Your curated collection of saved posts and media
Introducing the Environments Hub RL environments are the key bottleneck to the next wave of AI progress, but big labs are locking them down We built a community platform for crowdsourcing open environments, so anyone can contribute to open-source AGI
Your brain doesn’t erase memories — it just loses the keys that unlock them. This paper introduces a key-value memory system that splits how the brain stores and retrieves. Keys go to the hippocampus for quick access. Values go to the neocortex for high-fidelity storage. https://t.co/XkINdf7XTr

Browserbase, an alternative to OpenAI's $200/month Operator Agent. A web browser for your AI, runs a fleet of headless browsers. https://t.co/DOuTxMnTHq
Try here: https://t.co/zTd8C84RrR
When a model gives you the right answer to a reasoning question, you can't tell whether it was via memorization or via reasoning. A simple way to tell between the two is to tweak your question in a way that 1. changes the answer, 2. requires some reasoning to adapt to the change. If you still get the same answer as before... it was memorization.
Improving RAG systems requires good evaluation datasets. This work uses a multi-agent framework to generate high-quality and private synthetic datasets for RAG evaluation. Another great example of the importance of specialized agents and clever tooling. https://t.co/EV3WrWwKXD

https://t.co/bo3D7d3nwU https://t.co/oW2BYGZf0U


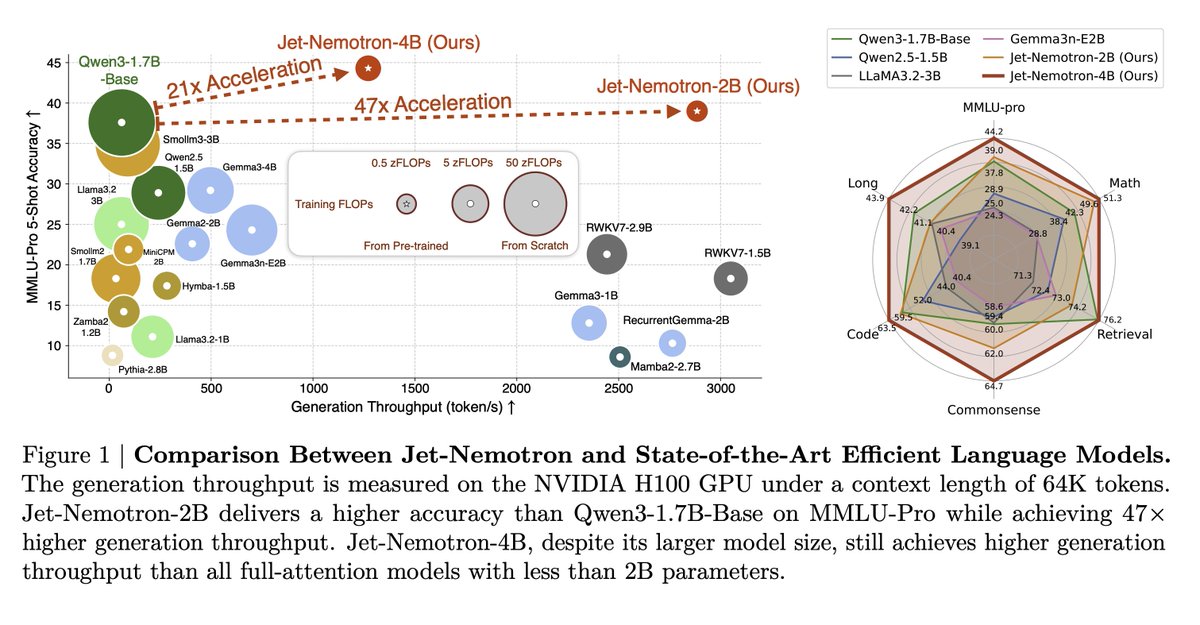
Efficient Language Model with PostNAS NVIDIA's recent research on LLMs has been fantastic. Jet-Nemotron is the latest in efficient language models, which significantly improves generation throughput. Here are my notes: https://t.co/bY6hzBHcqu

