@llama_index
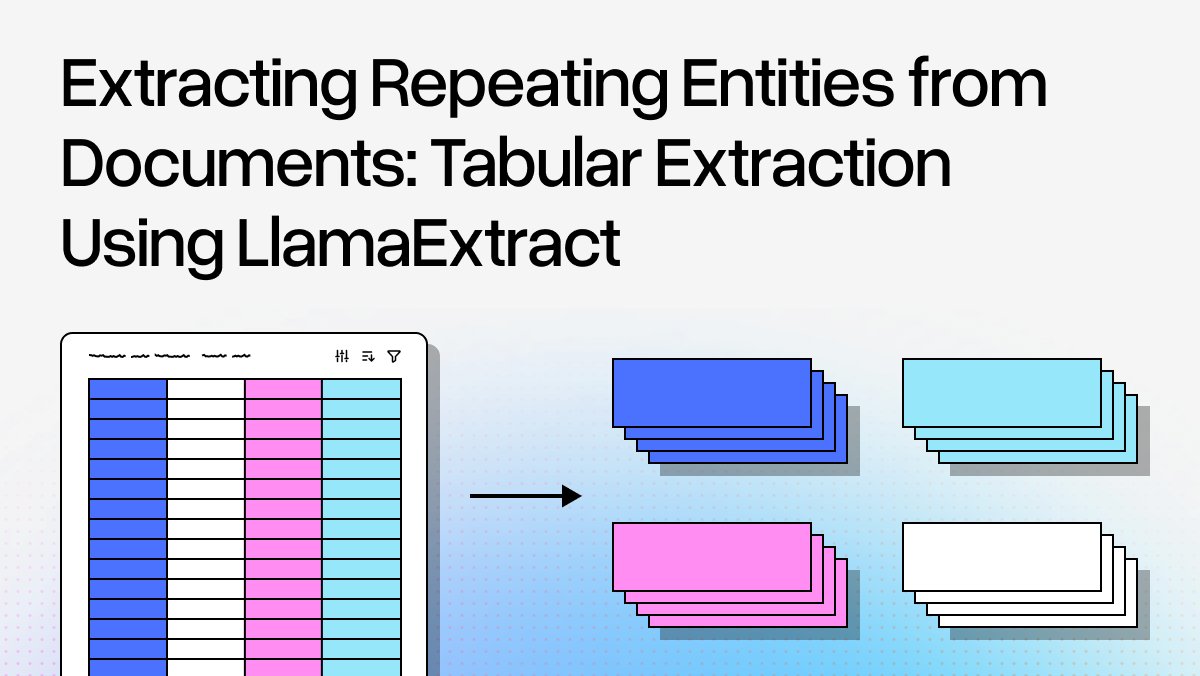
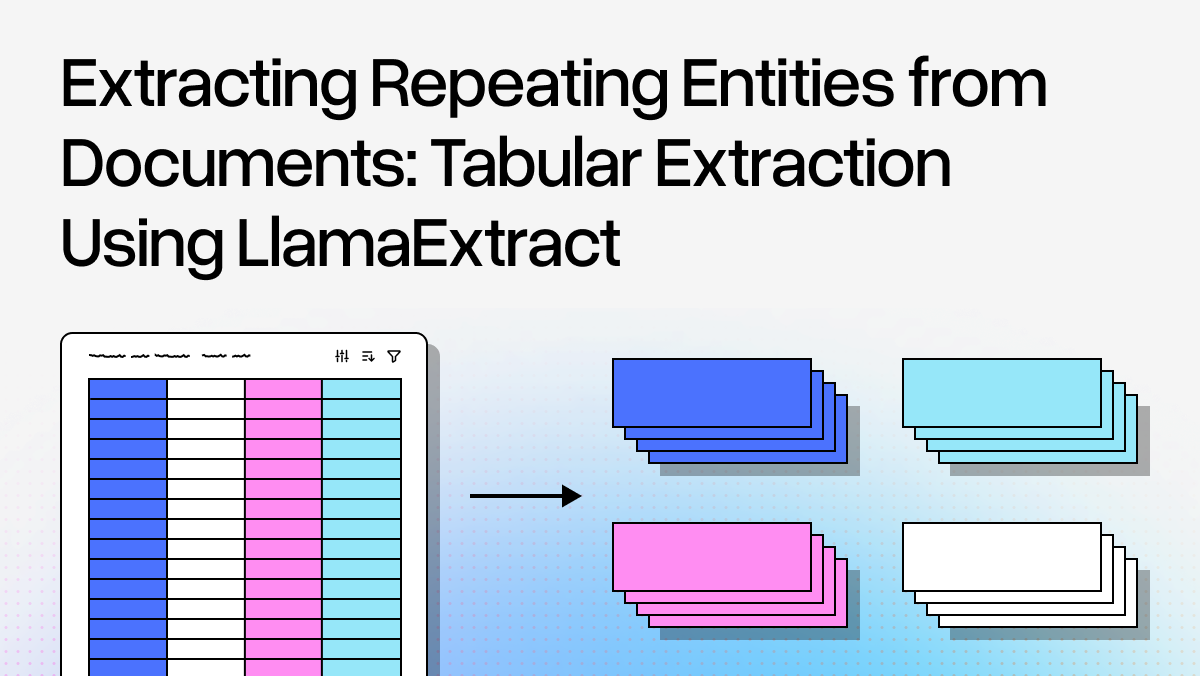
Stop losing 80% of your data when extracting from long documents with repeating entities like catalogs, tables, and lists. Our new Table Row extraction target in LlamaExtract solves the core problem: instead of trying to extract everything at once (where LLMs get overwhelmed), we intelligently segment documents and extract entity by entity. 🎯 Long multi-page insurance directory? Extract all 380 hospitals (vs. only 40 with document-level extraction) 📋 Handle both formal tables and semi-structured content like product catalogs automatically 🔍 Define your schema for a single entity - we return the complete list with exhaustive coverage ⚡ Leverage LLM flexibility while achieving template-based reliability through smart segmentation This approach identifies repeating patterns, segments documents at natural boundaries, then applies your schema to focused chunks. Works with tables, lists, catalogs, or any document with distinguishable repeating entities. Read the full technical breakdown with code examples here: https://t.co/Zrghh3ZZ7N