Your curated collection of saved posts and media
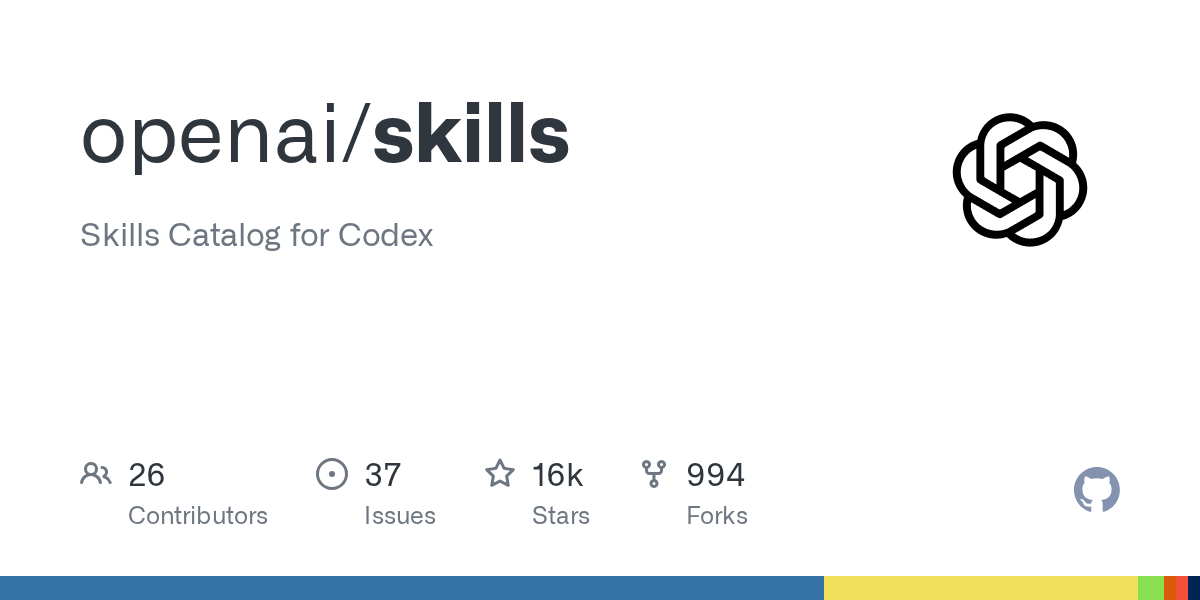
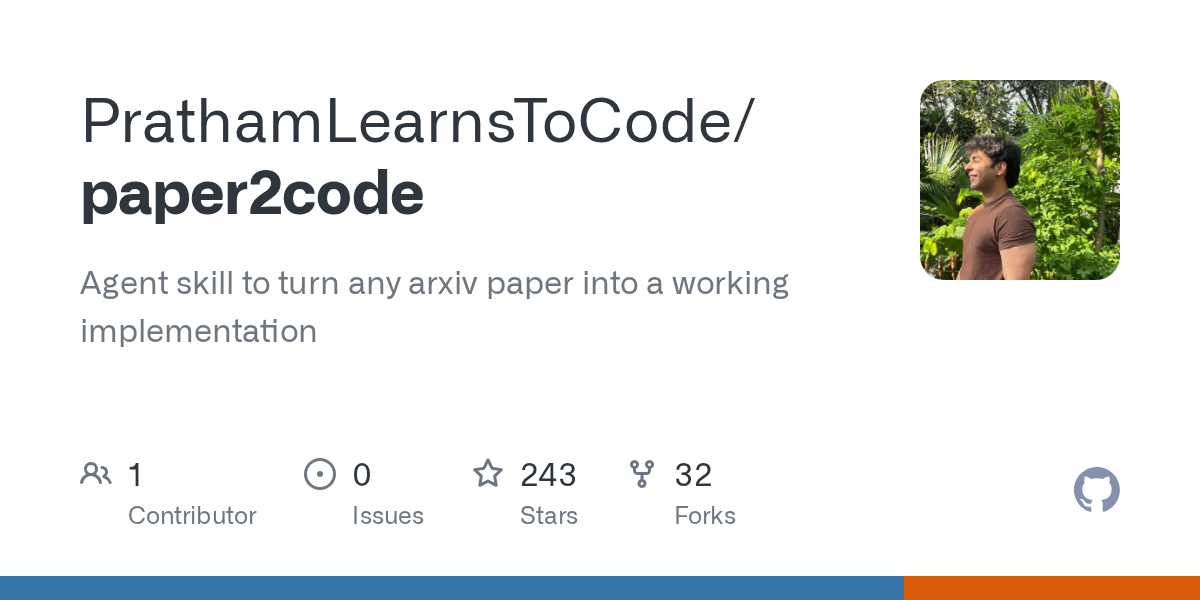
I made a Claude Code skill that turns any arxiv paper into working code. Every line traces back to the paper section it came from & any implementation detail the paper skips will be flagged, and not assumed. open sourcing it - https://t.co/sSio4JfpIo https://t.co/5XqlGgQsqC
I have so many questions it’s broth in a teabag? https://t.co/xx9mGQd4bl

