@Tim_Dettmers
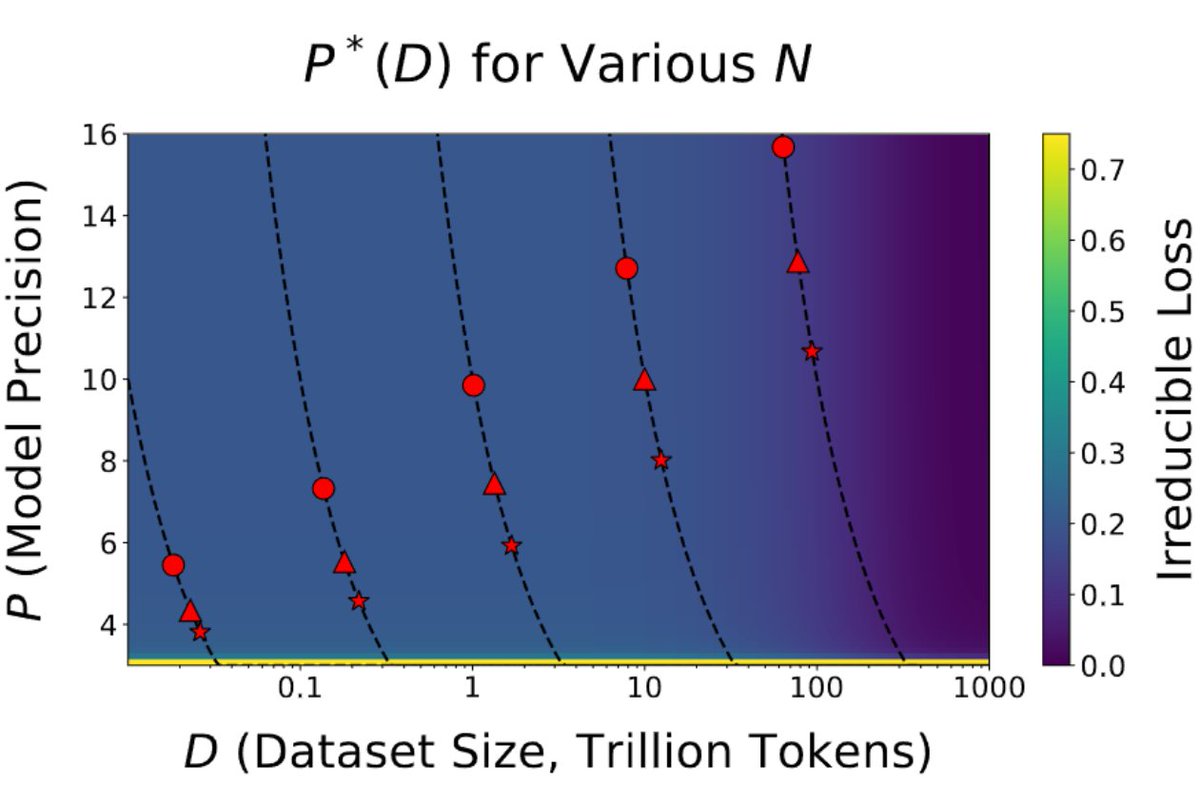
This is the most important paper in a long time . It shows with strong evidence we are reaching the limits of quantization. The paper says this: the more tokens you train on, the more precision you need. This has broad implications for the entire field and the future of GPUs🧵 https://t.co/S2kD2Zf6ur