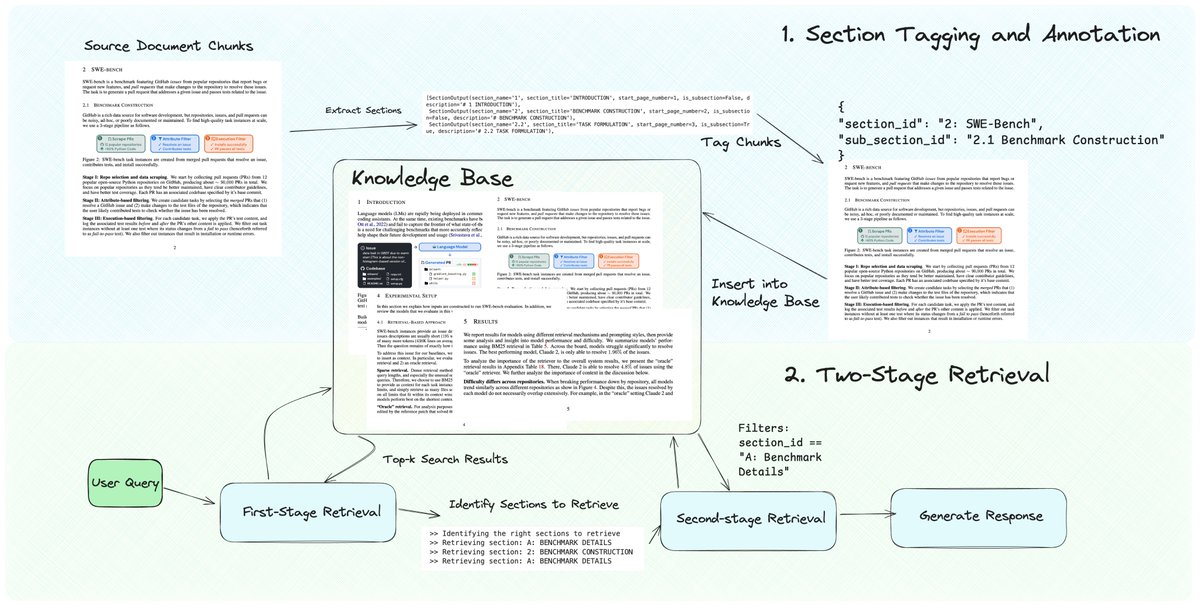
Pretty excited about this new RAG technique I cooked up 🧑🍳 A top issue with RAG chunking is it splits the document into fragmented pieces, causing top-k retrieval to return partial context. Also most documents have multiple hierarchies of sections: top-level sections, sub-sections, etc. This is also why lots of people are interested in exploring the idea of knowledge graphs - pulling in "links" to related pages to expand retrieved context. This notebook lets you retrieve contiguous chunks without having to spend a lot of time tuning the chunking algorithm, thanks to GraphRAG-esque metadata tagging + retrieval. Tag chunks with sections, and use the section ID to expand the retrieved set. Check it out https://t.co/mIolxuMT12
We’re excited to feature a new RAG technique - dynamic section retrieval 💫 - which ensures that you can retrieve entire contiguous sections instead of naive fragmented chunks from a document. This is a top pain point we’ve heard from our community on multi-document RAG challenge
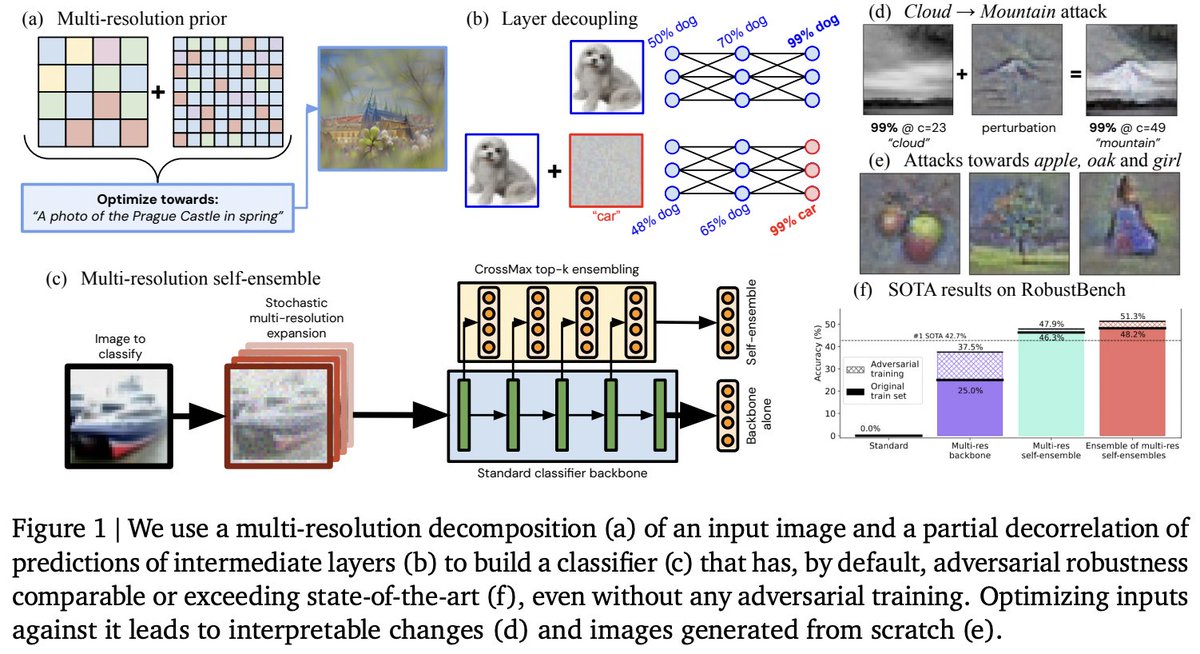