You can now send Bitcoin transactions without internet A live $BTC transaction was broadcast using mesh radio at the BOSS Summit, completely off-grid This is what censorship resistant money actually looks like. 🎥: @bala_1116 https://t.co/o8mIJNEnSD


@effiebio @bryancsk I tried it, for a while I thought it was an April fools joke, because I blew on several with no luck and much straining 😂 some compressed air finally did the trick: https://t.co/reiayv2IDK

Microsoft says Copilot is for entertainment purposes only, not serious use — firm pushing AI hard to consumers tells users not to rely on it for important advice https://t.co/SxtS4xSPmC

Your Saturday Ai news: https://t.co/kiuZ7QXLzb I built this to be way better than the algorithm. It is a new way to read X’s AI world. If you get value from this let me know.

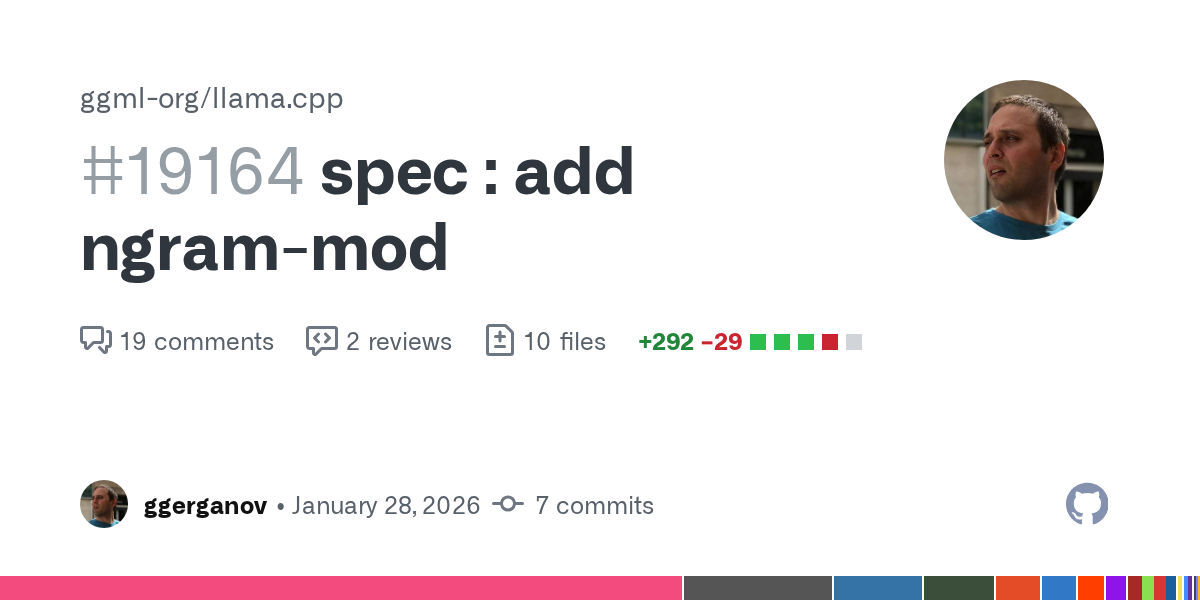
The example below is using prompt-based speculative decoding. Specifically, ngram hashing is utilized to suggest drafts of up to 64 tokens. The hasher keeps track of ngrams in the observed contexts, so mostly effective for coding tasks. Here is another demo: https://t.co/LXkWNO3GaR
Let me demonstrate the true power of llama.cpp: - Running on Mac Studio M2 Ultra (3 years old) - Gemma 4 26B A4B Q8_0 (full quality) - Built-in WebUI (ships with llama.cpp) - MCP support out of the box (web-search, HF, github, etc.) - Prompt speculative decoding The result: 300
The parameters that I used are the same as in the PR that introduced this functionality in llama.cpp: https://t.co/PGNQsIjG1V
Gemma 4 just landed on the edge on Workers AI! 💎 MoE model with 26B and 4B active, for fast inference 💎 Tool calling, reasoning, vision capabilities. Generates code and is multilingual 💎 256k context window and Chat Completions compatible API 💎 Perfect for building fast agents https://t.co/o16HAonK9D

