@omarsar0
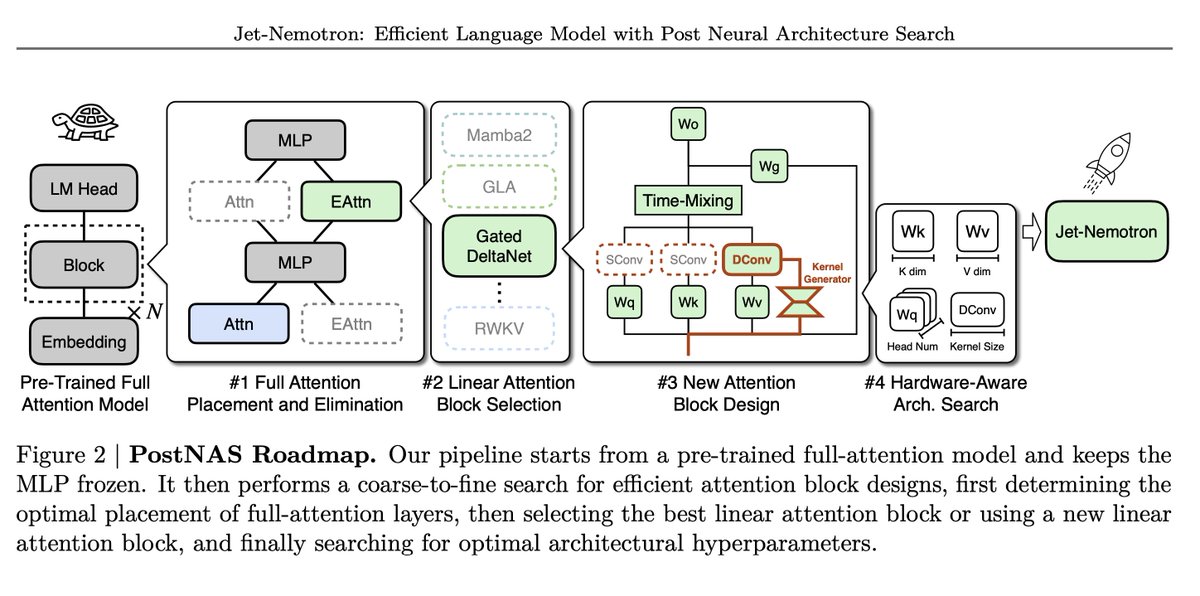
PostNAS pipeline Begins with a pre-trained full-attention model and freezes MLPs, then proceeds in four steps: 1. Learn optimal placement or removal of full-attention layers 2. Select a linear-attention block 3. Design a new attention block 4. Run a hardware-aware hyperparameter search