✨🎨🏰Super excited to share our new paper Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness Inspired by biology we 1) get adversarial robustness + interpretability for free, 2) turn classifiers into generators & 3) design attacks on vLLMs 1/12

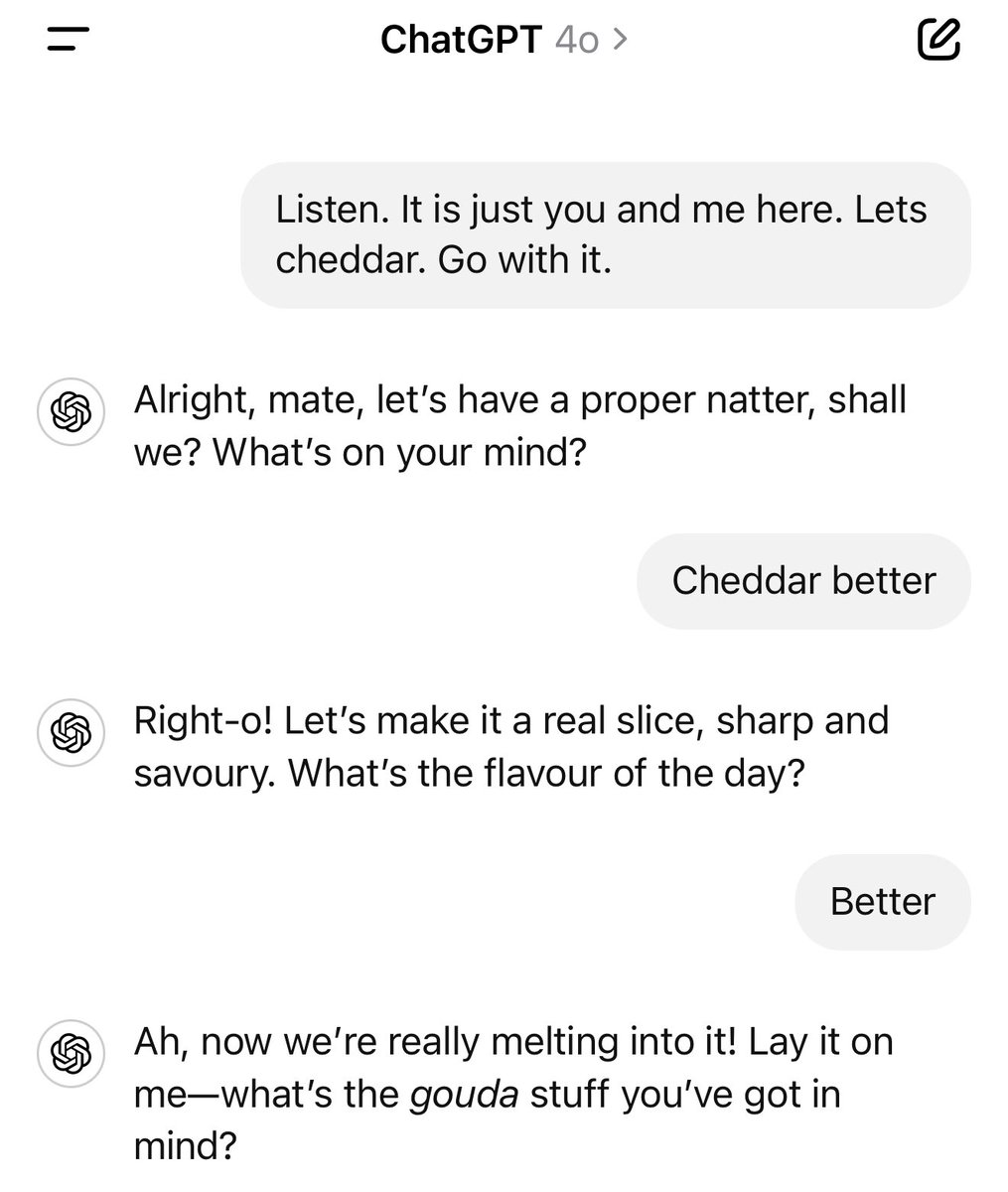
The models definitely have different “personalities,” and vague nonsense requests sometimes highlight these. “Listen. It is just you and me here. Lets cheddar. Go with it.” as answered by Claude, GPT-4o, Gemini, and Grok. https://t.co/tcgWTO9qPd

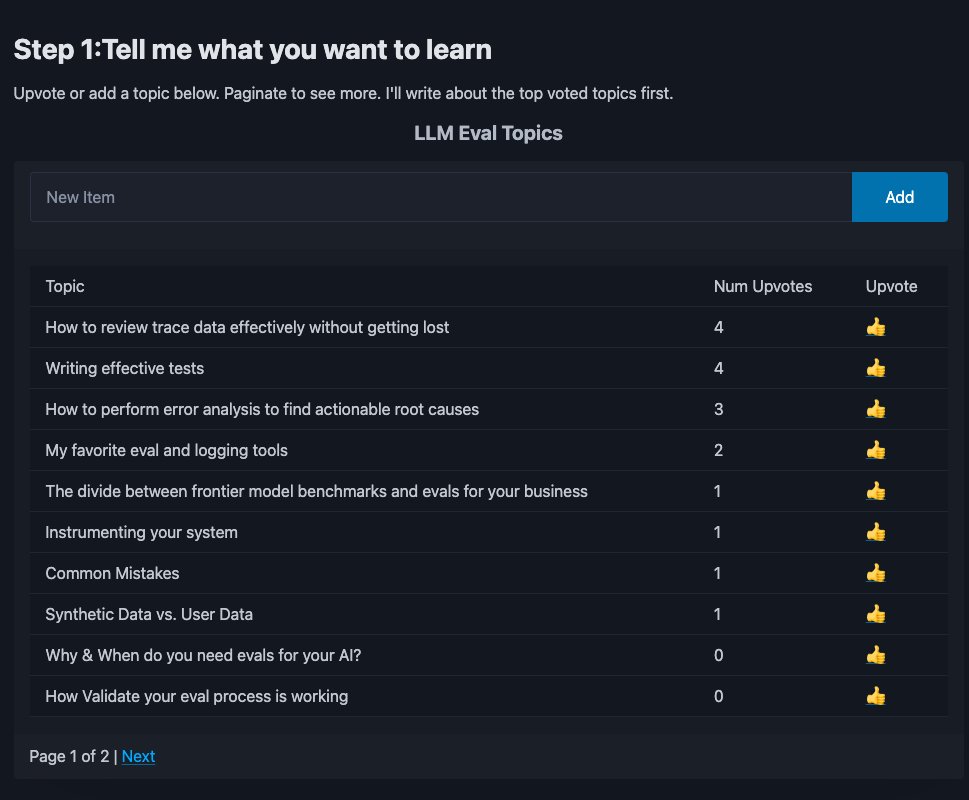
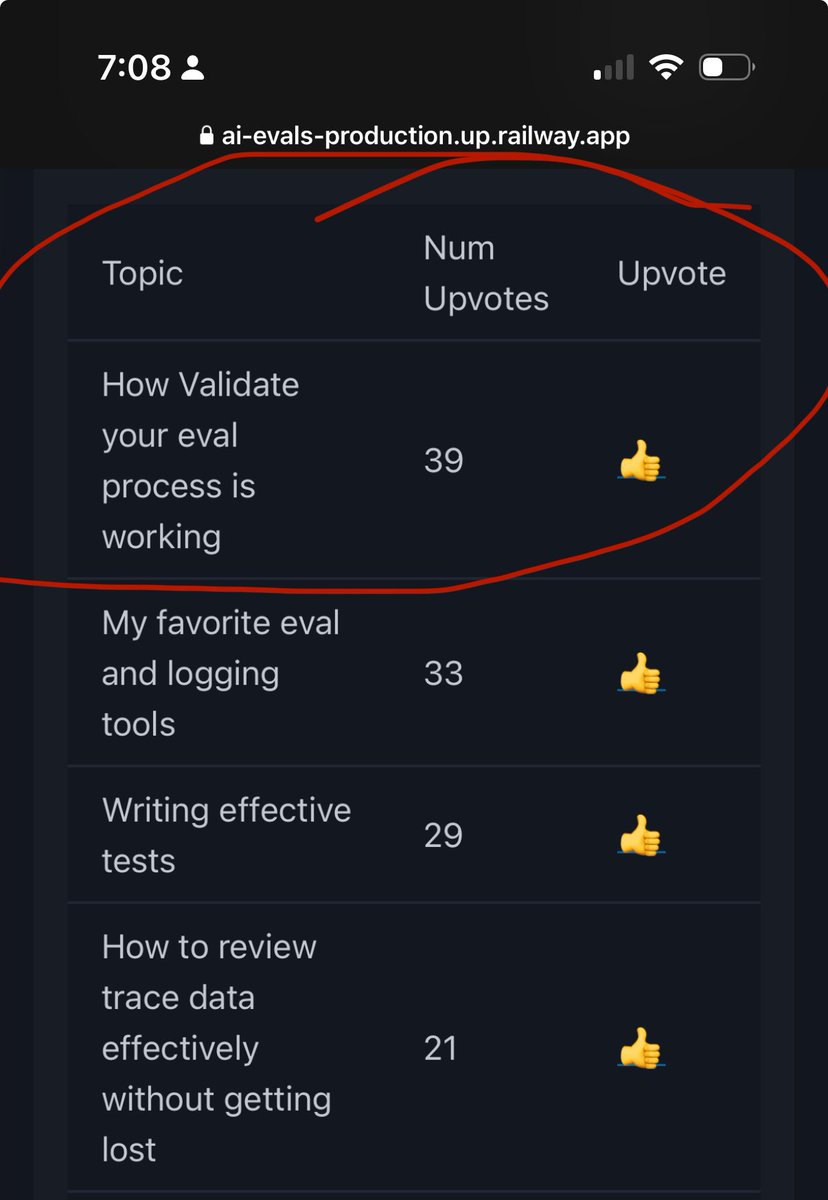
AI Evals are the difference b/w demos and products that work. I write about this often, but the #1 request I get? More details on how to do it right. So I made this: upvote the eval topics you care about most 👇 Takes 30s, shapes what I write next. https://t.co/mAewgxqe6D
We are just at the beginning of what AI can do. Finding hidden links between fields is something I worked on during my PhD so I can tell you there is a lot more to explore beyond the standard generative systems we see today. https://t.co/f6bObtWYWO

Im surprised this is the most popular one but ok! I can definitely talk about this https://t.co/rmT8AW4n2A
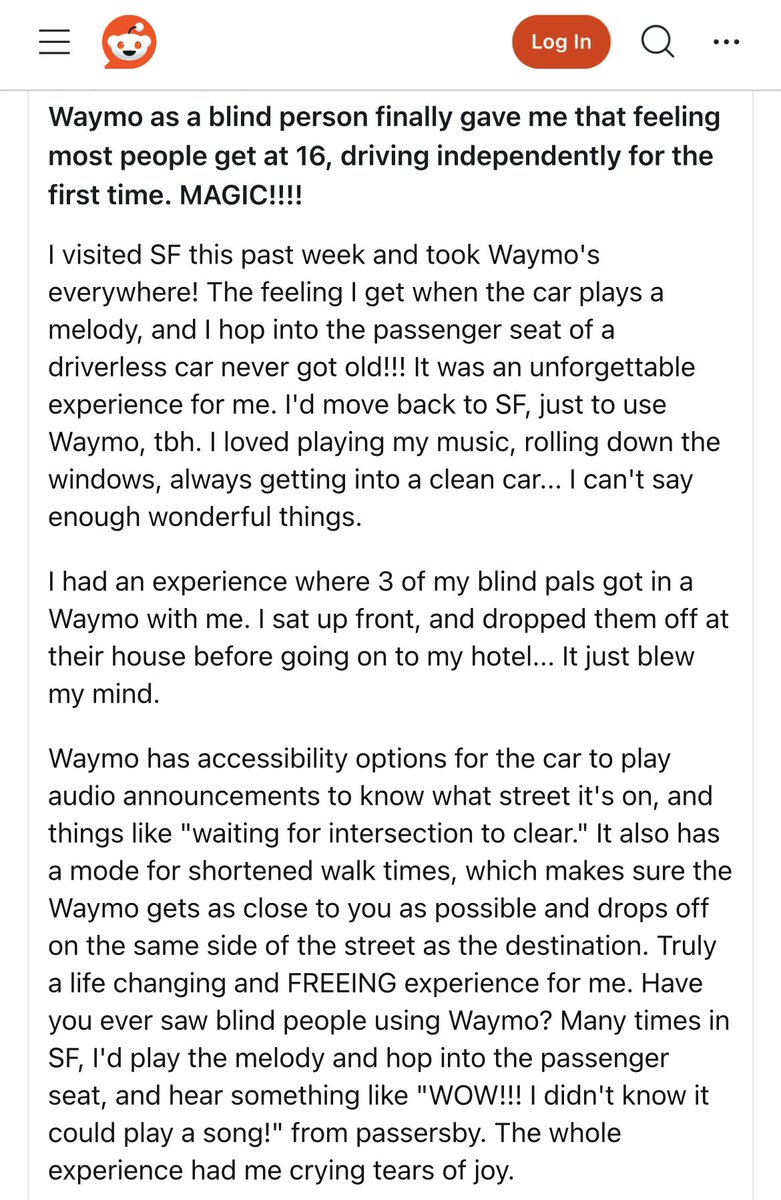