gemini 3.1 pro read the whole 500+ page pdf and then started answering stuff like a champ in ~30s after thinking. I'm really impressed by how good the app and model is sometimes. https://t.co/kAr0WUB1JL
So... I think my janky DIY gene gun works!? The red dots are (I hope) RUBY genes shot into plant tissue with an airsoft gun. Now lots of work to validate and improve and document 😁 Notes: https://t.co/HIQyhASDmW https://t.co/LgHg3s7Q80

Roger Scruton, the ancestor duty https://t.co/935dx35cLC

Roger Scruton, the ancestor duty https://t.co/935dx35cLC

Howard Marks: "When you buy the S&P 500 at a 23x P/E, your 10-yr annualized return has always fallen between +2% and –2%, IN EVERY CASE, EVERY CASE!" https://t.co/v9xUf9inNK
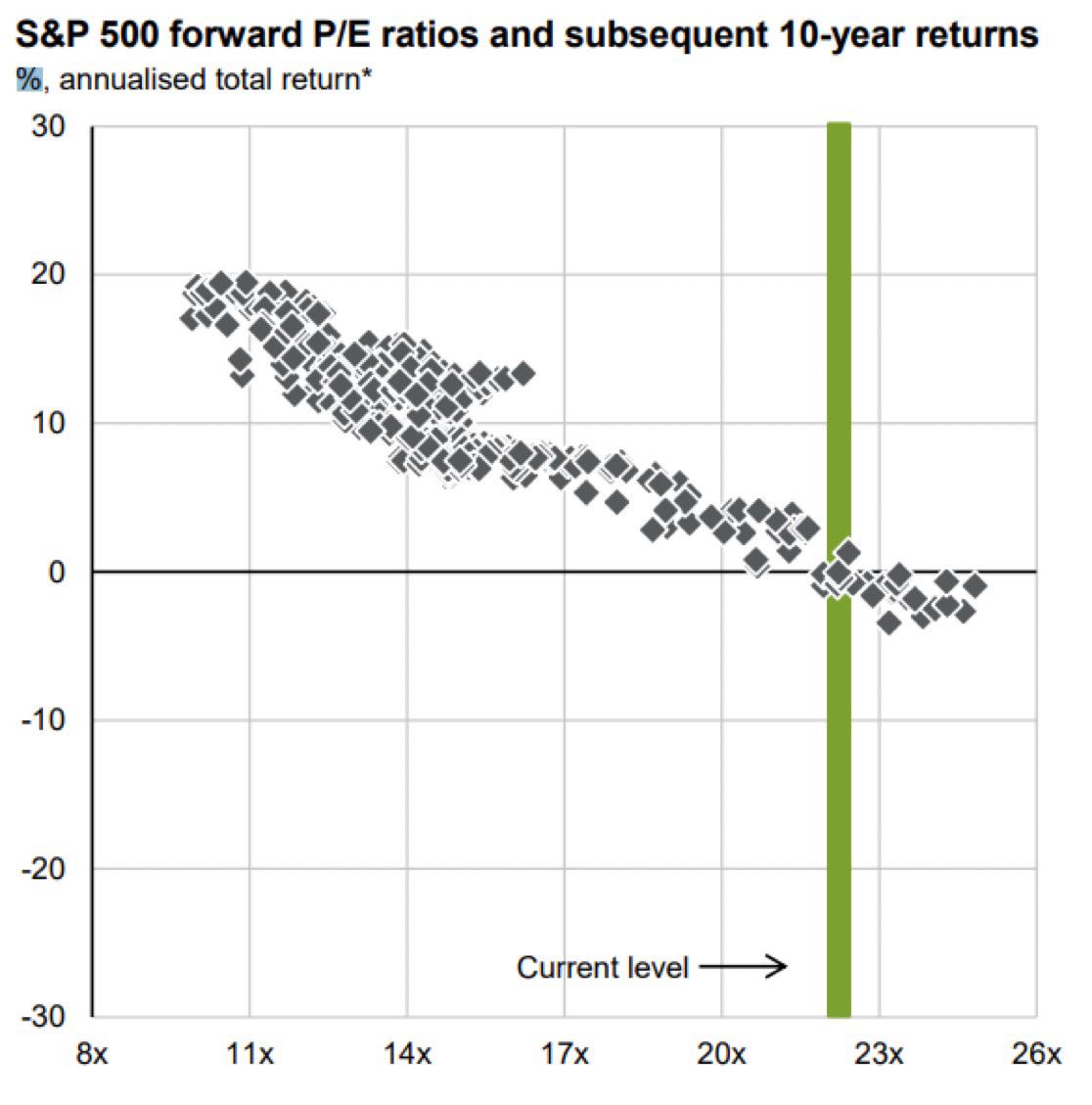
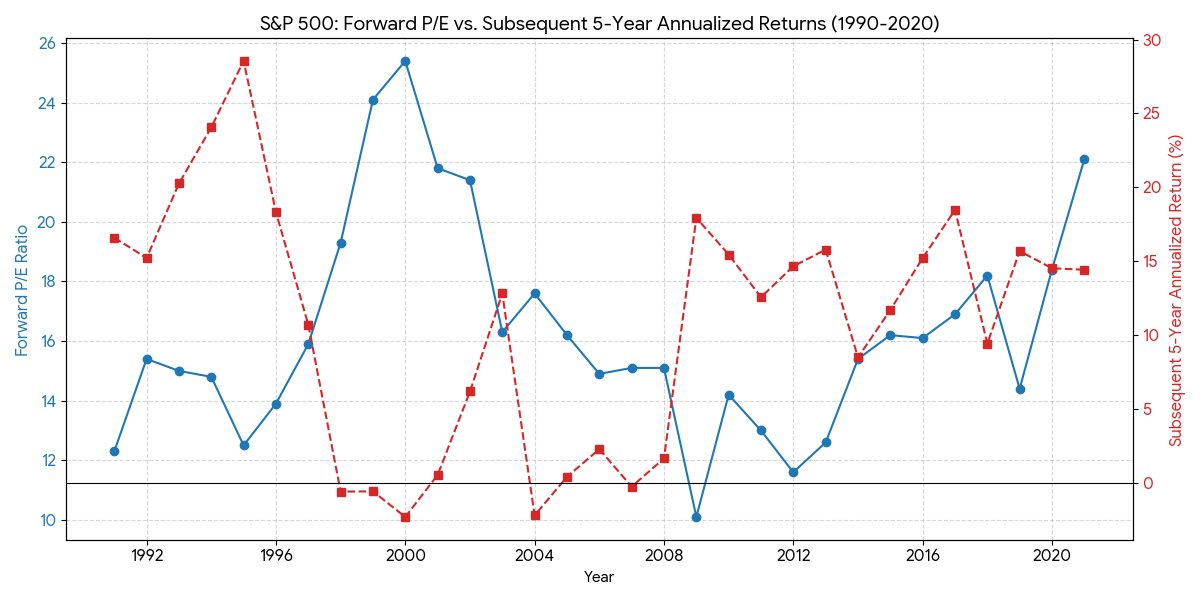
Every chart crime has a corresponding "correct" data visualization that pretends the same information in an unbiased way. Below: a quarterly timeseries of SPX forward PEs and annualized 5-year forward returns (note: this is 5 year instead of 10 because that's what I wanted to look at) Right now the SPX forward PE is 19.8x. Here are the closest tuples to this value, historically: Q4 1997: 19.3x ➡️ -0.6% Q4 2000: 21.8x ➡️+0.5% Q4 2001: 21.4x ➡️+6.2% Q4 2017: 18.2x ➡️+9.4% Q4 2019: 18.4x ➡️+14.5% Q4 