A hybrid-architecture LM family built by “adapting after pretraining.” Starting from a frozen full-attention model, the authors search where to keep full attention, which linear-attention block to use, and which hyperparameters match hardware limits. The result, Jet-Nemotron-2B/4B, matches or surpasses popular full-attention baselines while massively increasing throughput on long contexts.
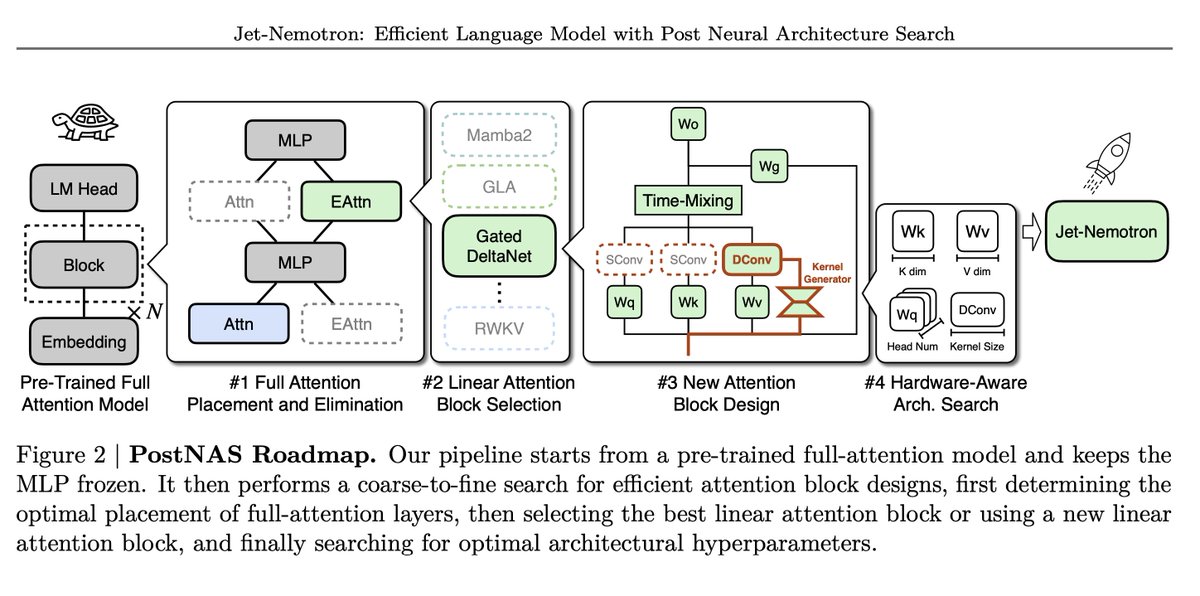
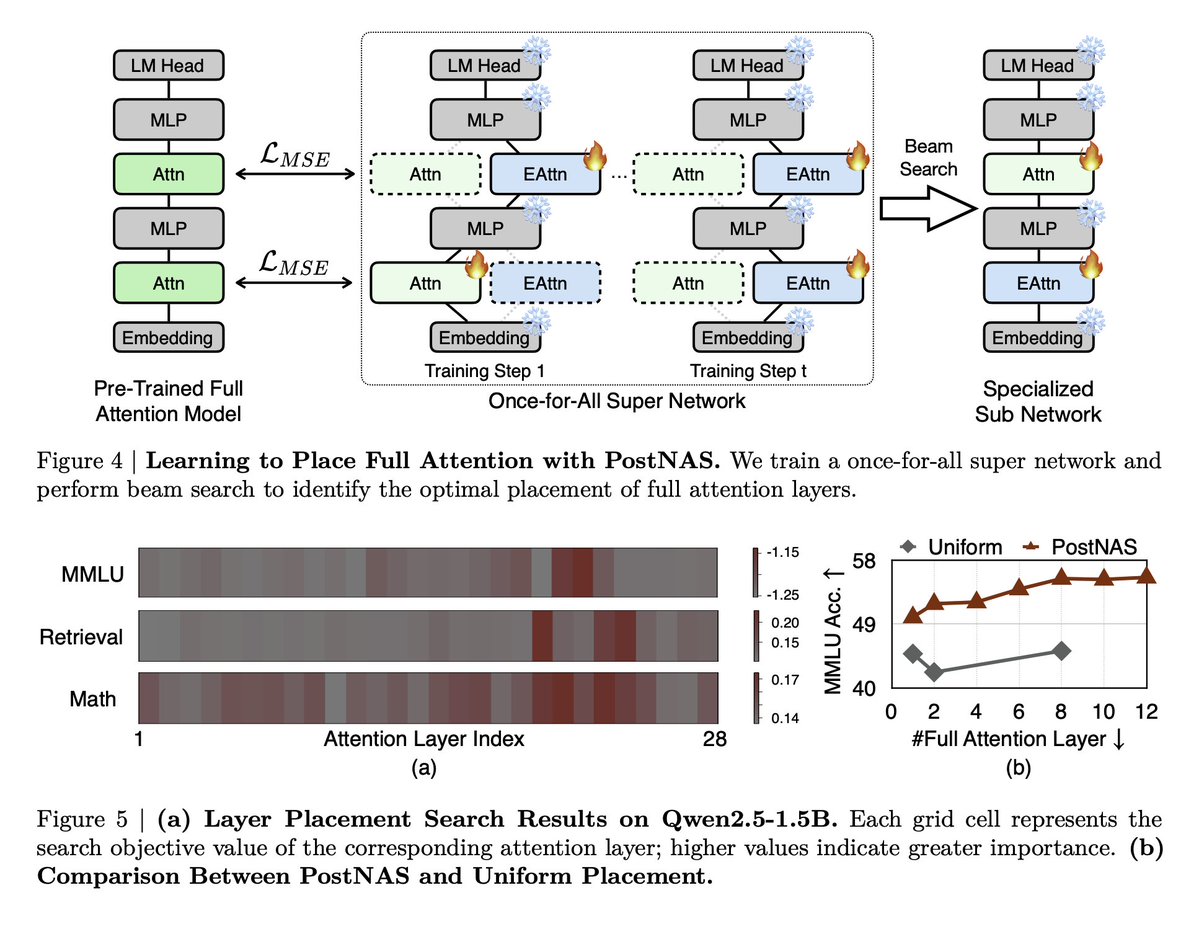
PostNAS pipeline Begins with a pre-trained full-attention model and freezes MLPs, then proceeds in four steps: 1. Learn optimal placement or removal of full-attention layers 2. Select a linear-attention block 3. Design a new attention block 4. Run a hardware-aware hyperparameter search