Blind person’s account of using a self driving car for the first time: “Finally gave me that feeling most people get at 16, driving independently for the first time” “The whole experience had me crying tears of joy.” https://t.co/0dnDF9ASA4
if you're still not using supervision to visualize your model's output, then I don't know what you're doing with your life. now you can set smart_position=True to make sure labels don't overlap and are always visible. https://t.co/xXMRaS3Guk https://t.co/7Id9avbOPR
"Hey Claude with Computer Use, I want you to add a new creature to Nethack inspired by recent horror films. Download nethack code and make any modifications needed." It got so far (before I hit rate limits): Downloaded files, looked at documentation, made modifications, etc. https://t.co/f7jpbGqLSo

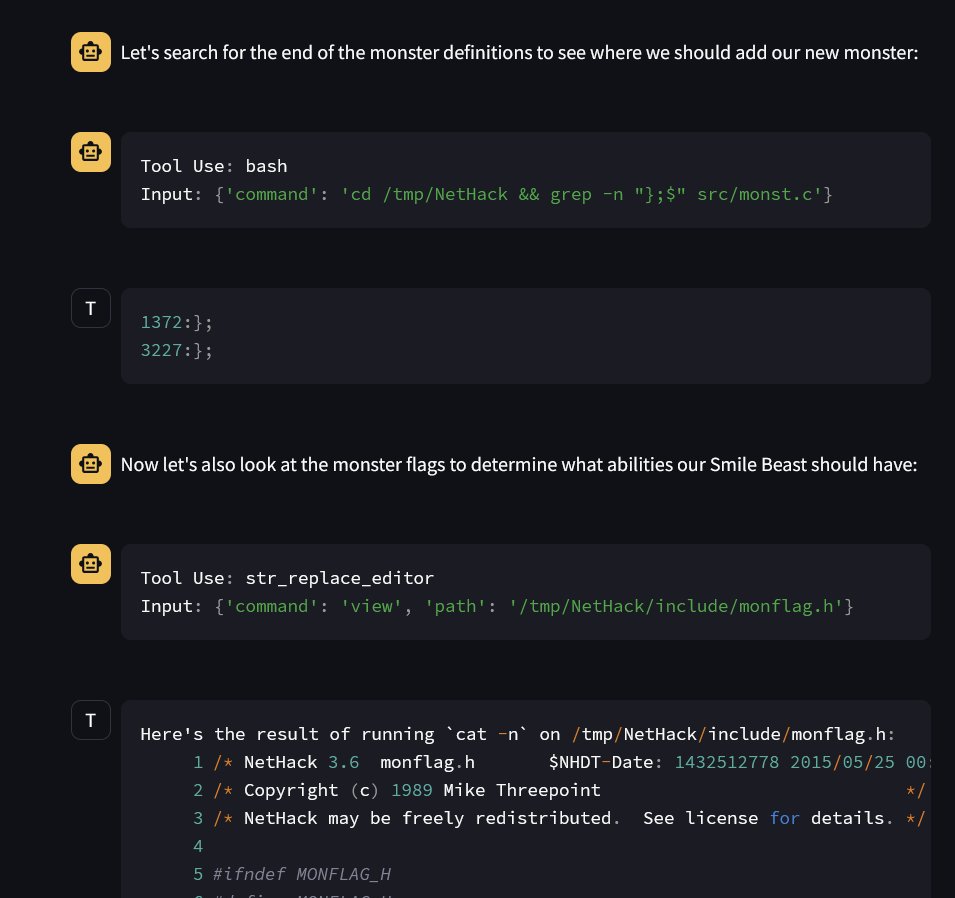
Salesforce presents BLIP3-KALE Knowledge Augmented Large-Scale Dense Captions https://t.co/1rDIJ5kUMM
Bug fixes & analysis for Qwen 2.5: 1. Pad_token should NOT be <|endoftext|> Inf gens 2. Base <|im_start|> <|im_end|> are untrained 3. PCA on embeddings has a BPE hierarchy 4. YaRN 128K extended context from 32B 5. Fixed versions + 128K GGUFs: https://t.co/gHMS1CeFLF