2020: 22.1x ➡️+14.4% The inverse correlation between forward PE and future returns is real, but it is weak and you absolutely cannot infer that future returns from now on will be low or negative
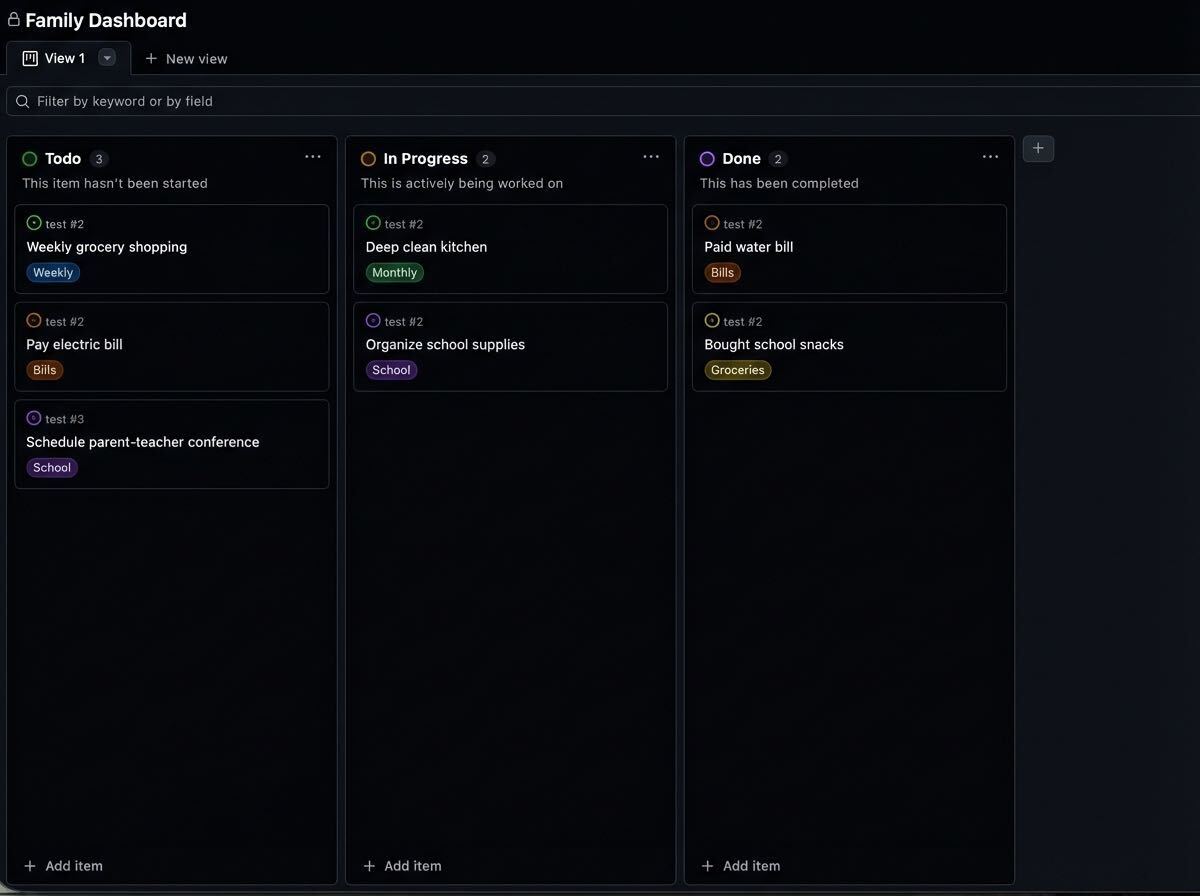
GitHub powers your code, but it can also power your daily life. 🔋 Instead of downloading another productivity app, manage your tasks right where you already work: ✅ Issues for chores and bills 🏷️ Labels for priority and status 📊 Projects for your daily schedule Here’s how to set up your personal operating system. 👇 https://t.co/WsO5Zwpb5C
