@omarsar0
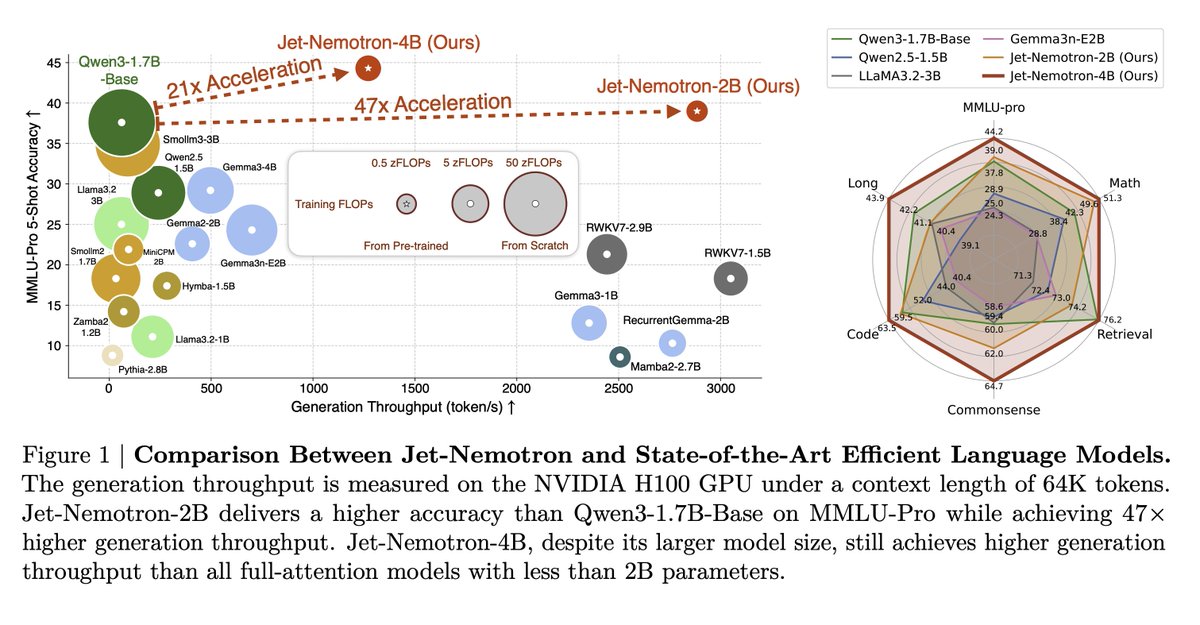
A hybrid-architecture LM family built by “adapting after pretraining.” Starting from a frozen full-attention model, the authors search where to keep full attention, which linear-attention block to use, and which hyperparameters match hardware limits. The result, Jet-Nemotron-2B/4B, matches or surpasses popular full-attention baselines while massively increasing throughput on long contexts.