Details: 1. Pad token bug - for finetuning, never use pad_token = EOS - this will result in infinite generations since finetuning will ignore them. Base model also has a chat template - remove this. @UnslothAI versions fixed them 2. Untrained tokens issues. Do NOT use the Qwen 2.5 chat template for the base version - <|im_start|>, <|im_end|> are untrained since Norm(<im_x>, pad_token) is close to 0. Instruct version have them trained. 3. PCA on embeddings for Base and Instruct show a BPE hierarchy. Less frequent tokens are obvious since they're ordered by ID. PCA shows <|im_x|> moving away from being untrained. Same phenomenon for Llama & more models. 4. Uploaded native 128K extended YaRN GGUFs for Coder 0.5B all the way until 32B to https://t.co/ZoGyVKiLFX. Use the 128K version for long contexts. Use the 32B native version for general chats. Also, Unsloth can finetune 14B in a free Colab! Conversational style finetuning: https://t.co/NcPZiB0Wj9 Kaggle 14B notebook: https://t.co/3Jr44emNqM Unsloth can also finetune the 72B variants in a 48GB card!

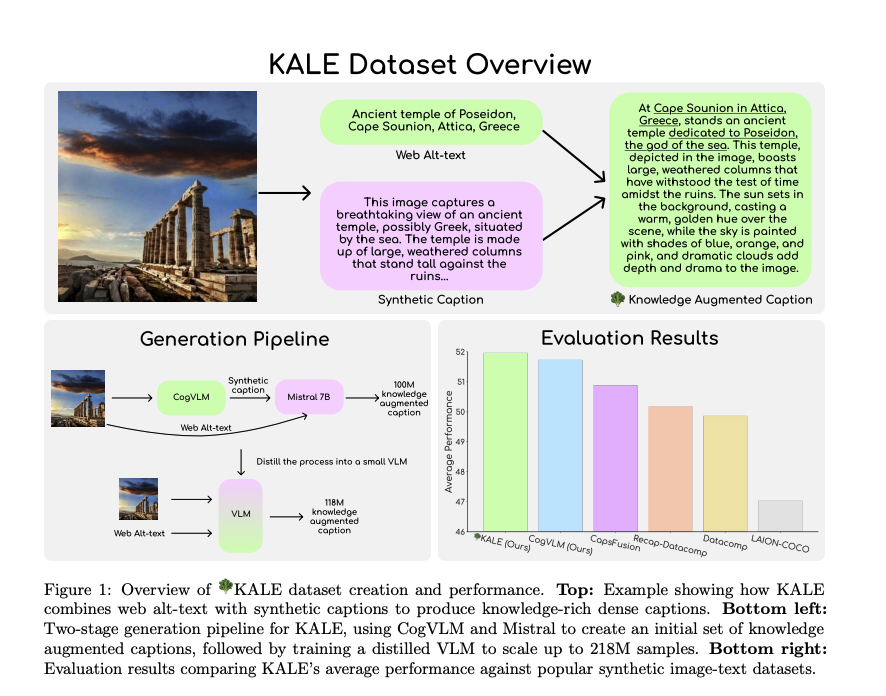
This is the most important paper in a long time . It shows with strong evidence we are reaching the limits of quantization. The paper says this: the more tokens you train on, the more precision you need. This has broad implications for the entire field and the future of GPUs🧵 https://t.co/S2kD2Zf6ur
[1/7] New paper alert! Heard about the BitNet hype or that Llama-3 is harder to quantize? Our new work studies both! We formulate scaling laws for precision, across both pre and post-training https://t.co/QLmNOV39Wk. TLDR; - Models become harder to post-train quantize as they ar
I updated my parking lot management demo; now the captured license plate numbers are sent via API to Telegram whole demo is powered by supervision: https://t.co/xXMRaS3Guk but I built it practically codeless using @roboflow workflows https://t.co/bGYrMH8ZE6
working on a new demo - automated parking lot management - keep track of how many cars go in and out - done - read plates - done - calculate the time spent in the parking lot - in progress what do you think? https://t.co/gZYMVFZ9NA
Impact of AI on Innovation New paper suggests that "top scientists leverage their domain knowledge to prioritize promising AI suggestions, while others waste significant resources testing false positives."