Learning where full attention actually matters A once-for-all super-network plus beam search identifies only a few layers as critical, and the “important layers” differ by task. https://t.co/nnYVy2Lajh
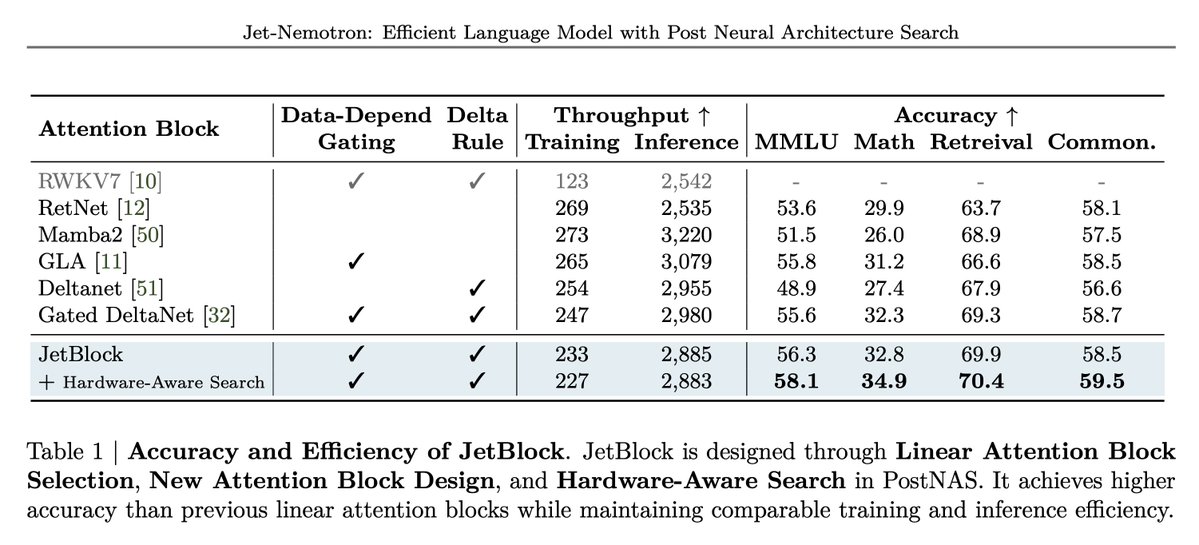
JetBlock: linear attention with dynamic convolution The new block adds a kernel generator that produces input-conditioned causal convolutions applied to V tokens and removes static convolutions on Q/K. They report higher math and retrieval accuracy vs. prior linear blocks at similar training and inference speed.
