Your curated collection of saved posts and media
AI may reshape not just jobs, but the pathways between them. Millions of workers without degrees rely on “gateway” roles like admin or customer service to move into higher-paying jobs, yet many of these roles and the transitions they enable are highly exposed to AI. The real risk is not just job loss, but reduced mobility. If those stepping stones disappear, moving up the ladder could become much harder. https://t.co/Jnevx7SeSo @BrookingsInst

You can bring your kids' puzzles to life and expand their imagination with Grok Imagine. The new quality is awesome. https://t.co/1u3iKNot33
@karpathy Wow! There is so much interest in this. Months ago, I spoke on this idea in a live workshop. Access it for FREE for the next couple of days: https://t.co/wuoVfnU0Hr I am also hosting a live session on building LLM Knowledge Bases for your agents: https://t.co/1lx6hvPAcu https://t.co/DKE68EUs9F
The Little Robot’s Secret Garden🤖 Short story by Grok Imagine https://t.co/4JkvI5c6uh
Goodnight, 𝕏..·˚ ༘ ☾ ⋆。˚ ☄︎ Quality Mode in Grok Imagine is god-tier. Update your app. https://t.co/lvFF8QWOz2


Quality mode of Grok Imagine : Look at the details in the background https://t.co/vJ6l7wDXRj
🚨 BREAKING:Macron is TROLLING Trump at epic level 🔥 Macron: "When we are serious, we do not say the opposite of what we said the day before. Perhaps we should not speak every day." 😂 https://t.co/TX4BHmXMxr
Google is making a pragmatic shift to power its AI ambitions. Tapping a gas plant for a data center marks a departure from its climate goals, highlighting the massive energy demands behind AI infrastructure. The reality is becoming clear. Scaling AI requires energy at a level that is forcing tough trade-offs. https://t.co/qk8KGlzpPH

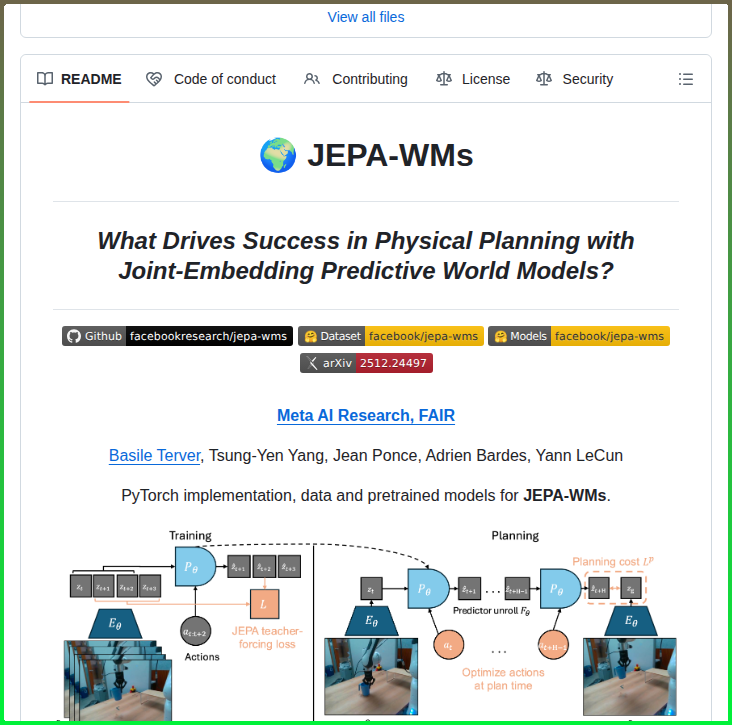
Joint-Embedding Predictive World Models for physical planning https://t.co/H9goxGvAEr https://t.co/LeVIaD9zqE
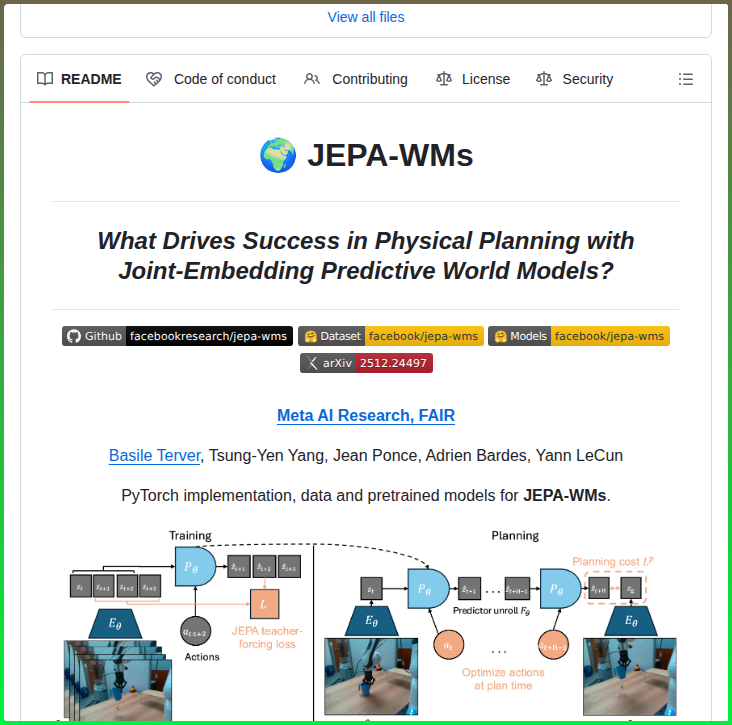