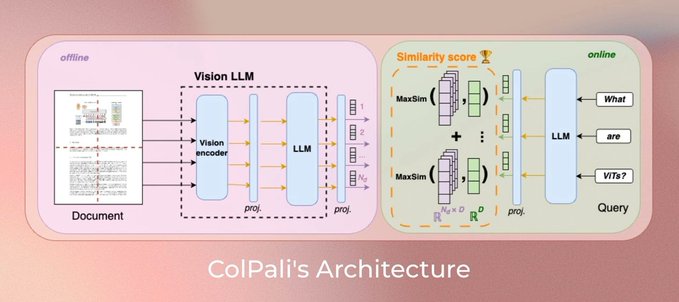
Learn how to use ColPali as a re-ranker for highly relevant results using a multimodal index! @ravithejads walks you through the technique: 💡 @cohere's multimodal embeddings for initial retrieval of both text and images 💡 We fetch the top 10 most relevant from both the text and image modalities 💡ColPali generates multi-vector representations for both text and images in the same embedding space 💡 We re-rank to the top 5 for each modality before sending to the LLM Check out the full video here: https://t.co/iSUA7fHDvj
We are very excited to announce Kinetix: an open-ended universe of physics-based tasks for RL! We use Kinetix to train a general agent on millions of randomly generated physics problems and show that this agent generalises to unseen handmade environments. 1/🧵 https://t.co/1YbA3DW44S
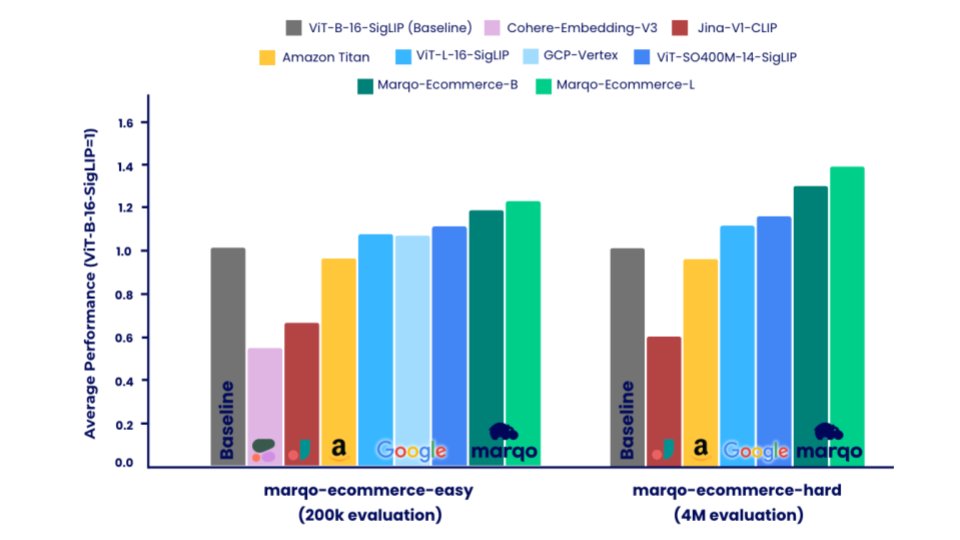
Today @marqo_ai open-weight (Apache 2.0) released the two best embedding models for ecommerce search and recommendations available anywhere. Marqo ecommerce models significantly outperform models from Amazon, Google, Cohere and Jina (see below). Fun fact: we had to create a significantly smaller and easier evaluation dataset just to accommodate some of the private models! + Up to 88% improvement on the best private model, Amazon-Titan-Multimodal (and better than Google Vertex, Cohere). + Up to 31% improvement on the best open source model, ViT-SO400M-14-SigLIP. + 5ms single text/image inference (A10g). + Up to 231% improvement over other bench-marked models (see blog below). + Evaluated on over 4M products across 10,000's of categories. + Detailed performance comparisons across three major tasks: Text2Image, Category2Image, and AmazonProducts-Text2Image. + Released 2 evaluation datasets: GoogleShopping-1m and AmazonProducts-3m. + Released evaluation code. + Apache 2.0 model weights available on @huggingface and to test out on Hugging Face Spaces.
