@jerryjliu0
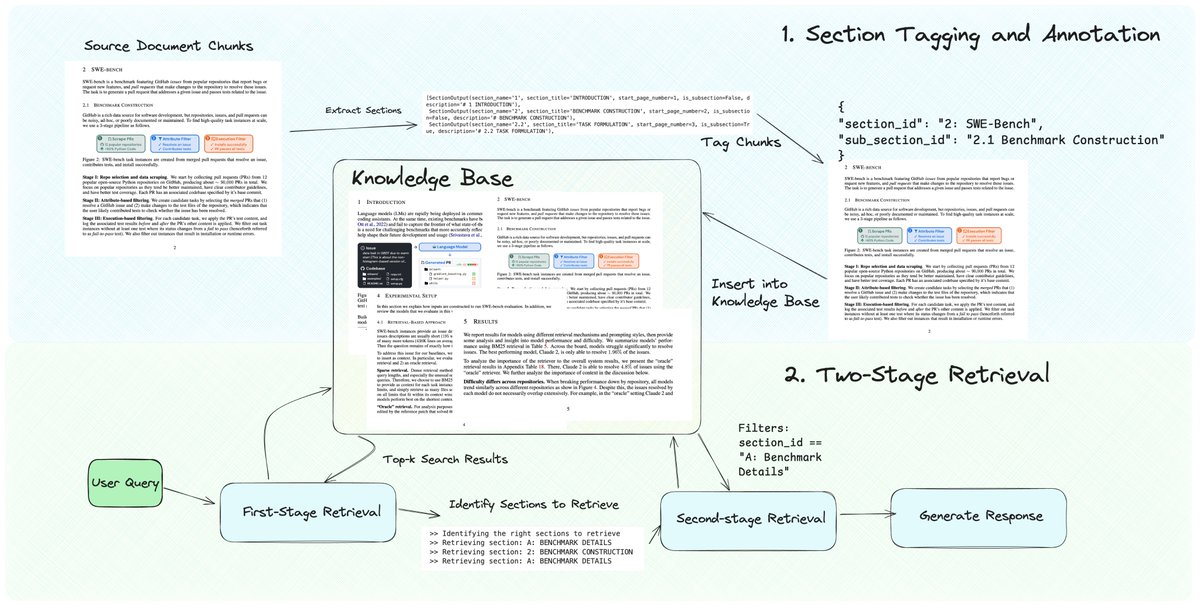
Pretty excited about this new RAG technique I cooked up 🧑🍳 A top issue with RAG chunking is it splits the document into fragmented pieces, causing top-k retrieval to return partial context. Also most documents have multiple hierarchies of sections: top-level sections, sub-sections, etc. This is also why lots of people are interested in exploring the idea of knowledge graphs - pulling in "links" to related pages to expand retrieved context. This notebook lets you retrieve contiguous chunks without having to spend a lot of time tuning the chunking algorithm, thanks to GraphRAG-esque metadata tagging + retrieval. Tag chunks with sections, and use the section ID to expand the retrieved set. Check it out https://t.co/mIolxuMT12