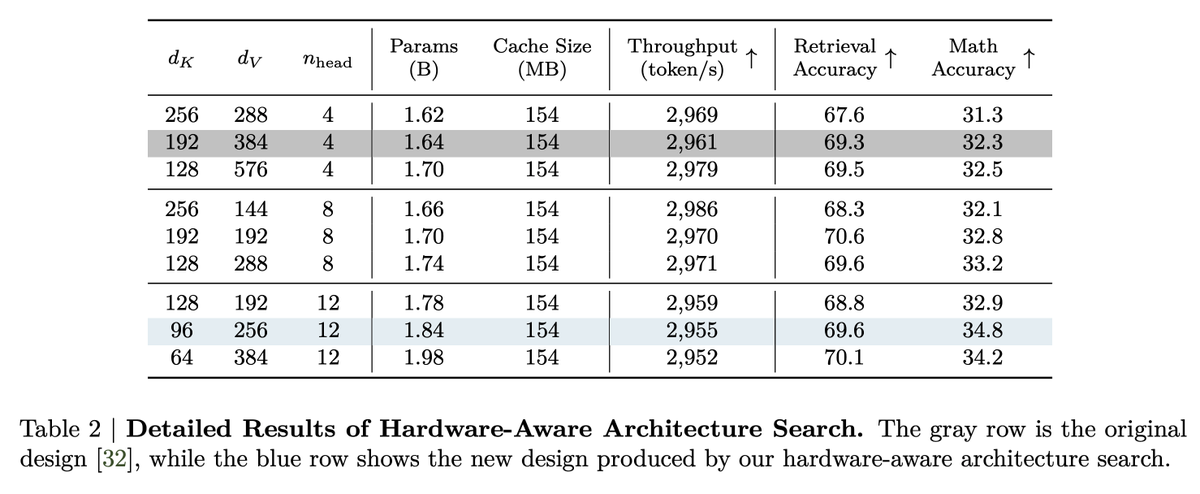
Hardware-aware design insight Through grid search at fixed KV cache size, they show generation speed tracks KV cache more than parameter count. Different head/dimension settings hold throughput roughly constant while improving accuracy. https://t.co/3DYXMubK1o
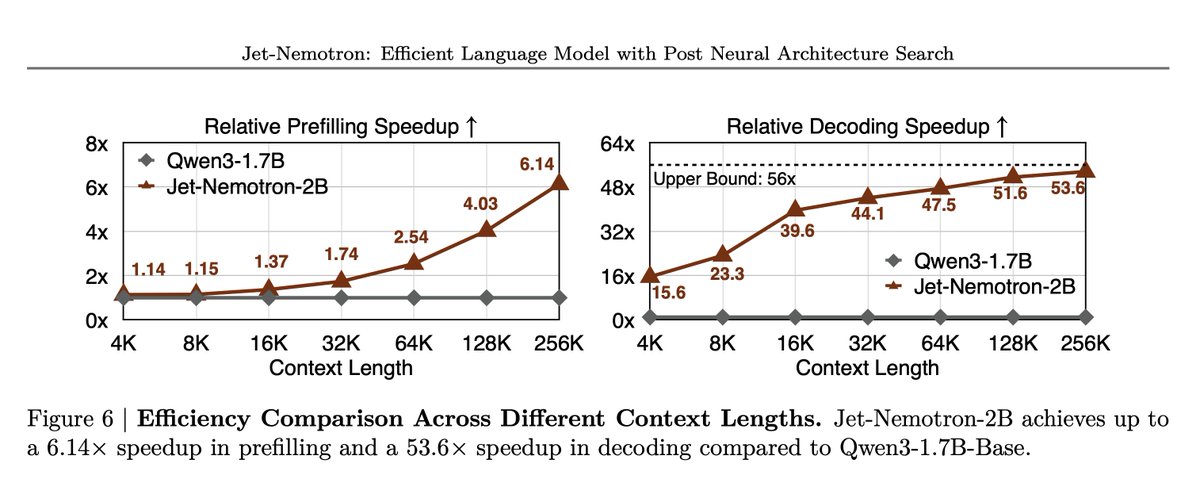
Results Jet-Nemotron-2B outperforms or matches small full-attention models on MMLU, MMLU-Pro, BBH, math, commonsense, retrieval, coding, and long-context tasks. All this while delivering up to 47x decoding throughput at 64K and as high as 53.6x decoding and 6.14x prefilling speedup at 256K on H100. Paper: https://t.co/rgTYY2q8WK