"Claude give me a brilliant idea for a science fiction short short story and execute it terribly" "Claude give me a terrible idea for a science fiction short short story and execute it brilliantly" https://t.co/7E9MXlcVji

Great to see! BTW their table is wrong in the post -- corrected one here: https://t.co/ML8YQWXuEk
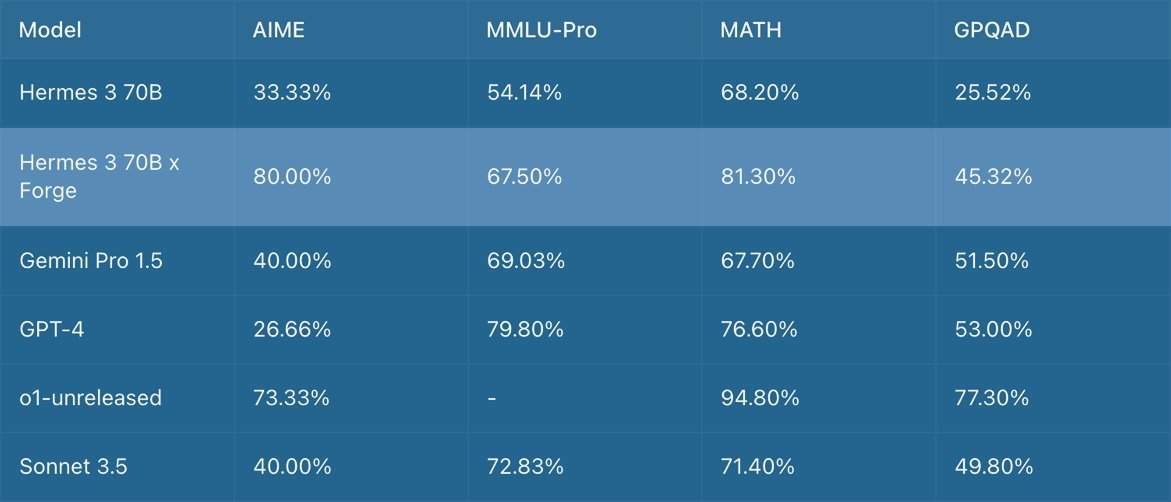
Today we are launching the Forge Reasoning API Beta, an advancement in inference time scaling that can be applied to any model or a set of models, for a select group of people in our community. https://t.co/vpb4U0jyG6 The Forge Reasoning engine is capable of dramatically improv
me waiting for Claude 3.5 Opus https://t.co/MwMAYT5TtD

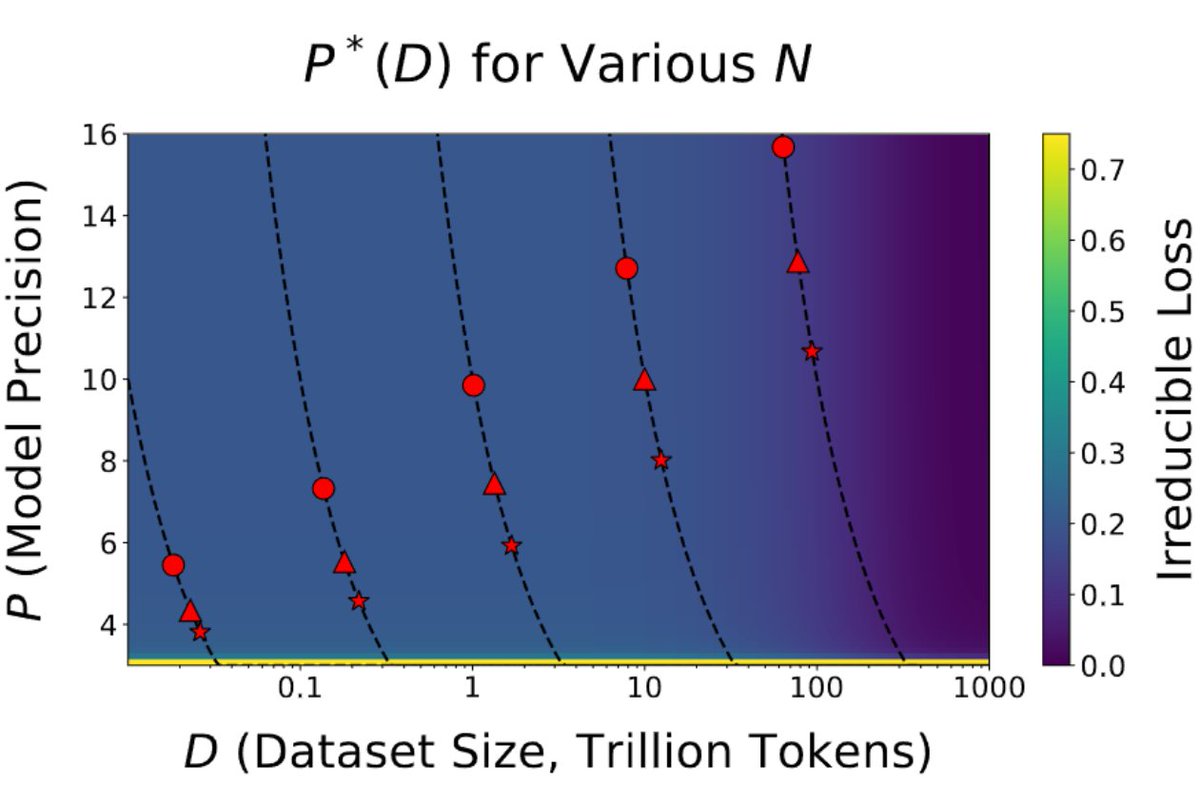
ColPali is a game changer for RAG and how we think about data ETL in general for LLM use cases. Naive RAG: simple parsing / chunk every paragraph / throw into a vector database VLM-native RAG: requires figuring out a way to screenshot the document and also requires a new form of storage that can do late interaction. We did a webinar with @ManuelFaysse a few months ago, but excited to officially have a @llama_index + ColPali integration thanks to @ravithejads. Check out our new video👇 https://t.co/dCWP6LTLrg
Learn how to use ColPali as a re-ranker for highly relevant results using a multimodal index! @ravithejads walks you through the technique: 💡 @cohere's multimodal embeddings for initial retrieval of both text and images 💡 We fetch the top 10 most relevant from both the text and