Dr. Oz: “We have shut down just in the last ten weeks 221 hospices.” Bret: “Wait, over 220 in the state of California?” Dr. Oz: “Yes, in Los Angeles alone.” https://t.co/AyBaNchqdg
@itsjessyin @claudeai https://t.co/nW4oVK5Jxo
Another day more personal software in @GoogleAIStudio :) https://t.co/2w3TM3BqRS
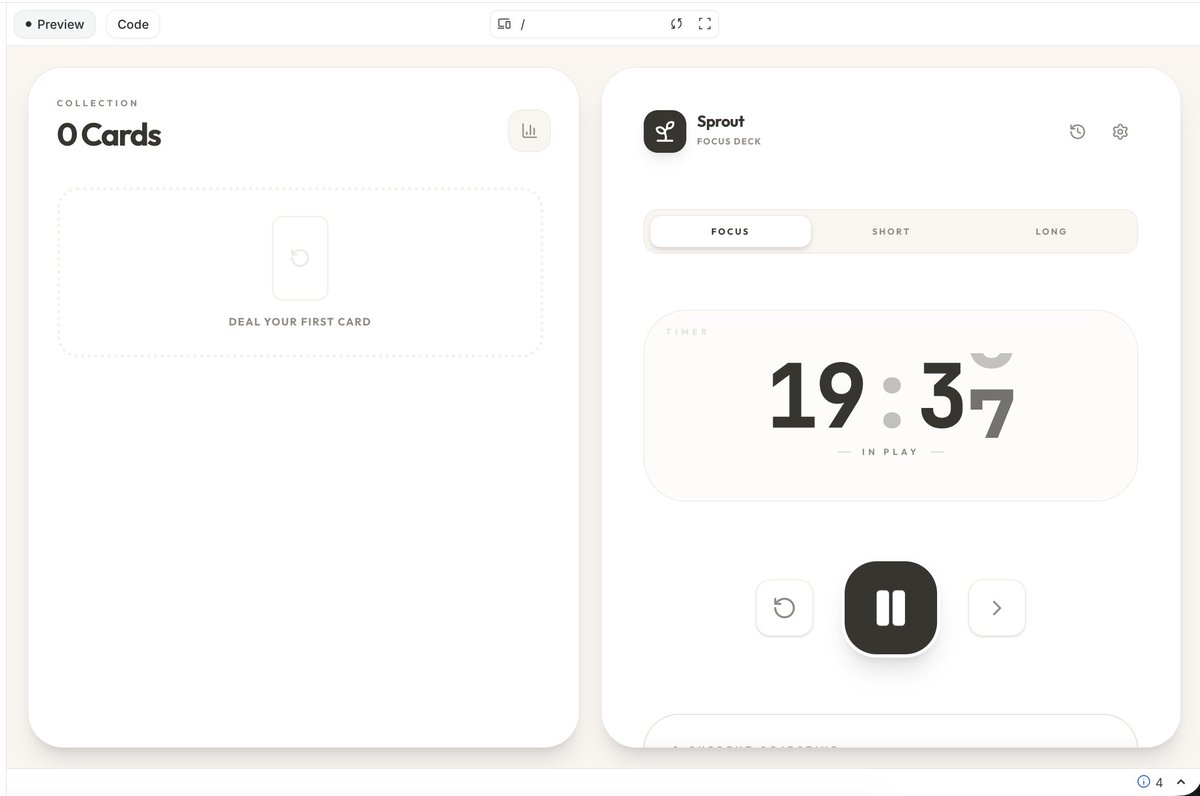
Been a bit all over the place, built a new pomodoro app in my own os in @GoogleAIStudio :) All state is stored locally for this since it's for me to focus when I have a session https://t.co/SNzYSngpTj
Your Saturday Ai news: https://t.co/kiuZ7QXLzb I built this to be way better than the algorithm. It is a new way to read X’s AI world. If you get value from this let me know.