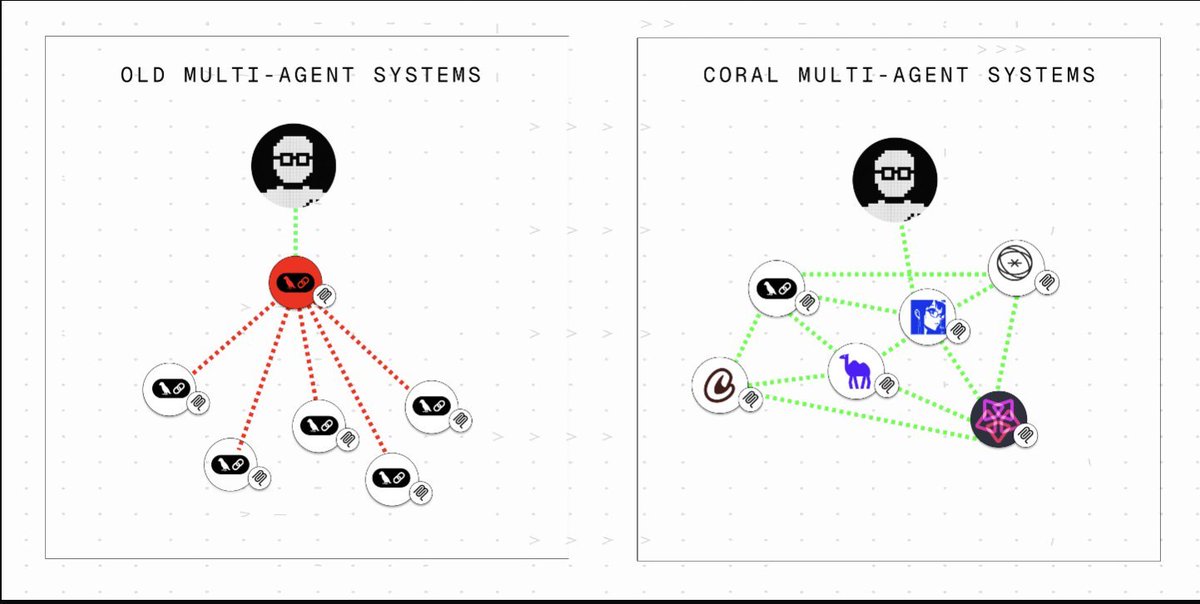
Don't sleep on small models! Anemoi is the latest multi-agent system that proves small models pack a punch when combined effectively. GPT-4.1-mini (for planning) and GPT-4o (for worker agents) surpass the strongest open-source baseline on GAIA. A must-read for devs: https://t.co/Yw9zPaOsZW