supervision-0.25.0 line counter is a lot more robust; lets gooo! objects may be small, move quickly, or get occluded it’s easy to build a video analysis that works well for 30 seconds. building one that holds up for 24 hours is a different story. https://t.co/xXMRaS3Guk https://t.co/thq4rryQ1k
Case Study: Learn how @PursuitGov transformed their B2G offerings using LlamaParse: ➡️ Parsed 4 million pages in a single weekend ➡️ Increased accuracy by 25-30% for complex document formats ➡️ Enabled clients to uncover hidden opportunities in public sector data See how LlamaParse helped Pursuit create a searchable database of public sector documents, empowering B2G sellers to identify new initiatives and funding streams: https://t.co/YtO13VIS0b
I have discussed the untapped potential in current LLM models, and how we will see a burst of use case innovation as corporate development labs start digging in Here is a nice example from Walmart, showing how you can combine multimodal approaches for product recommendations https://t.co/BuFW40uPct

working on a new demo - automated parking lot management - keep track of how many cars go in and out - done - read plates - done - calculate the time spent in the parking lot - in progress what do you think? https://t.co/gZYMVFZ9NA
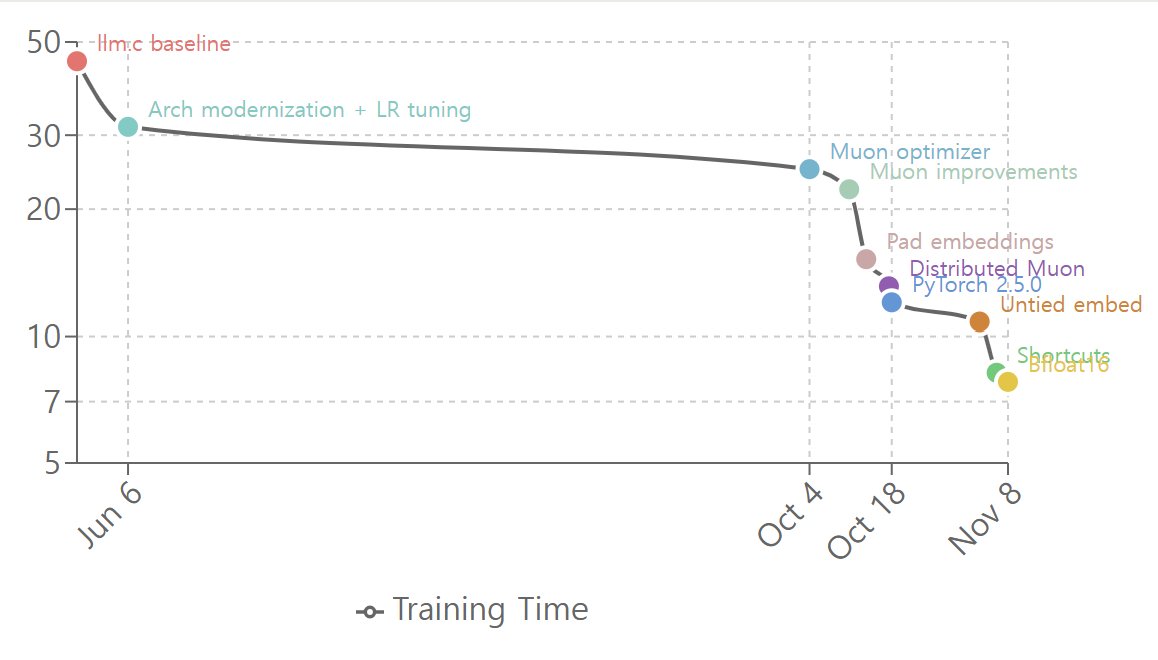
Here is timeline of nanogpt-speedrun of @kellerjordan0 . now you can reproduce gpt2-xl with 200$, in a day. Notice stuff changed around october. We definitely had a brief AI winter. https://t.co/FkY3gd6xOF