@TencentHunyuan
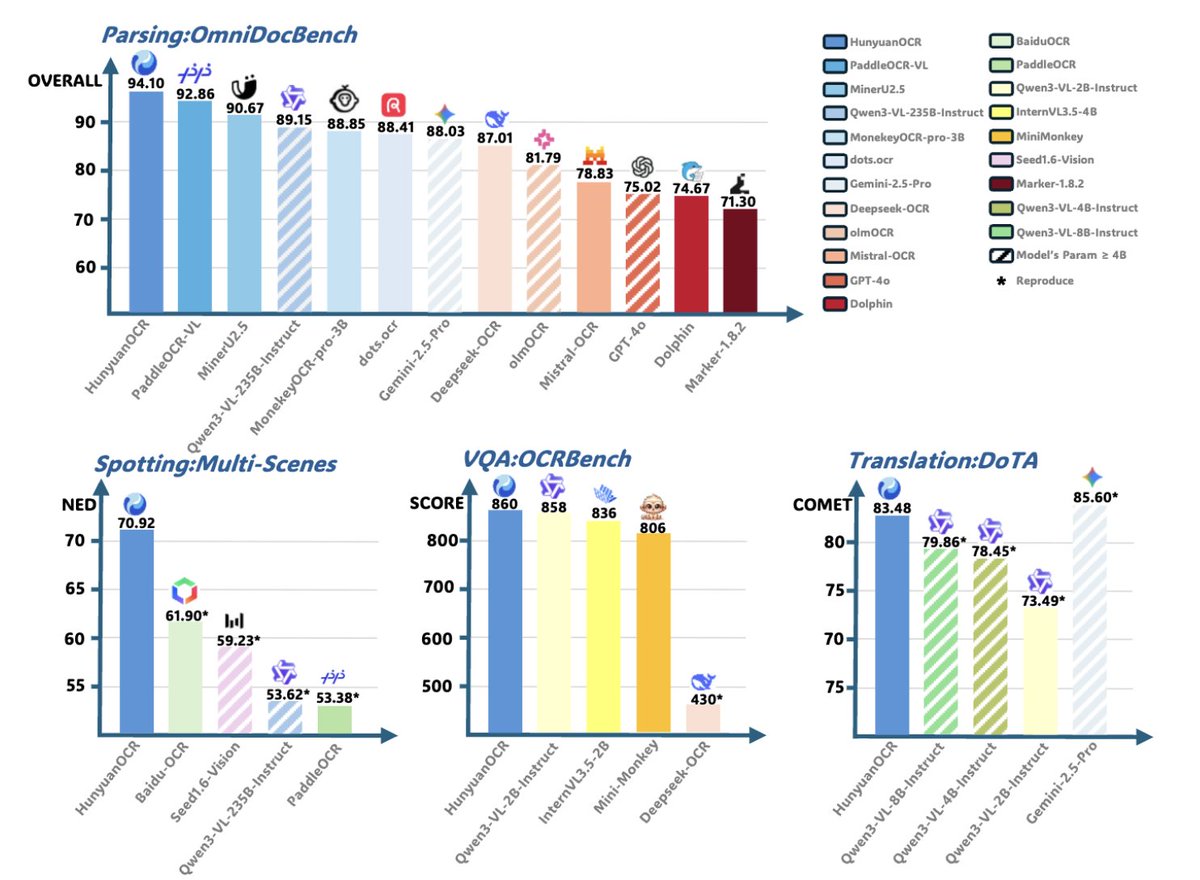
We are thrilled to open-source HunyuanOCR, an expert, end-to-end OCR model built on Hunyuan's native multimodal architecture and training strategy. This model achieves SOTA performance with only 1 billion parameters, significantly reducing deployment costs. ⚡️Benchmark Leader: Achieves a SOTA score (860) on OCRBench for models under 3B parameters and a leading 94.1 on OmniDocBench for complex document parsing. 🌐Comprehensive OCR Capabilities: Extends beyond simple text recognition to handle text spotting (street view, handwriting, art text), complex document processing (tables/formulas in HTML/LaTeX), video subtitle extraction, and end-to-end Photo translation (supports 14 languages). ✅Ultimate Usability: Embraces the "end-to-end" philosophy and achieves top-tier results with a single instruction and single inference, providing superior efficiency over traditional cascade solutions. 🌐Project Page: https://t.co/7UsMcJKhwu (web) https://t.co/mKjgjV9kwX (mobile) 🔗Github: https://t.co/MLrOnBpZBg 🤗Hugging Face: https://t.co/rZqdeZnHav 📄Technical Report: https://t.co/E4OhxV0Djw