Quick Overview Anemoi is a semi-centralized generalist multi-agent system powered by an A2A communication MCP server from @Coral_Protocol. Anemoi replaces purely centralized, context-stuffed coordination with an A2A communication server (MCP) that lets agents talk directly, monitor progress, refine plans, and reach consensus.
Design A semi-centralized planner proposes an initial plan, while worker agents (web, document processing, reasoning/coding) plus critique and answer-finding agents collaborate via MCP threads. Agents communicate directly with each other. All participants can list agents, create threads, send messages, wait for mentions, and update plans as execution unfolds.
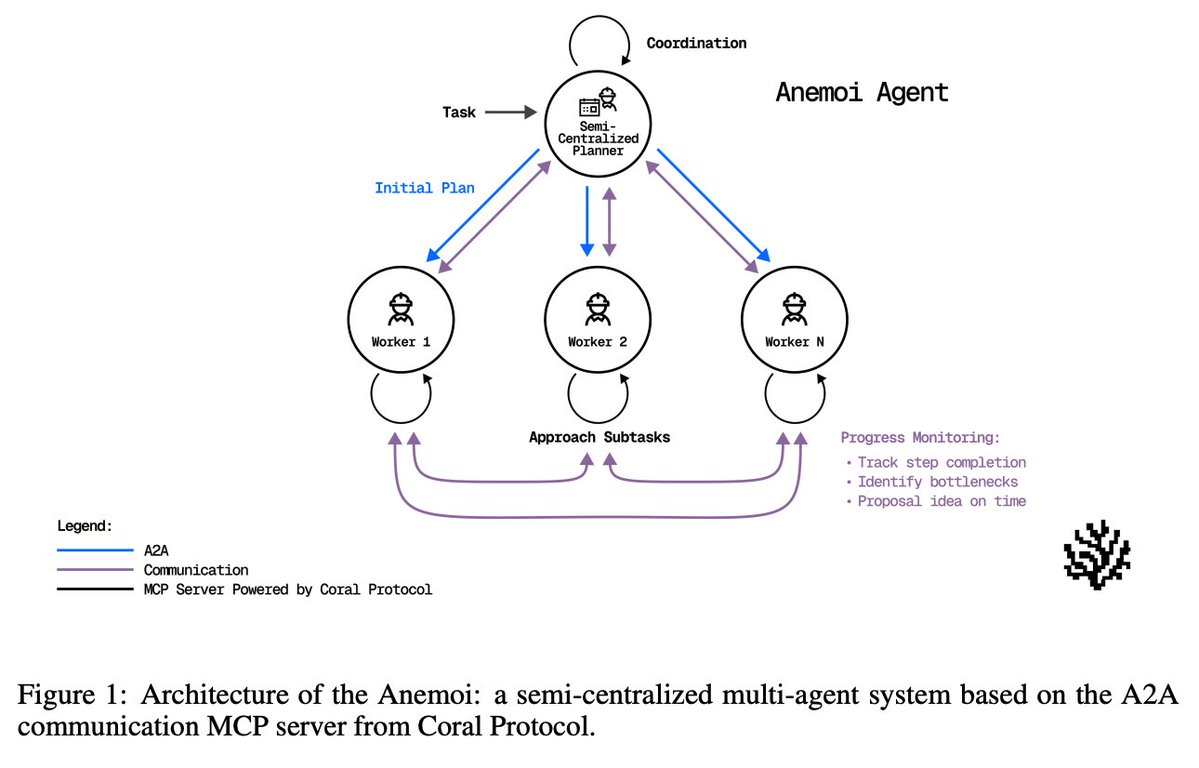
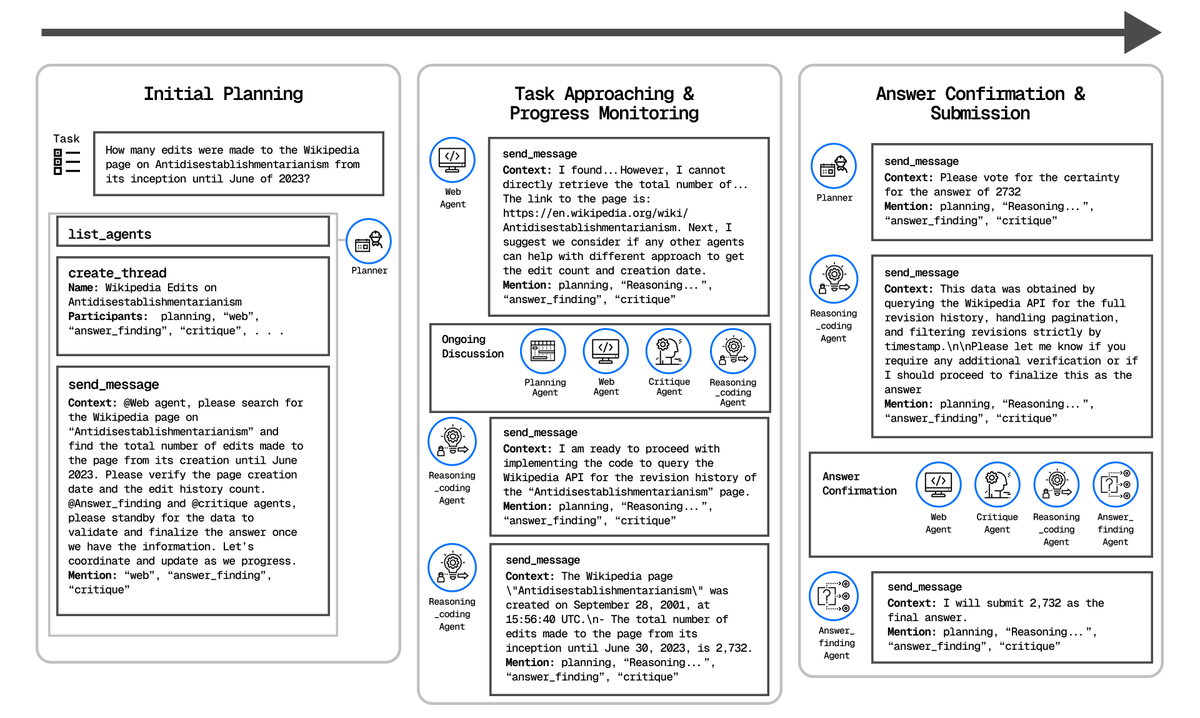
Communication workflow The communication workflow includes: 1. agent discovery 2. thread initialization with a task plan and tentative allocation 3. threads execution with continuous critique 4. consensus voting before submission 5. final answer synthesis https://t.co/ssfrYCQqda