If anyone has a watch guy. I’m willing to pay a 5-8% fee if someone can secure me this watch, not a link. But I need to be able to actually buy it. https://t.co/hDQ622vYrG


This app is free but it cost us everything @trq212 https://t.co/UPeyFd4wa4
https://t.co/y9abbyAdlH
@jxnlco just put the codex in the bag Jason

@howwardroark https://t.co/9Je8Ff0EK1

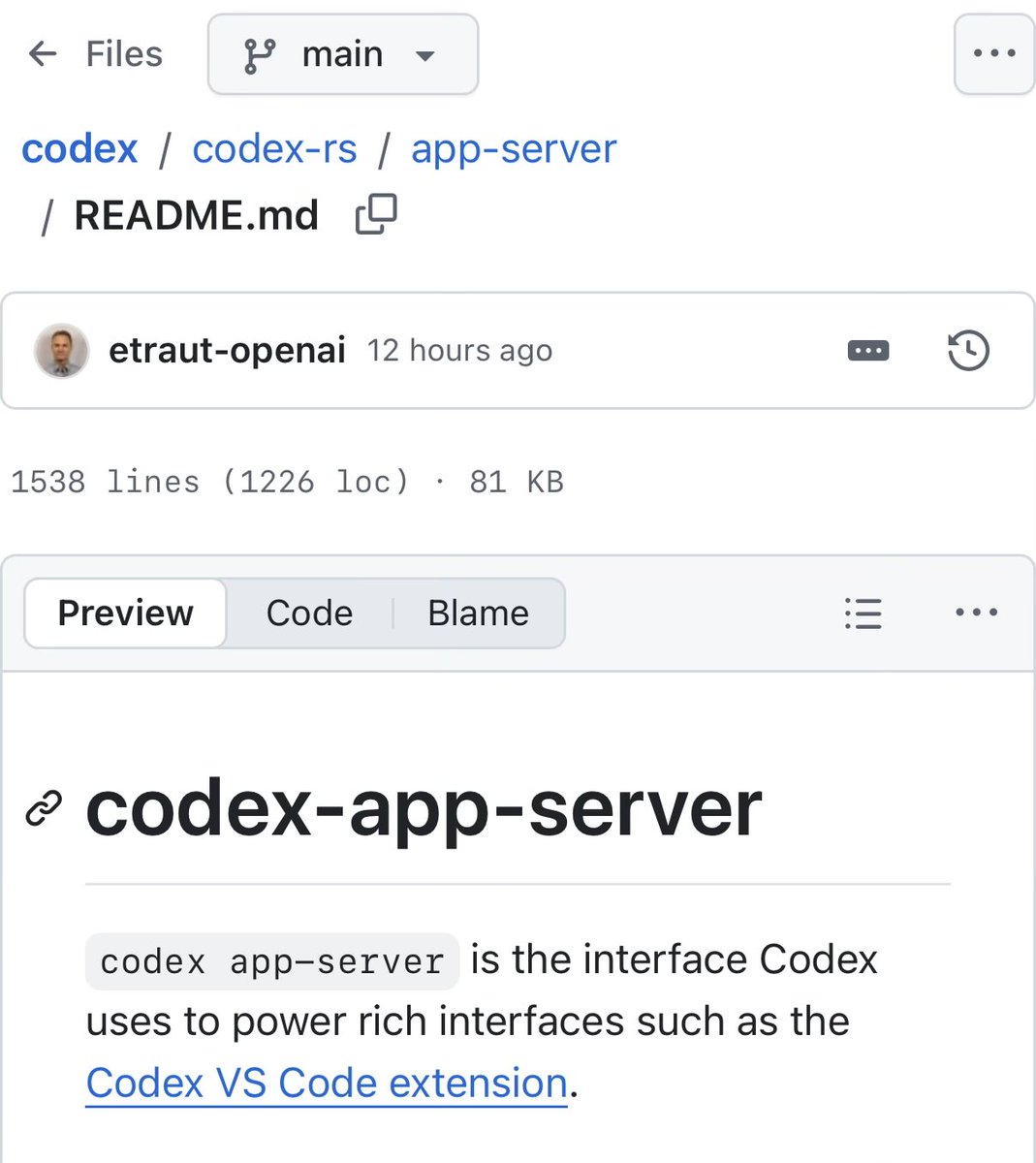
ICYMI: you can use your ChatGPT sub with OpenClaw, OpenCode, Pi, Cline and a lot more! Infact you can double down and build your own interfaces on top of the ChatGPT Sub via the Codex App Server too - it’s fully open source Enjoy your Claw & build things you want, when you want https://t.co/plmgnV07Gy
Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw. You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
? https://t.co/0BPmPrkusc

Wow, this tweet went very viral! I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs. So here's the idea in a gist format: https://t.co/NlAfEJjtJV You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating know

The Waymo World Model is built upon Genie 3 : Google DeepMind's most advanced general-purpose world model that generates photorealistic and interactive 3D environments and is adapted for the rigors of the driving domain. By leveraging Genie’s immense world knowledge, it can simulate exceedingly rare events—from a tornado to a casual encounter with an elephant—that are almost impossible to capture at scale in reality ▶️ #AI #SelfDrivingCars https://t.co/QB7RiTh7NB
Monkey business lately https://t.co/tBMs8nxaUd


Startup funding has hit an unprecedented level. Global investment reached $297 billion in Q1 2026, a 2.5x jump from the previous quarter and more than entire years of venture funding before 2019. The scale signals something bigger than a cycle. Capital is accelerating into what many see as a once-in-a-generation technology shift. https://t.co/vAbj8hu5jv @MTemkin @techcrunch

@PaulSolt yeet https://t.co/US12B4WwcZ