@omarsar0
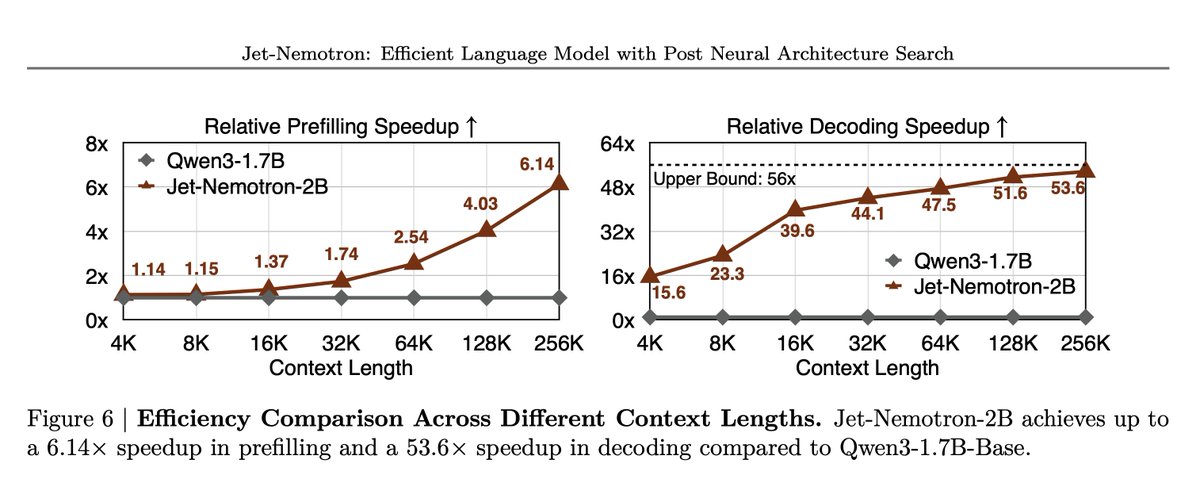
Results Jet-Nemotron-2B outperforms or matches small full-attention models on MMLU, MMLU-Pro, BBH, math, commonsense, retrieval, coding, and long-context tasks. All this while delivering up to 47x decoding throughput at 64K and as high as 53.6x decoding and 6.14x prefilling speedup at 256K on H100. Paper: https://t.co/rgTYY2q8WK