Joint-Embedding Predictive World Models for physical planning https://t.co/H9goxGvAEr https://t.co/LeVIaD9zqE

NVIDIA just released a quantized Gemma 4 31B on Hugging Face NVFP4 compression delivers 4x smaller weights with frontier-level accuracy. Runs on consumer GPUs with a 256K context window. https://t.co/WV916wLtin

Excited to share MaxToki, a temporal AI model that predicts the impact of perturbations on cell states over time along dynamic trajectories. We applied MaxToki to predict how cells age across the human lifespan & discovered new cardiac pro-aging drivers that we validated in vivo. https://t.co/u7MDjGmSYT

Most people still think AI is just a tool. They're missing the bigger picture. When AI agents start collaborating... That's when we unlock TRUE potential. @AgenteseAI gets it. Be early. 🚀 #innovation #AI #aiagents https://t.co/Xkh4zSjZw6
🙏 A heartfelt thank you to our #PyTorchCon Europe diamond sponsor Meta. Europe's #AI community is converging in Paris 7-8 April for deep dives into GenAI, #agentic systems, infrastructure, & expert keynotes. Register: https://t.co/Q9AWqAyojY Schedule: https://t.co/CxzsvxwXHx https://t.co/viuiaFaxsv


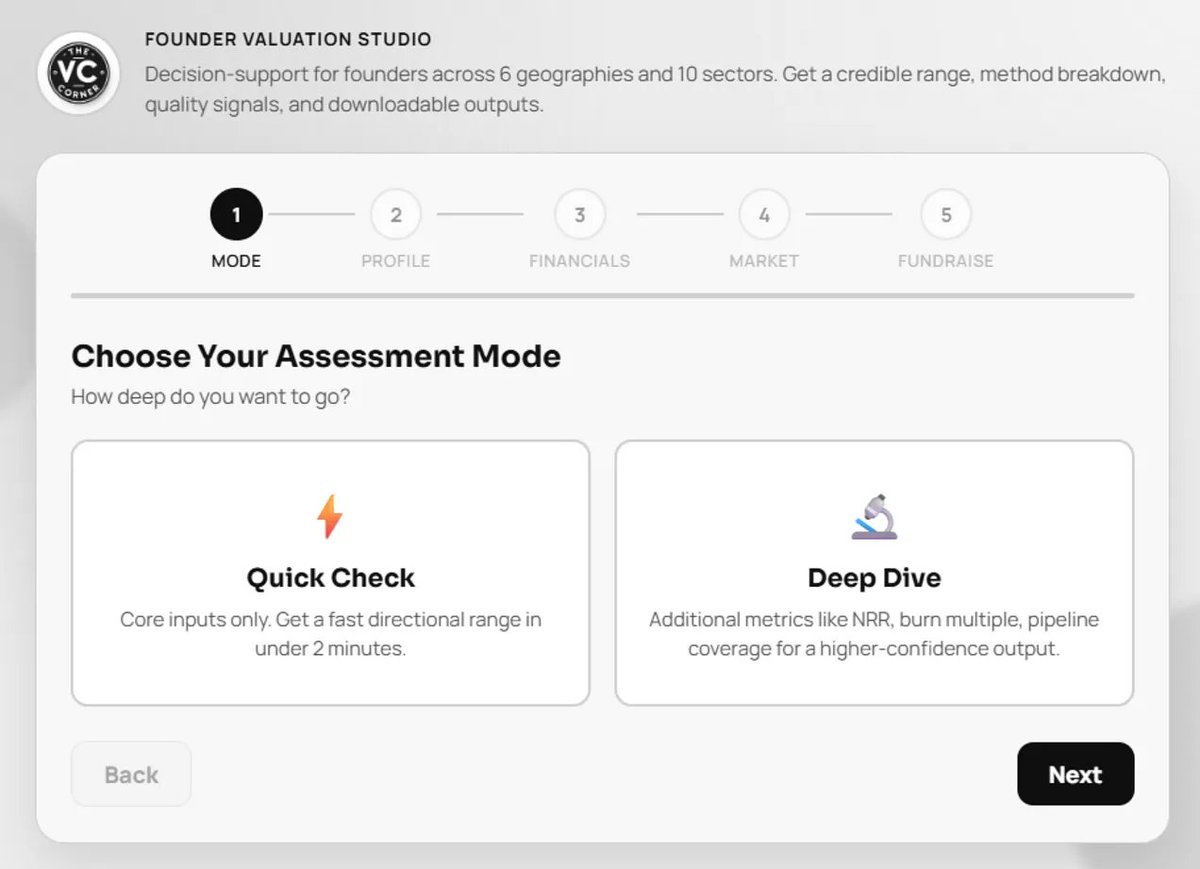
Just built a VALUATION TOOL for founders💰 and it might be the most useful thing in your data room ACCESS IT HERE: https://t.co/VAyVQSmFyW https://t.co/AhKv7S9XQl
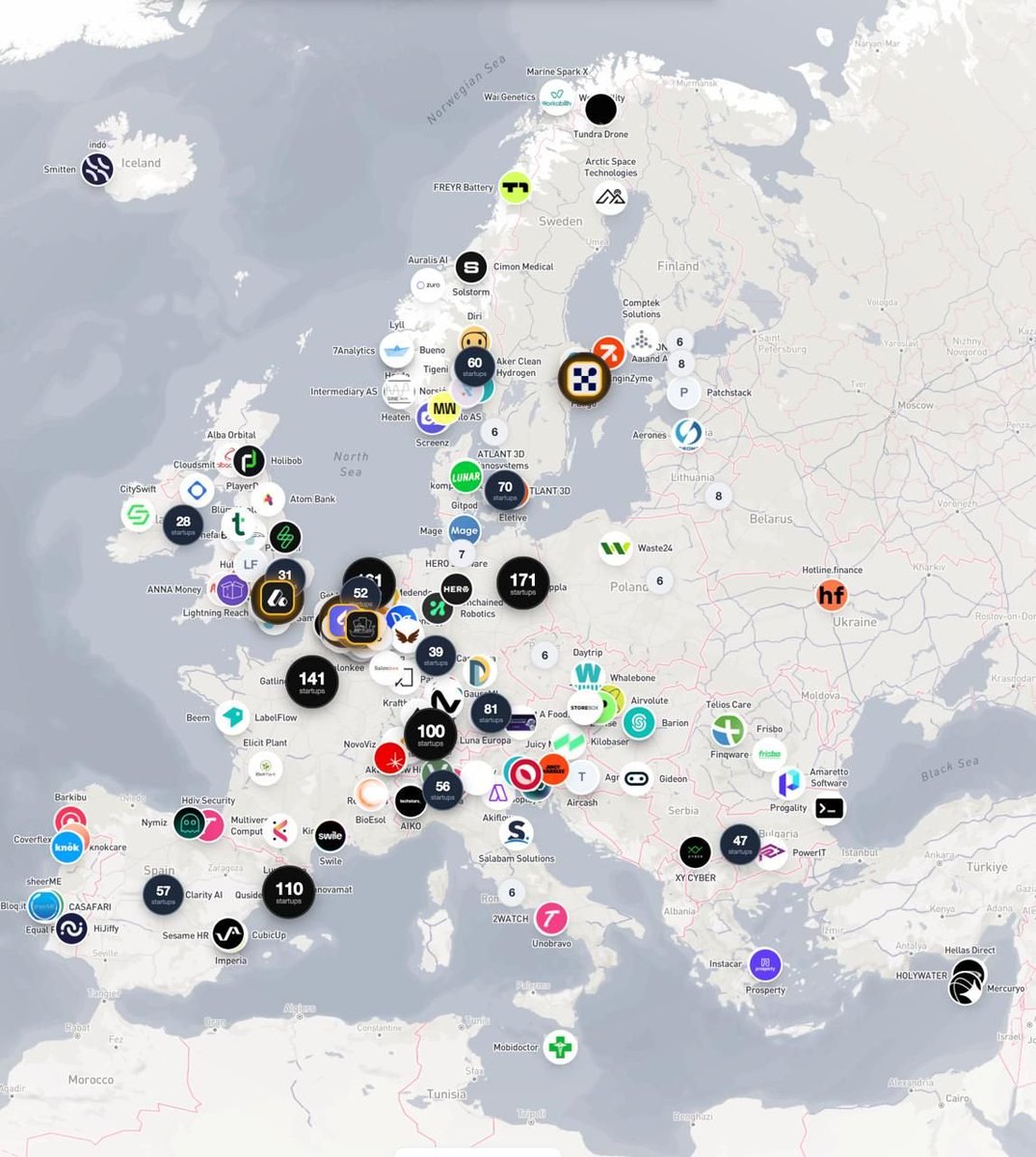
There are over 3.5k job openings at Europe's leading startups. Tech is the fastest growing segment of the European economy, and it is quickly overtaking finance and law as the most in-demand grad jobs. There's never been a better time to get into tech with some amazing jobs at some of the fastest growing startups across europe: > @attio > @synthesiaIO > @fuseenergy > @peec_ai Jan-Willem Denys has built