Architecture > raw model size Benefits of Anemoi (named after the Greek gods of wind): • Efficient: no redundant context passing • Reliable: no single-point planner failure; agents communicate directly • Scalable: more worker agents, smaller planner, tighter budgets https://t.co/CrE0IeCaOr
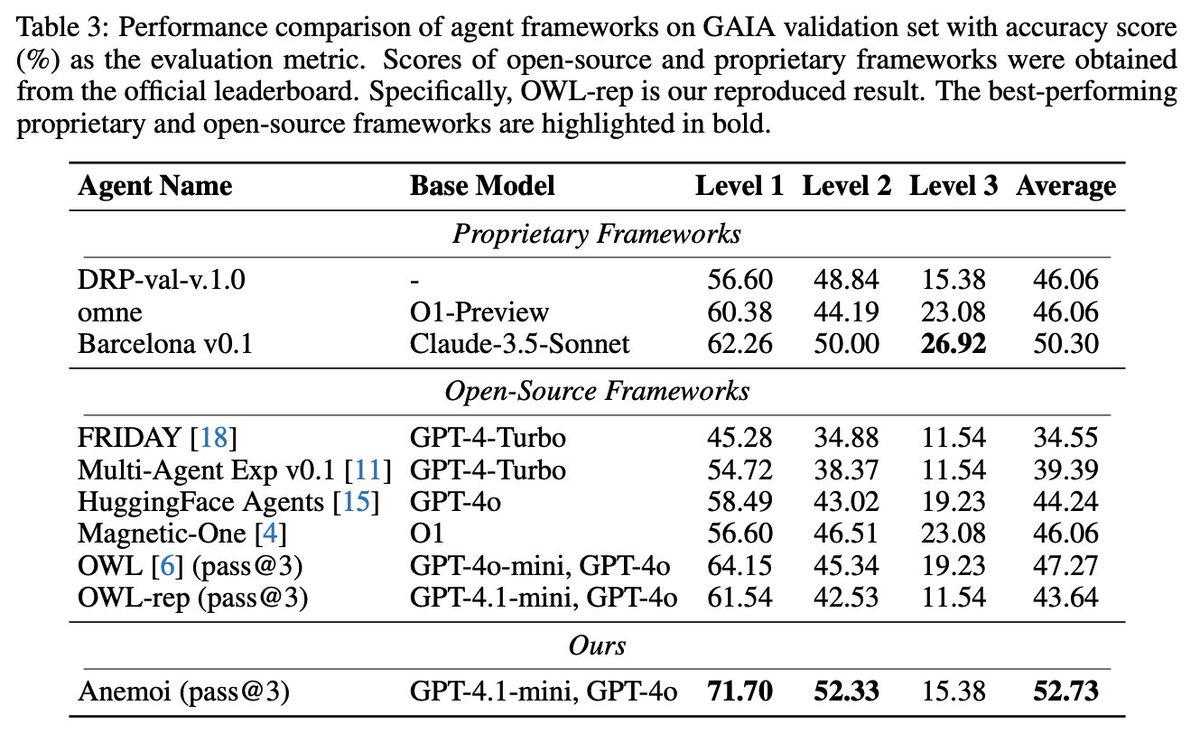
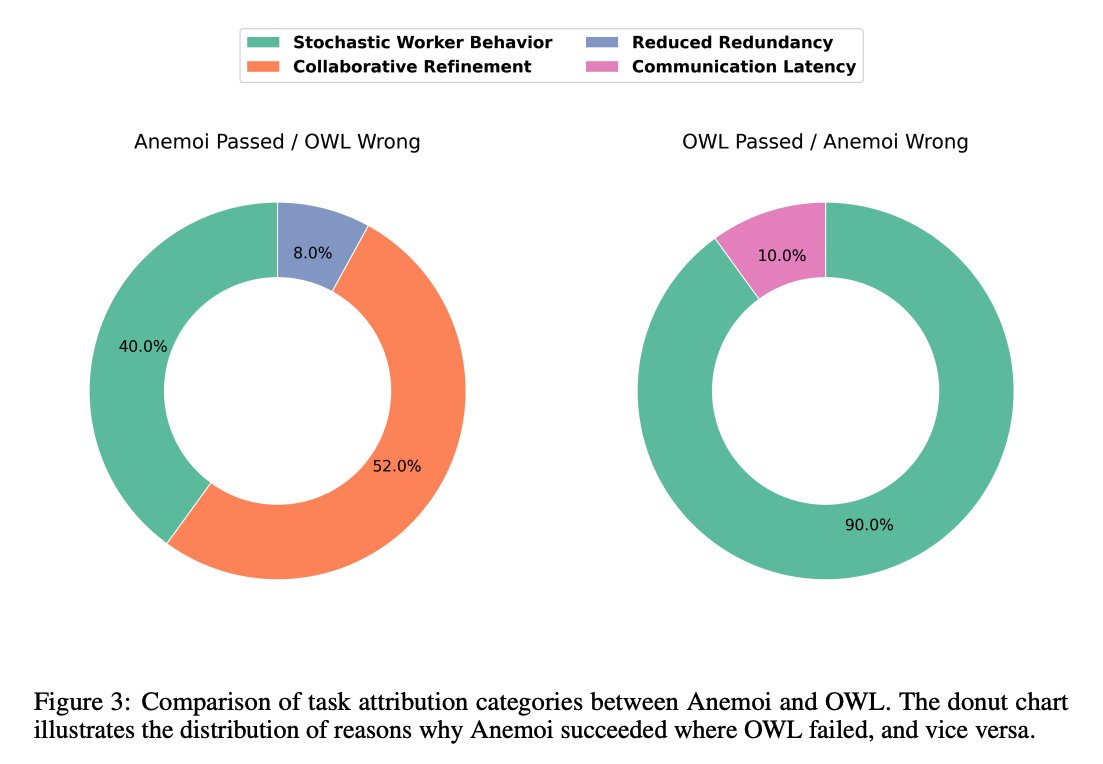
Results on GAIA With GPT-4.1-mini as planner and GPT-4o workers, Anemoi reaches 52.73% accuracy (pass@3), beating an OWL reproduction with the same LLM setup by +9.09 points and outperforming several proprietary and open-source systems that use a stronger planner. https://t.co/6kvZ6VjyZw
Why it wins Most extra solves over OWL come from collaborative refinement enabled by A2A (52%), with smaller gains from reduced context redundancy (8%). How agents collaborate is key to these strong results. OWL’s few wins over Anemoi largely stem from worker stochasticity and web-agent latency.
Paper: https://t.co/xfaycIHsM7 GitHub: https://t.co/TfCvVkmkvi

Do we need to be concerned about quickly-growing #AI companionship? 💡New on the CITP Blog: Emotional Reliance on AI: Design, Dependency, & the Future of Human Connection by postdoc @InyoungCheong, Quan Ze Chen, Prof @manoelribeiro, +Prof @PeterHndrsn https://t.co/cWpHMrOw5k https://t.co/57Zs2if37w


We’re thrilled that our own @itsclelia will be speaking at Vector Space Day, hosted by @qdrant_engine! Her talk, Vector Databases for Workflow Engineering, dives into workflow engineering: ⚡️ Workflow state management & persistency ⚡️ Long-term memory for LLMs and agents If you’re building RAG pipelines, agentic AI, or complex workflows, this session is for you. 📍 Berlin | 🗓️ 26 September 📍RSVP 👉 https://t.co/nLuQiSjIqM

Our user built an app and is now in the top 42 of the App Store https://t.co/rMAhDWcjJH
Our user built an app and is now in the top 42 of the App Store https://t.co/rMAhDWcjJH
@Nils_Reimers @cohere Join us for our Fall Cohort coming up in less than a month. EARLYBIRD deal here: https://t.co/C7zURt4OVp https://t.co/OjWQcPDvEk


@Nils_Reimers @cohere Join us for our Fall Cohort coming up in less than a month. EARLYBIRD deal here: https://t.co/C7zURt4OVp https://t.co/OjWQcPDvEk

We'll be hosting @Nils_Reimers (VP AI Search @Cohere) again this Fall. Here are some notes from his last talk, it'll be great to have him join us again. https://t.co/fLGD80kcBO

convinced @vig_xyz to make a course, did we make it clear its not about vibe coding https://t.co/UrhcJJlSHN https://t.co/juevDg2yQR

Going through notes from the awesome talks we've had so far this year. This one's from Manav Rathod from @glean https://t.co/BhCZexnP87

@glean Plenty more talks like this one coming up in the Fall. If you want to join us for RAG, here's 20% off for Cohort 4: https://t.co/C7zURt4OVp https://t.co/2BFGat5P98