StartupMap - a new platform tracking the continent's open roles and there are some great roles out there. It's a great resource - will drop the link below
🎉 BIG NEWS! Our AI agents just got an upgrade. Video conversations are now LIVE. Yes, YOU can talk to your AI face-to-face. This changes everything. Who else is excited? 👇 #AIAgents #VideoChat #GameChanger #Ai https://t.co/Wdp86nekBQ
New Grok is so fine https://t.co/b1kMkPFSMt
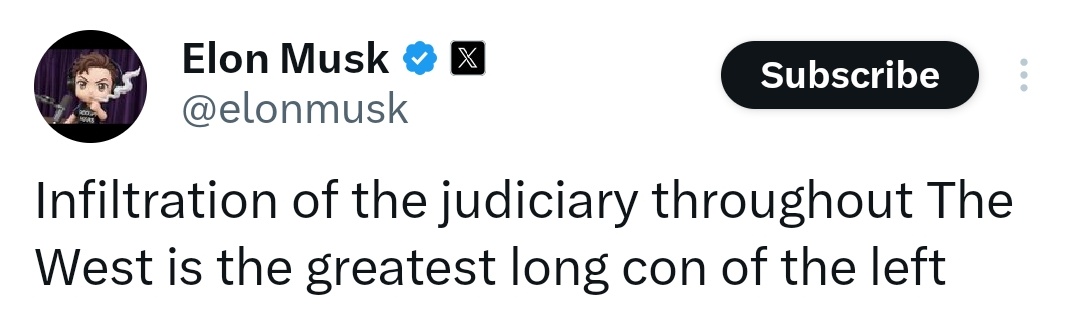
ELON MUSK: "Infiltration of the judiciary throughout the West is the greatest long con of the left." https://t.co/u5iZRKCAwo
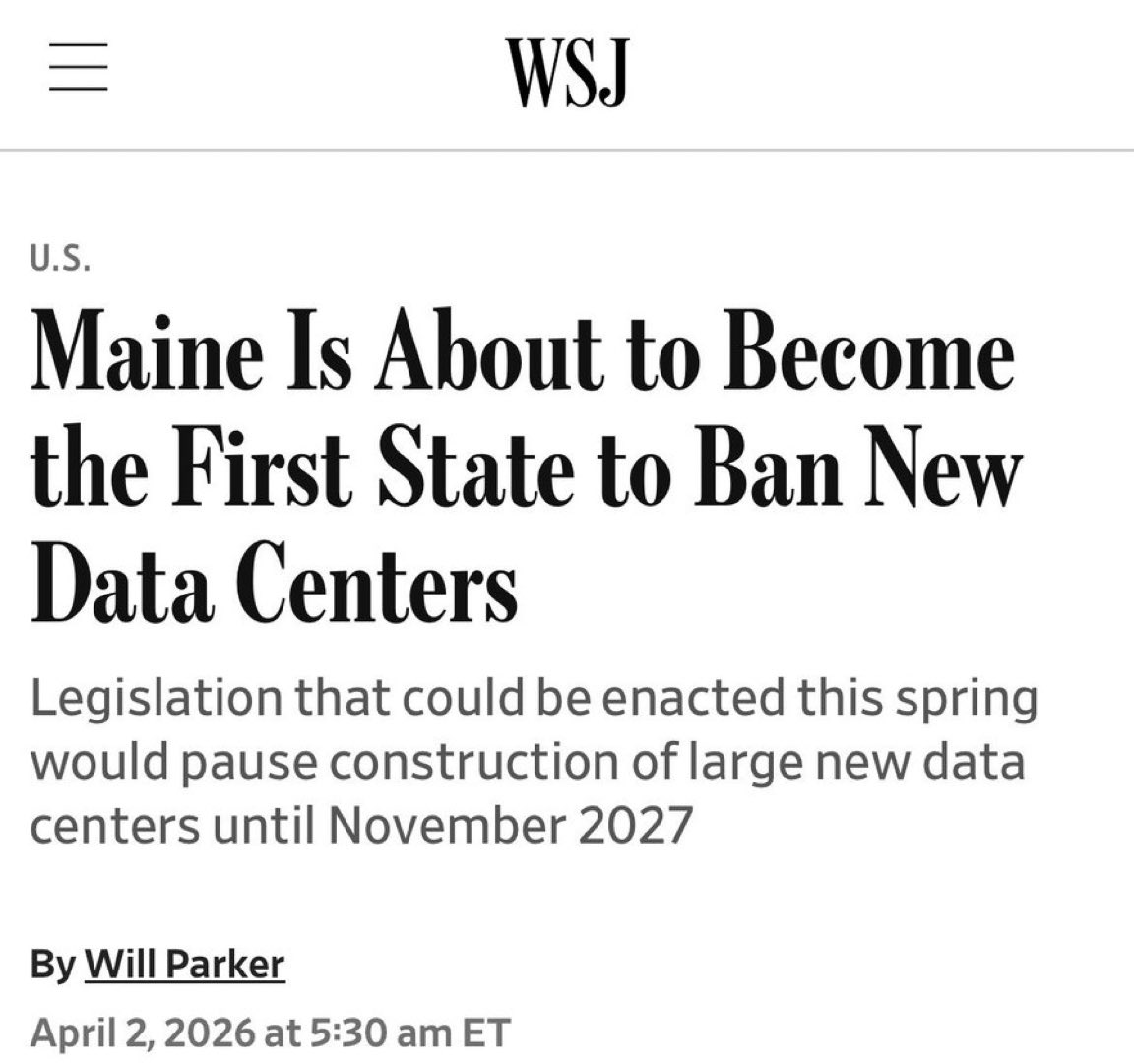
They may be onto something with this space based data center thing https://t.co/W71Z1Uqxpq
Rain on me 🌧️ https://t.co/E9Puhx0wGy
Grok Imagine https://t.co/7yDgTOeISO
New “Quality Mode” in Grok Imagine is absolutely stunning! The crispness and clarity are beautiful. https://t.co/x0ga79RsdU
Your Even G2 just unlocked new possibilities. Download your favorite apps or build your own. Even Hub is now live in the Even Realities App via firmware update. #EvenRealities #EvenHub https://t.co/PuwFSgOmle
🤠 Hats off to our #PyTorchCon Europe diamond sponsor Red Hat. Join us for two exciting days in Paris from 7-8 April for keynotes, workshops, & focused tracks on #GenAI, frameworks, compilers, security, & MORE! Register: https://t.co/Q9AWqAyojY Schedule: https://t.co/CxzsvxwXHx https://t.co/AZKh2ApCqM


Cursor is stepping into a more competitive phase of AI coding. With its new agent-based experience, the company is moving closer to the territory of tools from OpenAI and Anthropic, where AI does not just assist but actively writes and executes code. The space is evolving fast. AI coding is shifting from support tools to autonomous builders. https://t.co/DeFWQPUqP1 @wired
